DeepSeek V4 API Python: Ejemplos de Código Mínimos con Streaming

I’ll translate this article to Spanish. Let me start by translating the content while preserving all markdown formatting, URLs, code blocks, and technical terms.
¡Hola a todos! Soy Dora. Todo comenzó con una pequeña irritación: seguía copiando el mismo boilerplate de chat-completion entre proyectos, cambiando URLs base y nombres de modelos como etiquetas en frascos. No es trabajo difícil, solo el tipo que agrega fricción a tu día. Había estado viendo a DeepSeek aparecer lo suficiente como para sentir curiosidad, así que aparté algunas mañanas a finales de enero de 2026 para conectar su API “V4” en mi stack de Python y ver cómo se sentía en uso real.
No estaba persiguiendo benchmarks. Quería saber: ¿el cliente se mantiene fuera de mi camino?, ¿puedo hacer streaming de manera confiable?, y ¿los errores fallan de una manera que sea fácil de razonar? Aquí está lo que intenté, lo que me atropelló, y lo que funcionó tranquilamente. ¡Vamos!
Configuración del Entorno
Dependencias
Mantuve la configuración simple en macOS con Python 3.11. Puedes hacer esto con la biblioteca estándar, pero tres pequeños paquetes hicieron la vida más fácil:
- requests (HTTP directo: suficientemente bueno para la mayoría de los casos)
- httpx (async y timeouts que se comportan bien)
- python-dotenv (para que no pegue claves por ahí)
 Si planeas hacer streaming con Server-Sent Events, puedes usar requests y analizar líneas tú mismo (lo que hice), o traer un ayudante como sseclient-py. Me mantuve con requests, menos partes móviles.
Si planeas hacer streaming con Server-Sent Events, puedes usar requests y analizar líneas tú mismo (lo que hice), o traer un ayudante como sseclient-py. Me mantuve con requests, menos partes móviles.
Instalación
pip install requests httpx python-dotenvTambién creé un entorno virtual mínimo por proyecto. Es consejo aburrido, pero te salva de la deriva de dependencias cuando revisitas esto en tres meses.
Configuración de Clave API
Almacené la clave en una variable de entorno. Nada especial:
# .env
DEEPSEEK_API_KEY=your_key_hereLuego en Python:
from dotenv import load_dotenv
import os
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not API_KEY:
raise RuntimeError("Missing DEEPSEEK_API_KEY")Dos pequeñas notas de configuración:
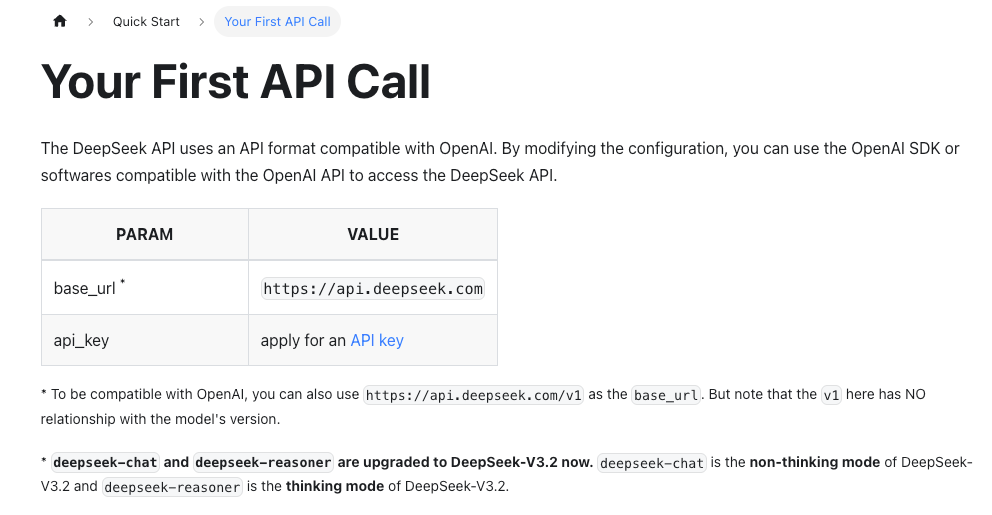
- La URL base y los nombres de modelos cambian más a menudo de lo que piensas. Revisé la documentación oficial de la API de DeepSeek antes de cada ejecución para confirmar rutas y modelos disponibles.
- Mantuve timeouts explícitos. Es un hábito que se paga una vez que alcanzas límites de tasa o ruido de red.
Solicitud de Chat Básica
El modelo mental es familiar si has usado chat-completions en otro lugar. DeepSeek expone un endpoint de chat con messages=[{"role": "...", "content": "..."}]. Eso es útil porque no tuve que reformular mis prompts.
Aquí está la solicitud mínima que usé con requests. Los nombres de modelos varían según la cuenta y la región, durante mis pruebas vi referencias como deepseek-chat y deepseek-reasoner. Si tu documentación menciona una cadena de modelo “V4”, úsala. De lo contrario, elige el modelo de propósito general más cercano listado en tu consola.
import os
import requests
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat", # check docs/console for the exact model
"messages": [
{"role": "system", "content": "You are a concise assistant."},
{"role": "user", "content": "Give me two bullet points on the value of clear commit messages."}
],
"temperature": 0.3,
"max_tokens": 200
}
resp = requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
timeout=30
)
resp.raise_for_status()
data = resp.json()
content = data["choices"][0]["message"]["content"]
print(content)Notas de Campo
- La primera ejecución fue sin incidentes (un alivio). La estructura coincidía con lo que esperaba, lo que hizo que migrar una pequeña biblioteca de prompts fuera rápido.
- Mantuve la temperatura baja para respuestas repetibles. Eso suena obvio, pero todavía lo olvido cuando estoy solucionando problemas.
- Si necesitas ejecuciones deterministas, también fija top_p y seed si la API lo admite. Cuando la documentación está en silencio, asumo no determinista.
Si estás comparando proveedores, el beneficio aquí es baja fricción. La desventaja es que las diferencias se esconden en los bordes, cargas de error, contabilidad de tokens, y forma de streaming. Esos bordes son donde tu integración se siente sólida o molesta.
Ejemplo de Generación de Código
No pido a los modelos que escriban módulos completos. Se convierte en un trabajo de limpieza. Pero para pequeños ayudantes, como “analizar este formato de marca de tiempo” o “redactar el SQL con marcadores de posición”, es útil.
Usé un prompt estrecho, un contrato claro, y límites de salida pequeños. Eso impidió que el modelo deambulara e hizo que los diffs fueran fáciles de revisar.
import requests, os
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
messages = [
{"role": "system", "content": (
"You generate small, safe Python helpers. "
"Return only code inside one block."
)},
{"role": "user", "content": (
"Write a Python function `parse_yyyymmdd` that takes a string like '2026-01-31' "
"and returns a datetime.date. If invalid, return None. No external deps."
)}
]
resp = requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={
"model": "deepseek-chat", # or your V4-capable model
"messages": messages,
"temperature": 0,
"max_tokens": 250
},
timeout=30
)
resp.raise_for_status()
code = resp.json()["choices"][0]["message"]["content"]
print(code)Lo que ayudó en la práctica
- Siempre le digo que devuelva solo código. Si omito eso, obtengo oraciones de envoltura que no necesito.
- La temperatura 0 reduce ediciones complicadas.
- Reviso la lógica de todas formas. En mi ejecución manejó ValueError, pero aún agregué una prueba adicional para espacios en blanco. Dos minutos más ahora ahorran horas de sorpresa después.
Esto no ahorró tiempo en el primer disparo. Después de tres o cuatro pequeños ayudantes, noté que redujo el esfuerzo mental: menos cambios de pestaña, menos momentos de “¿cuál es exactamente el código strptime nuevamente?”. Eso es suficiente para mí.
Respuestas de Streaming
Me gusta el streaming para cualquier prompt que pudiera crecer. Me permite salirme temprano si la respuesta se está desviando, y hace que las respuestas largas se sientan menos pesadas.
El streaming de DeepSeek utilizó el patrón habitual en mis pruebas: establece stream=true y lee líneas de datos hasta [DONE]. No necesitaba un cliente especial, requests con iter_lines fue suficiente.
import os, json, requests
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "Be brief."},
{"role": "user", "content": "Summarize this: Streaming keeps the UI responsive and lets me stop early."}
],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line:
continue
if line.startswith("data: "):
chunk = line[len("data: "):]
if chunk == "[DONE]":
break
try:
obj = json.loads(chunk)
delta = obj["choices"][0]["delta"].get("content", "")
if delta:
print(delta, end="", flush=True)
except json.JSONDecodeError:
# I keep a small log when this happens: usually network blips
pass
print()Dos pequeños comportamientos que me gustaron:
- Los tokens tempranos llegaron rápidamente (uno o dos segundos en una conexión limpia). No científico, solo suficiente para sentirse rápido cuando lo conecté en una herramienta CLI.
