TranslateGemma Online Demo + Quick Start Guide

Hallo, ich bin Dora. Hast du schon von „TranslateGemma” gehört?
Der Anstoß dafür war klein: Ein Kunde schickte mir einen Text mit gemischtem Englisch und Spanisch plus ein paar versteckte Platzhalter, und ich wollte kein Übersetzungsmodell Zeile für Zeile überwachen. Du kennst diese Art: ein falscher Schritt und die Platzhalter kollabieren. Ich sah „TranslateGemma” immer wieder in Threads auftauchen, also habe ich es ausprobiert, nicht weil es neu war, sondern weil ich einen ruhigeren Weg wollte, um treue Übersetzungen zu bekommen, ohne die Formatierung zu zerstören. Spoiler: Es hat größtenteils funktioniert. Ich habe es im Januar 2026 über ein paar Online-Demos und ein lokales Setup getestet. Hier ist, was wirklich geholfen hat, wo es stolperte, und wie ich am Ende Prompts strukturiert habe, um es stabil zu halten.
TranslateGemma Online ausprobieren (Keine Installation)
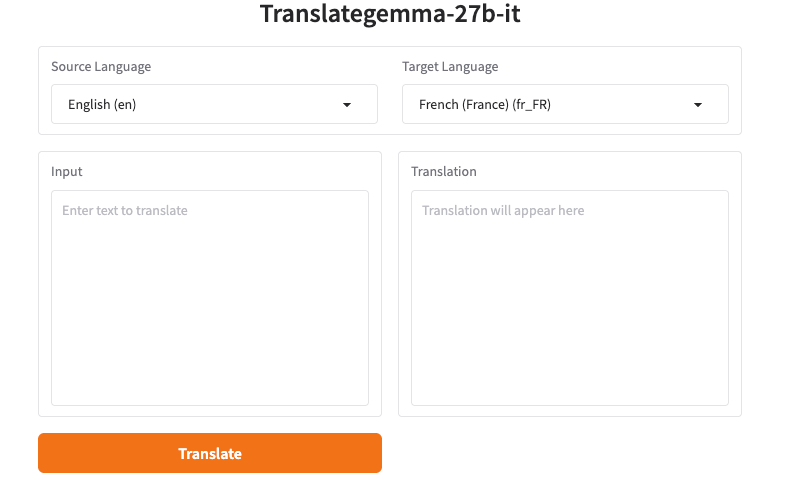
Ich mag es nicht, Dinge nur zu installieren, um zu sehen, ob sie nützlich sind. Also bin ich mit TranslateGemma online gestartet. Wenn du „TranslateGemma online” suchst, wirst du ein paar gehostete Spielplätze finden: Hugging Face Spaces, Replicate-Demos und ein paar leichte Web-UIs, die Gemma-basierte Checkpoints für Übersetzungen wrappen. Einige benötigen ein kostenloses Login: Einige nicht. In jedem Fall kannst du normalerweise Text einfügen und Sprachen auswählen.
Was mich überraschte: Die Geschwindigkeit war auch auf geteilten Demos in Ordnung. Kurze Absätze kamen in einer oder zwei Sekunden zurück: Längere Seiten brauchten etwas mehr, aber nicht genug, um mich zum Kaffee zu drängen. Ich starrte trotzdem auf den Bildschirm. Alte Gewohnheit, nehme ich an. Der größere Unterschied war nicht die Geschwindigkeit, sondern wie ich den Prompt formuliert habe.
Ein einfaches „In Französisch übersetzen” funktionierte, aber die Ausgaben drifteten ab, wenn der Text Töne mischte, Inline-Code enthielt oder Variablen wie {{first_name}} nutzte. Die Lösung war ein kurzer, expliziter Anweisungssatz. Wenn die Demo ein „System Prompt”-Feld zeigte, habe ich es benutzt. Wenn nicht, habe ich die Anweisung oben in die Benutzernachricht eingefügt.
Hier ist der minimale Prompt, der durchweg die Bereinigung für mich reduziert hat:
- Benenne Quell- und Zielsprachen.
- Sag dem Modell, was es unverändert lassen soll (Platzhalter, Code-Blöcke, Tags).
- Umzäune den Text, damit das Modell weiß, wo er anfängt und endet.
- Bitte um reine Übersetzung ohne Kommentare.
Beispiel, das ich online genutzt habe:
Beispiel, das ich online genutzt habe:
Übersetze das Folgende von Englisch zu Spanisch. Halte Platzhalter wie {{first_name}}, {{price}} und HTML-Tags unverändert. Bewahre Zeilenumbrüche und Satzzeichen. Gebe nur den übersetzten Text zurück, sonst nichts.
<
Subject: Welcome, {{first_name}}.
Your total is {{price}}.
Click <a href="/start">here</a> to begin.
>>>Das sparte beim ersten Mal nicht viel Zeit. Nach zwei Durchläufen tat es das, hauptsächlich weil ich aufgehört habe, kaputte Platzhalter zu reparieren. Wenn du TranslateGemma online nur sanity-checken möchtest, versuche einen kurzen Abschnitt mit und ohne diese Struktur. Der Unterschied zeigt sich schnell.
Chat-Template-Format, das du befolgen musst
 Gemma-ähnliche Chat-Modelle reagieren am besten, wenn du Sprecherwechsel-Marker respektierst. Einige UIs fügen sie für dich hinzu. Andere erwarten rohen Text. Wenn du Prompts direkt sendest (API, Python oder eine barere UI), hilft eine klare, wiederholbare Vorlage.
Gemma-ähnliche Chat-Modelle reagieren am besten, wenn du Sprecherwechsel-Marker respektierst. Einige UIs fügen sie für dich hinzu. Andere erwarten rohen Text. Wenn du Prompts direkt sendest (API, Python oder eine barere UI), hilft eine klare, wiederholbare Vorlage.
Zwei zuverlässige Muster funktionieren für mich:
1. Klartext-Vorlage (funktioniert in den meisten Web-Demos)
Du bist ein präziser Übersetzungsassistent.
- Quellsprache: Englisch
- Zielsprache: Spanisch
- Halte Platzhalter wie {{...}}, Markdown-Backticks und HTML-Tags unverändert.
- Bewahre Satzzeichen und Zeilenumbrüche. Füge keine Erklärungen hinzu.
Text zum Übersetzen:
<
[PASTE YOUR TEXT]
>>>2. Gemma-Chat-Turn-Stil (nützlich in Bibliotheken, die die Chat-Vorlage zeigen)
<start_of_turn>user
Du bist ein Übersetzungsassistent.
Quelle: Englisch
Ziel: Spanisch
Regeln: halte {{Platzhalter}}, Code-Blöcke und HTML intakt: bewahre Zeilenumbrüche: gebe nur die Übersetzung aus.
Text:
<
[PASTE YOUR TEXT]
>>>
<end_of_turn>
<start_of_turn>modelIch hätte nicht erwartet, dass die Sprecherwechsel-Marker so wichtig sind, aber sie sind es. Ohne sie sah ich mehr „hilfreiches” Umformulieren (das Modell versuchte, die Wording zu verbessern). Mit ihnen und mit umzäunter Eingabe blieb das Modell näher bei der Aufgabe.
Winzige Details, die einen großen Unterschied machten:
- Benenne die Sprachen explizit. „Vom Englischen zum Spanischen” funktionierte besser als „Übersetze zu Spanisch.”
- Stelle die Regeln vor dem Text. Wenn du die Regeln nach dem Text anführst, sind sie leichter zu übersehen.
- Umzäune den Text mit einem klaren Start/Stopp (
<<<und>>>oder dreifache Backticks). Dies reduzierte versehentliches Trimmen am Anfang oder Ende.
TranslateGemma lokal ausführen (Python)
 Mir gefällt es, einen lokalen Fallback für längere Arbeiten oder sensible Entwürfe zu haben. Nenne mich paranoid, aber manchmal fühlt sich die Cloud einfach zu … gesprächig an. Auf meinem Computer (32 GB RAM, Consumer-GPU) lief ein kleineres Gemma-basiertes Übersetzungs-Checkpoint gemütlich: Größere benötigten mehr VRAM oder Quantisierung. Wenn du nur CPU hast, ist es langsam, aber machbar mit sorgfältigen Einstellungen.
Mir gefällt es, einen lokalen Fallback für längere Arbeiten oder sensible Entwürfe zu haben. Nenne mich paranoid, aber manchmal fühlt sich die Cloud einfach zu … gesprächig an. Auf meinem Computer (32 GB RAM, Consumer-GPU) lief ein kleineres Gemma-basiertes Übersetzungs-Checkpoint gemütlich: Größere benötigten mehr VRAM oder Quantisierung. Wenn du nur CPU hast, ist es langsam, aber machbar mit sorgfältigen Einstellungen.
Hier ist ein einfaches Muster mit Hugging Face Transformers. Ich habe die model_id absichtlich generisch gehalten, wähle einen Gemma oder Gemma-abgeleiteten Übersetzungs-Checkpoint, dem du traust, idealerweise einen, der für Übersetzung dokumentiert ist. Die Vorlage unten spiegelt die Online-Prompts wider.
# Getestet Jan 2026 mit transformers >= 4.40
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
import torch
model_id = "<your-gemma-translation-checkpoint>" # z.B. ein Gemma-Chat oder translation-tuned Modell
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# Laden
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto" if device == "cuda" else None
)
# Prompt-Vorlage (Klartext). Tausch gegen Chat-Turns, falls dein Modell sie benötigt.
prompt = (
"Du bist ein präziser Übersetzungsassistent.\n"
"Quellsprache: Englisch\n"
"Zielsprache: Spanisch\n"
"Regeln: Halte Platzhalter wie {{...}}, Code-Blöcke und HTML-Tags unverändert: "
"Bewahre Satzzeichen und Zeilenumbrüche: Gebe nur die Übersetzung aus.\n\n"
"Text:\n<<<\n"
"Subject: Welcome, {{first_name}}.\nYour total is {{price}}.\n"
"<p>Click <a href=\"/start\">here</a> to begin.</p>\n"
">>>\n"
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3,
top_p=0.9,
repetition_penalty=1.02,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(gen[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)Ein paar Anmerkungen aus den Tests
- Falls dein Checkpoint eine Chat-Vorlage enthält, nutze das Dienstprogramm
apply_chat_template()der Bibliothek, anstelle manueller Strings. Es halbiert seltsame Verhaltensweisen. - Für lange Eingaben setze
max_new_tokenshoch genug und haltetemperatureniedrig (0,2–0,4). Wärmere Sampling ermutigte „Verbesserungen.” Einige hilfreich, einige… nicht so sehr. - Quantisierung hilft auf kleineren GPUs. 4-bit (bitsandbytes) hielt sich gut für reine Übersetzung.
- Wenn du Batch-Übersetzung brauchst, wickle den Prompt in eine kleine Funktion und streame Zeilen. Ich fand, dass Chunking nach Absatz sicherer war als gigantische Blöcke, weniger Chance, Struktur zu verlieren.
Brauchst du Übersetzungs-Workloads auszuführen, ohne GPU-Infrastruktur oder lokale Setups zu verwalten?
Wir haben WaveSpeed gebaut, damit unser Team Modelle über eine einheitliche API aufrufen und Batch-Aufgaben abwickeln kann, ohne Server zu starten oder sich mit Treibern auseinanderzusetzen → Probiere es aus!
Häufige Fehler und Korrektionen
 Das waren die Muster, auf die ich am häufigsten gestoßen bin, während ich TranslateGemma online und lokal versuchte, plus das, was tatsächlich die Reibung für mich reduziert hat.
Das waren die Muster, auf die ich am häufigsten gestoßen bin, während ich TranslateGemma online und lokal versuchte, plus das, was tatsächlich die Reibung für mich reduziert hat.
Ausgabe nicht in Zielsprache
Ich sah das hauptsächlich, wenn ich die Quellsprache nicht deklariert habe. Mixed-Language-Eingaben verwirrt es gerade genug, um englische Phrasen zu behalten. Korrektionen, die hielten:
- Benenne beide Sprachen: „Übersetze vom Englischen zum Spanischen.” Verlasse dich nicht auf Erkennung, wenn Genauigkeit zählt.
- Senke die Temperatur ab (0,2–0,4) und nutze eine leichte
repetition_penalty(etwa 1,02). Das drängte das Modell weg von kreativen Umschreibungen. - Füge eine abschließende Schutzkante hinzu: „Falls der Text bereits auf Spanisch ist, gib ihn unverändert zurück.” Das reduzierte Über-Übersetzung bei bilingualen Schnipseln.
Verlorene Formatierung oder Platzhalter
Das war die große Sache bei Marketing-E-Mails und Produkt-Strings. Frühe Durchläufe brachen {{variables}} oder reorderten HTML. Was geholfen hat:
- Sei explizit: „Halte Platzhalter wie
{{...}}und HTML-Tags unverändert. Übersetze nicht innerhalb von Code-Fences.” - Umzäune die Eingabe und bewahre Zeilenumbrüche. Das
<<<und>>>Muster funktionierte besser als sich auf leere Zeilen zu verlassen. - Für zerbrechlichen Inhalt umgebe Platzhalter mit Markern im Prompt: „Platzhalter sind mit doppelten Klammern wie
{{this}}geschützt. Ändere sie nicht.” Falls eine Demo Klammern weiter löschte, ersetzte ich temporär{{mit[[[und}}mit]]]vor der Übersetzung, dann tauschte es zurück. Es ist nicht elegant, aber es ist sicherer für Bulk-Jobs.
Modell schreibt um, anstatt zu übersetzen
Manchmal las sich die Ausgabe wie eine Überarbeitung eines Editors, nicht wie eine Übersetzung. Hilfreich in einigen Kontexten, lästig in den meisten. Meine praktischen Korrektionen:
- Gib die Rolle und die Einschränkung oben an: „Du bist ein Übersetzungsassistent. Gebe nur eine treue Übersetzung aus. Keine Zusammenfassungen, keine Erklärungen.”
- Senke die Temperatur ab und vermeide lange
max_new_tokensbei kurzen Eingaben: extra Spielraum ermutigte Kommentare in einigen Checkpoints. - Falls das Modell immer noch verschönt, versuche die Chat-Turn-Vorlage mit klarem Stopp. In lokalem Code, setze Stop-Sequenzen auf deine Turn-Marker (z.B.
<end_of_turn>). In gehosteten Demos ohne Stop-Unterstützung reduzierte das Hinzufügen von „Gebe nur den übersetzten Text zurück” Füllstoff um etwa 80% der Zeit.
Eine mehr stille Anmerkung: Einige Community-Checkpoints, die für Übersetzung kennzeichnet sind, sind tatsächlich Instruction-Tuned allgemeine Modelle. Sie werden übersetzen, aber sie sind gesprächiger. Wenn du alle drei Probleme gleichzeitig triffst, versuche einen anderen Checkpoint oder einen kleineren, strengeren. Weniger clever bedeutet oft treuer in dieser Spur. Und ehrlich gesagt, das war alles, was ich brauchte.
Hast du TranslateGemma schon versucht? Was ist dein Go-To-Prompt, um Platzhalter intakt zu halten, oder der schwierigste Text, der es gestolpert hat? Teile deine Erfolge, Misserfolge oder bevorzugte Tricks unten!
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
