Contexto de 1M de Tokens en DeepSeek V4: Cómo Solicitar Bases de Código Completas

Hey mis amigos. Soy Dora. La primera vez que metí un proyecto completo en la ventana de 1M tokens de DeepSeek V4, no me sentí poderosa. Me sentí cautelosa. Un millón de tokens suena como café sin límite, pero cualquiera que haya intentado pensar durante horas bajo los efectos de la cafeína sabe que los bordes se desdibujan. Quería ver si este nuevo tamaño de contexto realmente cambiaría cómo trabajo, o simplemente me animaría a pegar más cosas.
Pasé unos días (27–30 de enero de 2026) usando DeepSeek V4 con 1M tokens en tres tareas que tengo constantemente:
- leer un monorepo de tamaño medio sin configurar localmente,
- rastrear un bug a través de servicios que se comunican demasiado,
- y pedir sugerencias de refactor que no rompan las pruebas.
Lo que aprendí: puedes encajar mucho, pero el modelo todavía necesita que señales en el mapa. Las ganancias no vinieron de meter más archivos: vinieron de cómo preparé el prompt y cómo pedí al modelo que se moviera a través de él.
Qué significa realmente 1M Tokens
 No me importa el número en sí. Me importa lo que sostiene con la mente clara.
No me importa el número en sí. Me importa lo que sostiene con la mente clara.
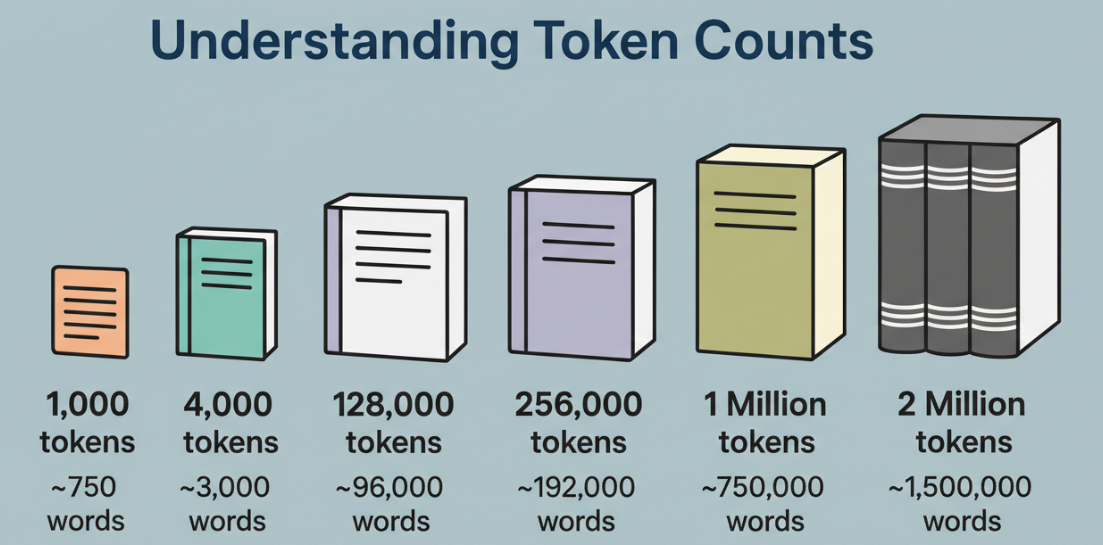
Un token no es una palabra. Es un fragmento, a veces una palabra completa, a veces parte de una, a veces puntuación. En textos en inglés, generalmente trato 1 token como ~0.75 palabras para una planificación aproximada. Para código, los tokens vienen rápido: llaves, puntos, nombres de métodos, todo dividido. Un millón de tokens es mucho territorio, pero no es atención infinita.
Lo que cambió para mí esta semana: dejé de podar tan agresivamente. Con contextos de 128K, resumiría agresivamente y mantendría solo la ruta activa. Con 1M, podía mantener la ruta activa más los archivos “fríos” que tienden a sorprenderme después (config, migraciones, scripts de compilación, glue de workflow). Dicho esto, si volcaba todo de una vez, las respuestas se volvían vagas. Cuando le pasaba información al modelo por etapas, con signos claros, los resultados se sentían más sólidos.
Equivalente de Líneas de Código
Las matemáticas aproximadas que usé mientras trabajaba:
- Muchos repos mezclan código y documentación. En carpetas pesadas de código, vi ~2–3 tokens por carácter en lenguajes densos, pero un atajo práctico: piensa en ~4 tokens por línea para líneas simples, ~8–12 para líneas del mundo real con indentación, nombres y comentarios.
- A ese ritmo, 1M tokens sostiene alrededor de 80K–150K líneas de código, dependiendo del estilo e idioma. Un servicio TypeScript con comentarios y nombres amigables para linting se sitúa en el lado más alto. Los bundles minificados disparan el conteo y no vale la pena incluirlos.
En la práctica, mi “ajuste seguro” fue ~60K líneas de código fuente significativo + documentación y pruebas dirigidas. Podría ir más alto, pero la latencia subía y las respuestas se suavizaban. Tu experiencia variará según las reglas del tokenizador y la mezcla de lenguajes.
vs Modelos Actuales (128K)
Pasar de 128K a 1M se siente menos como una mochila más grande y más como traer un carrito de ruedas. Puedes llevar más, pero no correrás.
Lo que noté:
- Latencia: Los prompts de contexto completo tardaron notablemente más. Cuando dividía la sesión (por etapas), la latencia se sentía manejable.
- Recuerdo: Con 128K, el modelo frecuentemente “olvidaba” archivos anteriores a menos que repitiera la parte clave. Con 1M, no olvidaba, pero a veces generalizaba en lugar de citar específicos. Tuve mejor suerte cuando le pedía que citara rutas de archivo y rangos de línea cuando fuera posible.
- Precisión: Cuanto mayor sea el contexto, más necesitas comportamientos de indexación en tu prompt. De lo contrario, obtienes resúmenes competentes que evitan los casos extremos desordenados que realmente te importan.
Si esperas que 1M tokens signifique “no más ingeniería de prompts”, no contaría con ello. Cambia el tipo de dirección que haces.
Estructura de Prompt para Bases de Código Grandes
 Dejé de pensar en el prompt como un mensaje y comencé a tratarlo como un plan de lectura. El modelo puede leer mucho ahora, pero todavía se beneficia de una tabla de contenidos y un rastro.
Dejé de pensar en el prompt como un mensaje y comencé a tratarlo como un plan de lectura. El modelo puede leer mucho ahora, pero todavía se beneficia de una tabla de contenidos y un rastro.
Lo que mejor funcionó para mí se veía así: framing de sistema corto, índice de proyecto conciso, un orden declarado de exploración, luego una tarea específica. Y luego mantuve la conversación en rondas, no un mega-prompt.
Orden de Archivos
Obtuve respuestas más confiables cuando le dije al modelo qué abrir primero, segundo, tercero. Una sola lista en la parte superior lo ayudó a construir una pila mental:
- Comenzar con los puntos de entrada (CLI, manejadores HTTP, trabajos). Ancla el flujo.
- Luego la capa de composición (contenedor DI, main.ts, app.py) donde se conectan las dependencias.
- Después, los módulos de dominio principal y sus interfaces.
- Solo entonces: ayudantes, utilidades y piezas transversales (logging, telemetría, config).
- Pruebas al final, a menos que esté depurando una falla específica, en cuyo caso, comenzar con la especificación fallida para establecer expectativas.
También incluí notas de “no leer” para carpetas que se ven importantes pero no lo son: código generado, activos compilados, snapshots. Ahorró tokens y mantuve la atención del modelo en código vivo.
Un pequeño truco: le pedí al modelo que mantuviera una lista rodante de “archivos activos” (rutas y resúmenes cortos) y que la actualizara mientras nos movíamos. Cuando se desviaba, podía apuntar a esa lista y decir, “Mantente dentro de este conjunto por ahora”. Eso mantuvo las respuestas concretas.
Mapeo de Dependencias
Uno de los pasos más útiles fue pedir un mapa de dependencias temprano, no como un diagrama sino como una tabla simple de aristas: el módulo A importa B, B usa C, C golpea variables de entorno, y así sucesivamente. Lo mantuve textual y conciso.
Lo que esto hizo en la práctica:
- Expuso dependencias extraviadas (el tipo que sangra preocupaciones entre carpetas).
- Me dio una lista corta de “puntos de presión” para revisar antes de cualquier refactor.
- Ayudó al modelo a hacer referencia al lugar correcto cuando pedí cambios.
También hice que el modelo expresara suposiciones, lo que infirió de nombres, comentarios o pruebas. Cuando una suposición era incorrecta, la corregía una vez, y los pasos posteriores se mantenían más limpios.
Una advertencia: pedir un mapa de dependencias completo en un repo grande de una sola vez llevó a timeouts y gráficos vagos. Obtuve mejores resultados limitando el alcance por capa (por ejemplo, solo acceso a datos, solo manejadores HTTP) y luego fusionando las notas yo misma. Tomó 10 minutos extras pero fue beneficioso en precisión.
Estrategias de División Cuando es Necesario
 Incluso con una ventana de 1M tokens, todavía dividía. No porque no cupiera, sino porque mi pensamiento era mejor en etapas, y el modelo respondía más precisamente cuando estrechaba su campo de visión.
Incluso con una ventana de 1M tokens, todavía dividía. No porque no cupiera, sino porque mi pensamiento era mejor en etapas, y el modelo respondía más precisamente cuando estrechaba su campo de visión.
Algunos patrones que se mantuvieron esta semana:
- Organiza el resumen: Comencé con un contexto pequeño, índice de proyecto, tarea, restricciones conocidas, luego pregunté por un plan de lectura y verificación. Solo después le pasé el código en el orden que acordamos.
- Limita el conjunto activo: Para un refactor, mantuve solo los 5–12 archivos en juego y pedí cambios con rutas explícitas. Si una edición tocaba una utilidad compartida, agregaba ese archivo en el siguiente turno. El modelo se mantuvo más ajustado.
- Resume en los bordes: Antes de pasar a una nueva carpeta, pedía un breve resumen de lo que aprendimos y cualquier incertidumbre. Estos resúmenes actuaron como migas de pan entre turnos sin repegar cada archivo.
- Usa recuperación a propósito: Para repos que no encajaban cómodamente, usaba embeddings para traer archivos por consulta (“normalización de id de pago”, “retroceso de reintento”). Mantuve el conjunto recuperado pequeño por turno, generalmente menos de 40K tokens, para que las respuestas no se difuminaran.
- Verifica hacia adelante, no hacia atrás: En lugar de preguntar, “¿Usaste todo lo que pegué?” Pregunté, “Señala las funciones específicas y líneas en las que se basa tu sugerencia”. Eso forzó referencias concretas e hizo obvios los errores.
Fricción que encontré:
- La latencia se arrastra cuando envías mensajes de contexto completo en cada turno. Organizar redujo mi tiempo de respuesta promedio de 70–90s a 20–40s en las mismas tareas.
- El costo importa. Los prompts grandes se suman. Ahorré tokens eliminando comentarios que reiteraban lo obvio, removiendo artefactos compilados y omitiendo bundles de vendedores.
- Los efectos de posición son reales. El contenido al principio o al final de un prompt gigante tiende a ser más “disponible”. Luché contra esto repitiendo las restricciones pequeñas pero críticas cerca del final de cada turno.
¿Quién se beneficia de la ventana de 1M?

- Si vives en monorepos, manejas auditorías o haces refactores transversales, te compra menos pasos de configuración y menos gastos generales de indexación local. Es un punto de partida más tranquilo.
- Si tu trabajo es principalmente correcciones de bugs enfocadas en servicios pequeños, la capacidad extra no ayudará mucho. Un contexto más pequeño más una canalización de recuperación ajustada se sentirá más rápido.
Una nota sobre confianza: le pedí al modelo que citara líneas de código exactas para cambios riesgosos (migraciones, autenticación). Cuando dudaba o parafraseaba, traté eso como una bandera para estrechar el alcance o pegar el archivo específico nuevamente. Ese pequeño hábito previno un par de casi-errores.
Si quieres la descripción formal de los límites del modelo o el comportamiento del tokenizador, consulta la documentación del proveedor. Cuando necesitaba especificidades, volvía a la tarjeta del modelo oficial y las notas de ventana de contexto. Me mantuvo honesta sobre lo que le pedía al modelo que hiciera.
Esto no es magia. Es solo una mesa más grande. Útil, si organizas las sillas.
Sigo pensando en una cosa pequeña del martes: pedí una corrección, y el modelo sugirió cambiar una función que se veía bien a primera vista. No lo era. El bug vivía en un ayudante dos capas hacia abajo. Un millón de tokens no cambió eso. Mis notas sí.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes
