WaveSpeedAI X DataCrunch: FLUX Echtzeit-Bildgenerierung auf B200

WaveSpeedAI X DataCrunch: FLUX Echtzeit-Bildgenerierung auf B200
WaveSpeedAI hat sich mit dem europäischen GPU-Cloud-Anbieter DataCrunch zusammengetan, um einen Durchbruch bei der Bereitstellung von generativen Bild- und Videomodellen zu erzielen. Durch die Optimierung des Open-Weight-FLUX-dev-Modells auf DataCrunchs hochmoderner NVIDIA-B200-GPU liefert unsere Zusammenarbeit bis zu 6× schnellere Bildgenerierung im Vergleich zu branchenüblichen Baselines.
In diesem Beitrag geben wir einen technischen Überblick über das FLUX-dev-Modell und die B200-GPU, diskutieren die Herausforderungen bei der Skalierung von FLUX-dev mit Standard-Inference-Stacks und teilen Benchmark-Ergebnisse, die zeigen, wie WaveSpeedAIs proprietäres Framework die Latenz und Kosteneffizienz erheblich verbessert. Enterprise-ML-Teams werden erfahren, wie diese WaveSpeedAI + DataCrunch-Lösung schnellere API-Antworten und deutlich reduzierte Kosten pro Bild ermöglicht – und damit echte KI-Anwendungen in der Praxis befähigt. (WaveSpeedAI wurde von Zeyi Cheng gegründet, der unsere Mission zur Beschleunigung von generativer KI-Inference leitet.)
Dieser Blog wird auch auf dem DataCrunch-Blog veröffentlicht.
FLUX-Dev: State-of-the-Art-Bildgenerierungsmodell
FLUX-dev ist ein hochmodernes (SOTA) Open-Source-Bildgenerierungsmodell, das Text-zu-Bild- und Bild-zu-Bild-Generierung ermöglicht. Seine Fähigkeiten umfassen gutes Weltverständnis und Prompt-Adhärenz (dank des T5-Text-Encoders), Stilvielfalt, komplexe Szenensemantik und Kompositionsverständnis. Die Ausgabequalität des Modells ist vergleichbar mit oder kann beliebte proprietäre Modelle wie Midjourney v6.0, DALL·E 3 (HD) und SD3-Ultra übertreffen. FLUX-dev ist schnell zum beliebtesten Bildgenerierungsmodell in der Open-Source-Community geworden und setzt einen neuen Maßstab für Qualität, Vielseitigkeit und Prompt-Alignment.
FLUX-dev nutzt Flow Matching, und seine Modellarchitektur basiert auf einer Hybrid-Architektur aus multimodalen und parallelen Diffusions-Transformer-Blöcken. Die Architektur hat 12B Parameter, ungefähr 33 GB fp16/bf16. Daher ist FLUX-dev mit dieser großen Parameteranzahl und dem iterativen Diffusionsprozess rechnerisch anspruchsvoll. Effiziente Inferenz ist für großflächige Inferenzszenarios unerlässlich, in denen die Benutzerfreundlichkeit entscheidend ist.
NVIDIAs Blackwell-GPU-Architektur: B200
Die Blackwell-Architektur umfasst neue Funktionen wie Tensor-Cores der 5. Generation (fp8, fp4), Tensor Memory (TMEM) und CTA-Paare (2 CTA).
-
TMEM: Tensor Memory ist eine neue On-Chip-Speicherebene, die die traditionelle Hierarchie aus Registern, Shared Memory (L1/SMEM) und Global Memory ergänzt. In Hopper (z. B. H100) wurde On-Chip-Daten über Register (pro Thread) und Shared Memory (pro Thread Block oder CTA) verwaltet, mit Hochgeschwindigkeitstransfers über den Tensor Memory Accelerator (TMA) in Shared Memory. Blackwell behält diese bei, fügt aber TMEM als zusätzliche 256 KB SRAM pro SM hinzu, die speziell für Tensor-Core-Operationen reserviert sind. TMEM ändert nicht grundlegend, wie Sie CUDA-Kernel schreiben (der logische Algorithmus ist derselbe), bietet aber neue Tools zum Optimieren des Datenflusses (siehe ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (CTA-Paare) und Cluster-Kooperation: Blackwell führt auch CTA-Paare als Möglichkeit ein, zwei CTAs auf dem gleichen SM eng zu verbinden. Ein CTA-Paar ist im Grunde ein Cluster der Größe 2 (zwei Thread Blocks, die gleichzeitig auf einem SM mit speziellen Synchronisierungsfähigkeiten geplant sind). Während Hopper bis zu 8 oder 16 CTAs in einem Cluster erlaubt, um Daten über DSM zu teilen, ermöglichen CTA-Paare in Blackwell ihnen, die Tensor-Cores auf gemeinsamen Daten kollektiv zu nutzen. Tatsächlich erlaubt das Blackwell PTX-Modell zwei CTAs, Tensor-Core-Anweisungen auszuführen, die auf die TMEM des jeweils anderen zugreifen.
-
Tensor-Cores der 5. Generation (fp8, fp4): Die Tensor-Cores in der B200 sind merklich größer und ~2–2,5x schneller als die Tensor-Cores in der H100. Hohe Tensor-Core-Auslastung ist für die Erreichung großer Hardware-Geschwindigkeitssteigerungen der neuen Generation entscheidend (siehe Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Leistungszahlen ohne Sparsity
| Technische Spezifikationen | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0,989 PFLOPS | 2,25 PFLOPS |
| INT8 | 1,979 PFLOPS | 4,5 PFLOPS |
| FP8 | 1,979 PFLOPS | 4,5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| GPU-Speicher | 80 GB HBM3 | 180GB HBM3E |
| GPU-Speicherbandbreite | 3,35 TB/s | 7,7TB/s |
| NVLink-Bandbreite pro GPU | 900GB/s | 1.800GB/s |
Micro-Benchmarking auf Operator-Ebene von GEMM und Attention zeigt Folgendes:
- BF16 und FP8 cuBLAS, CUTLASS-GEMM-Kernel: bis zu 2x schneller als cuBLAS-GEMMs auf H100;
- Attention: cuDNN-Geschwindigkeit ist 2x schneller als FA3 auf H100.
Die Benchmark-Ergebnisse deuten darauf hin, dass die B200 außergewöhnlich gut für großflächige KI-Workloads geeignet ist, besonders für generative Modelle, die hohen Speicherdurchsatz und intensive Computing erfordern.
Herausforderungen bei Standard-Inference-Stacks
Das Ausführen von FLUX-dev auf typischen Inference-Pipelines (z. B. PyTorch + Hugging Face Diffusers), selbst auf High-End-GPUs wie H100, stellt mehrere Herausforderungen dar:
- Hohe Latenz pro Bild aufgrund von CPU-GPU-Overhead und fehlender Kernel-Fusion;
- Suboptimale GPU-Auslastung und untätige Tensor-Cores;
- Speicher- und Bandbreitenbottlenecks während iterativer Diffusionsschritte.
Die Optimierungsziele für großflächige und kostengünstige Inference sind höherer Durchsatz und niedrigere Latenz, was die Bildgenerierungskosten senkt.
WaveSpeedAIs proprietäres Inference-Framework
WaveSpeedAI behebt diese Engpässe mit einem proprietären Framework, das speziell für generative Inference konzipiert wurde. Dieses Framework wurde von Gründer Zeyi Cheng entwickelt und ist unsere interne Hochleistungs-Inference-Engine, die speziell für hochmoderne Diffusions-Transformer-Modelle wie FLUX-dev und Wan 2.1 optimiert ist. Wichtige Innovationen in der Inference-Engine umfassen:
- End-to-End-GPU-Ausführung, die CPU-Bottlenecks eliminiert;
- Custom CUDA Kernel und Kernel-Fusion für optimierte Ausführung;
- Fortgeschrittene Quantisierung und gemischte Präzision (BF16/FP8) unter Verwendung des Blackwell Transformer Engine bei gleichzeitiger Beibehaltung höchster Präzision;
- Optimierte Speicherplanung und Vorallokation;
- Latenz-erste Scheduling-Mechanismen, die Geschwindigkeit gegenüber Batch-Tiefe priorisieren.
Unsere Inference-Engine folgt einem HW-SW-Co-Design, das die Compute- und Speicherkapazität der B200 vollständig nutzt. Sie stellt einen großen Schritt vorwärts im KI-Modell-Serving dar und ermöglicht es uns, Ultra-Low-Latenz- und Hocheffizienz-Inference in Produktionsskala bereitzustellen. Wir bewerten, wie diese Optimierungen die Ausgabequalität beeinflussen, und priorisieren verlustfreie gegenüber lockeren Optimierungen. Das heißt, wir wenden keine Optimierung an, die Modellkapazitäten erheblich reduzieren oder die Ausgabequalität vollständig beeinträchtigen könnte, wie Text-Rendering und Szenensemantik.
Benchmark: WaveSpeedAI auf B200 vs. H100-Baseline
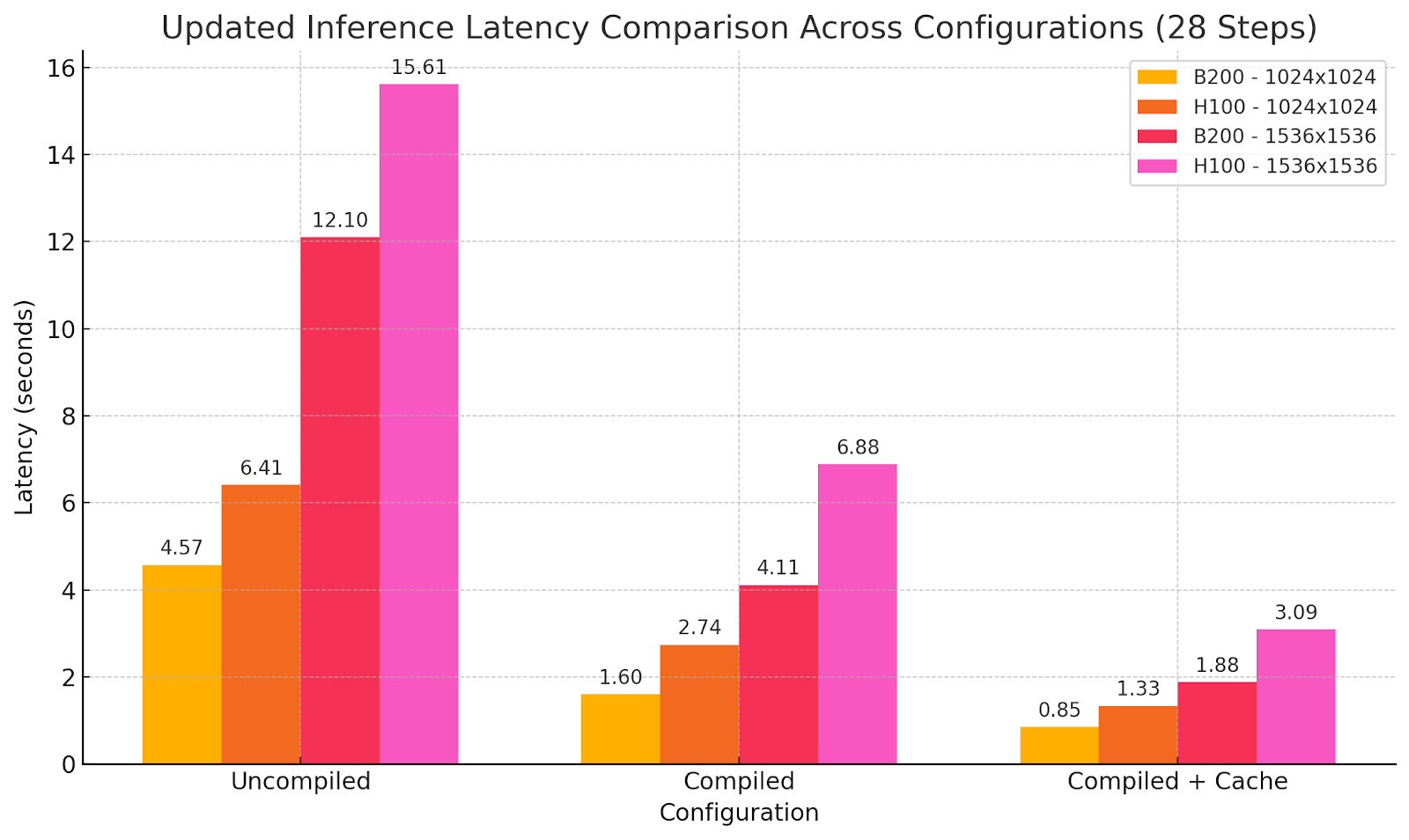
Modellausgaben unter Verwendung verschiedener Optimierungseinstellungen:

Prompt: Fotografie einer alternativen Frau mit orangem Bandana, hellem braunem langem Haar, klarer Rahmenbrille, Septum-Piercing [sic], beige Overalls, die an einer Schulter herunterhängen, ein weißes Tube-Top darunter, sie sitzt in ihrer Wohnung auf einem böhmischen Teppich, im Stil einer Vogue-Magazin-Fotografie
Implikationen
Die Leistungsverbesserungen führen zu:
- KI-Algorithmus-Design (z. B. DiT-Aktivierungs-Caching) und Systemoptimierung, unter Verwendung von GPU-Architektur-optimierten Kerneln, für bessere HW-Auslastung;
- Reduzierte Inference-Latenz, die neue Möglichkeiten eröffnet (z. B. Test-Time Compute in Diffusionsmodellen);
- Niedrigere Kosten pro Bild aufgrund verbesserter Effizienz und reduzierter Hardware-Auslastung.
Wir haben B200 gleiche H100-Kosten-Leistungs-Verhältnis, aber halbe Generierungs-Latenz erreicht. Daher steigen die Kosten pro Generierung nicht, während neue Echtzeit-Möglichkeiten entstehen, ohne Modellkapazitäten zu opfern. Manchmal ist mehr nicht besser, sondern anders, und hier haben wir eine neue Leistungsstufe erreicht, die ein neues Niveau der Benutzerfreundlichkeit bei der Bildgenerierung mit SOTA-Modellen bietet.
Dies ermöglicht reaktionsschnelle, kreative Tools, skalierbare Content-Plattformen und nachhaltige Kostenstrukturen für generative KI im großen Maßstab.
Fazit und Nächste Schritte
Die FLUX-dev-Implementierung auf B200 zeigt, was möglich ist, wenn erstklassige Hardware auf beste Software trifft. Wir verschieben bei WaveSpeedAI, gegründet von Zeyi Cheng – dem Schöpfer von stable-fast, ParaAttention und unserer inhouse Inference-Engine – die Grenzen der Inference-Geschwindigkeit und Effizienz. In den nächsten Versionen werden wir uns auf effiziente Videogenerierungs-Inference konzentrieren und wie wir nahezu Echtzeit-Inference erzielen können. Unsere Partnerschaft mit DataCrunch stellt eine Gelegenheit dar, auf hochmoderne GPUs wie B200 und die bevorstehende NVIDIA GB200 NVL72 zuzugreifen (Bestellen Sie NVL72 GB200-Cluster von DataCrunch vor), während wir einen kritischen Inference-Infrastruktur-Stack gemeinsam entwickeln.
Erste Schritte:
- WaveSpeedAI-Website
- WaveSpeedAI Alle Modelle
- WaveSpeedAI API-Dokumentation
- DataCrunch B200 On-Demand/Spot-Instanzen
Begleiten Sie uns beim Aufbau der weltweit schnellsten generativen Inference-Infrastruktur.
Verwandte Artikel

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich

Apple SHARP: Verwandle jedes Foto in unter einer Sekunde in 3D

Seedream 4.5 vs Nano Banana Pro: Welches KI-Bildmodell ist das beste?
Best Adobe Firefly Alternative in 2026: WaveSpeedAI für KI-Bildgenerierung