- El marcador
[DONE]apareció de manera confiable. Suena trivial hasta que no lo hace, los terminadores faltantes hacen que las UIs se cuelguen.
Si necesitas hacer streaming en una aplicación web, colocaría una capa de servidor delgada en el medio para normalizar eventos. Es un paso extra, pero mantiene tu frontend simple.
Server-Sent Events
Bajo el capó, estás efectivamente leyendo Server-Sent Events. Si prefieres un ayudante, sseclient-py funciona, pero hacer el tuyo aquí está bien siempre que protejas contra líneas parciales y timeouts. La página de documentos sobre streaming en la documentación de la API de DeepSeek fue suficiente para poner esto en marcha sin sorpresas.
Manejo de Errores
 La mayoría de mis errores fueron predecibles: clave faltante, nombre de modelo incorrecto, o timeouts cuando aceleré mi red para simular Wi‑Fi de viaje.
La mayoría de mis errores fueron predecibles: clave faltante, nombre de modelo incorrecto, o timeouts cuando aceleré mi red para simular Wi‑Fi de viaje.
Un pequeño patrón que reutilizo:
import httpx, time, os
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
RETRIABLE = {408, 409, 425, 429, 500, 502, 503, 504}
async def chat_once(client, messages):
resp = await client.post(
BASE_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json={
"model": "deepseek-chat",
"messages": messages,
"temperature": 0.2,
"max_tokens": 300,
},
timeout=30,
)
if resp.status_code == 401:
raise RuntimeError("Unauthorized. Check DEEPSEEK_API_KEY and account access.")
if resp.status_code == 404:
raise RuntimeError("Endpoint or model not found. Confirm model name in console/docs.")
if resp.status_code in RETRIABLE:
raise RuntimeError(f"Retryable status: {resp.status_code}")
resp.raise_for_status()
return resp.json()
async def chat_with_retries(messages, attempts=4):
backoff = 0.5
async with httpx.AsyncClient() as client:
for i in range(attempts):
try:
return await chat_once(client, messages)
except RuntimeError as e:
msg = str(e)
if "Retryable status" in msg and i < attempts - 1:
time.sleep(backoff)
backoff *= 2
continue
raiseAlgunas notas prácticas:
- Límites de tasa: vi 429 cuando ejecuté pruebas paralelas. El backoff exponencial ayudó, pero también agregué pequeña variación aleatoria (50–150ms) para evitar manadas de trueno.
- Higiene de timeout: establecí timeouts de conexión/lectura más cortos para verificaciones rápidas (5–10s) y más largas para prompts grandes. Los timeouts no deberían ser todos 30s de forma predeterminada: oculta problemas.
- Cargas de error: cuando las cosas fallaban, el cuerpo JSON incluía un mensaje que podría mostrar en un registro. Aún lo envuelvo en mis propias excepciones para que controle lo que llega a la UI.
Si tu base de código ya habla el esquema de estilo OpenAI, esto es manejable: la misma forma de mensaje, bordes ligeramente diferentes. Lo principal es ser estricto acerca de los nombres de modelos y registrar el cuerpo de respuesta completo en no-2xx para que no adivines.
En términos de documentación, confié en la documentación oficial de la API de DeepSeek para nombres de parámetros y forma de streaming. Siempre que un proveedor usa endpoints familiares, es tentador asumir paridad. He aprendido a revisar primero la documentación y copiar menos entre clientes de lo que pienso que puedo.
A quién le podría gustar esto

- Si tienes un wrapper de Python existente para chat completions, la ruta de migración es suave.
- Si te importa el streaming y los reintentos simples, se comporta de manera predecible.
- Si necesitas herramientas muy específicas (esquemas de function-calling, tokens de razonamiento, o trabajos por lotes), querrás leer la documentación de cerca y hacer prototipo con una tarea estrecha antes de comprometerte.
No intenté orquestar agentes largos y de múltiples pasos aquí. Me enfoqué en pequeños prompts de uso diario, el tipo que va elimando fricción. Ahí es donde la API V4 de DeepSeek con Python se sentía lo suficientemente sólida para mantener.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes
