Seedance 1.5 Pro: Ein großer Schritt zur nativen Audio-visuellen Generierung

Während generatives Video in die echte Produktion übergeht, reichen Bilder allein nicht mehr aus. Moderne Workflows erfordern zunehmend, dass Video und Audio zusammen generiert werden – nativ und synchron.
Seedance 1.5 Pro, ByteDances Modell der nächsten Generation für native audiovisuelle Co-Generierung, ist jetzt auf WaveSpeedAI verfügbar. Von Grund auf für zuverlässige, kontrollierbare und produktionsreife Synchronisierung entwickelt, markiert es einen wichtigen Schritt in Richtung einer wirklich einheitlichen multimodalen Generierung.
In einem kommenden technisch ausgerichteten Artikel werden wir uns Seedance 1.5 Pro genauer ansehen – seine Modellfähigkeiten, praktische Anwendungsfälle, Benchmark-Erkenntnisse und die multimodale Architektur dahinter erforschen.
Kern-Modellfähigkeiten (Funktionen & praktische Anwendung)
1. Native Audiovisuelle Generierung mit hochauflösender Synchronisierung
Der grundlegendste Durchbruch in Seedance 1.5 Pro ist sein audiovisuell-natives Generierungsparadigma. In einem einzigen Inferenzdurchlauf erzeugt das Modell sowohl die Video-Frames als auch die entsprechende Audiospur und hält Sprachrhythmus, Lippenbewegungen, Charakterbewegungen und Kameradynamiken innerhalb der gleichen zeitlichen Referenz ausgerichtet.
Über mehrere Evaluierungsrunden hinweg übertraf Seedance 1.5 Pro konsistent gängige „Video + TTS”-Pipelining-Ansätze – besonders bei langen Dialogen, schnellen Lippenbewegungen und Action-mit-Sound-Szenarien, bei denen traditionelle Ansätze tendenziell abdriften.
Prompts: Ein gutaussehender Mann steht auf einem nebelumhüllten Bergkamm. Er trägt schlanke, praktische Outdoor-Ausrüstung – eine dunkelgraue winddichte Jacke, professionelle Kletterhosen und einen Rucksack über beiden Schultern. Die Bergbrise zerzaust sein Haar leicht; sein Gesichtsausdruck ist ruhig und entschlossen. Hinter ihm wirbeln aufschwellende Wolken und Nebel unter gezackten Felsen umher und geben gelegentlich ferne schneebedeckte Gipfel frei. Die Kamera schiebt sich langsam von hinten vor, während er in den Abgrund der rollenden Wolken darunter blickt. In der eisigen Luft verdichtet sich sein Atem zu weißem Nebel und fügt natürliche atmosphärische Details hinzu. Er dreht sich leicht zur Kamera, seine scharfen Augen voller unerschütterlicher Entschlossenheit, und sagt mit fester, kräftiger Stimme: „Ich mag Herausforderungen.”
2. Mehrsprachige, mehrsprachige und dialektbewusste Generierung
Seedance 1.5 Pro unterstützt audiovisuelle Generierung über große globale Sprachen und regionale Dialekte hinweg. Es bewahrt sprachenspezifisches Timing, Phoneme und Ausdrücke und liefert präzise Lippensynchronisierung und natürliche emotionale Ausrichtung – sogar über mehrere Sprecher und schnelle Sprachwechsel hinweg.
Prompts: Ein hochgradig cinematischer Anime-Kurzfilm im japanischen Stil, der die Pracht eines Sommerfeuerwerks-Festivals darstellt. Der Schwerpunkt liegt auf hochdetaillierten Texturen (Kimono-Stoff, Haare, Haut), subtilen Mikromimiken, natürlichen und fließenden Bewegungen und zarten, emotional reichen Geschichten. Feuerwerk ähnelt weicher cinematischer Beleuchtung und verbessert die emotionale Atmosphäre. (Prompt gekürzt…) Sie sagt sanft auf Japanisch: „Ich mag dich sehr”. Der Mann verbeugt sich leicht und beschließt zu sprechen: „Eigentlich mag ich dich auch”. (Prompt gekürzt…)
3. Ausdrucksstarke Bewegung & emotionale Leistung
Seedance 1.5 Pro geht über konservative, risikominimale Bewegungsstrategien hinaus. Die Charakteranimation zeigt größere Amplitude, reichere Temposchwankungen und klarere emotionale Absicht – während die Gesamtstabilität gewahrt bleibt.
Gesichtsausdrücke entwickeln sich von bloß erkennbar zu wirklich performativ: Mikromimiken, emotionale Übergänge und Körpersprache stimmen natürlich mit gesprochenem Dialog überein. Das Ergebnis ist eine Bewegung, die sich deutlich lebendiger anfühlt.
Prompts: Ein junger Astronaut in einem abgenutzten Raumanzug sitzt in der düsteren Kabine eines Raumschiffs. Das Helmvisier ist mit Nebel und Kratzern bedeckt, und die Bedienfeld flimmert mit orange-gelben Lichtern und erzeugt eine angespannte und einsame Atmosphäre. Das Video beginnt mit diesem statischen Eröffnungsrahmen. Die Kamera zoomt dann schnell in das Gesicht des Astronauten, bevor sie zum Äußeren schneidet und das Raumschiff offenbart, das durch einen blizzardähnlichen Trümmersturm rast. Science-Fiction-Thriller-Stil. Hintergrundmusik: Tiefe elektronische Synthesizer kombiniert mit schnell anschwellenden Streichern, um Spannung aufzubauen. Soundeffekte: Dringende Motorgeräusche und heulende Weltraum-Sturmgeräusche. Dialog: „Im Leeren des Weltraums, ein falscher Schritt…” gefolgt von einer kurzen Stille, endend mit: „Mayday… Systeme fallen aus.”
4. Kinematische, fotorealistische visuelle Ästhetik
Visuell neigt sich Seedance 1.5 Pro zu einem natürlichen, Live-Action-Look statt zu schwerer Stilisierung oder überrenderten Effekten.
Beleuchtung, Komposition, Farbharmonie und Schärfentiefe sind durchgehend stabil und erzeugen Ausgaben, die sich kommerzieller Kinematographie nähern statt synthetischer Bilder.
Prompts: Erste-Person-Perspektive vom Vordersitz einer riesigen Stahlachterbahn. Die Bahn erklimmt den Gipfel und stürzt senkrecht in einen dunklen Tunnel ab. Umgebende Landschaft (ein Freizeitpark bei Sonnenuntergang) ist leicht verschwommen, während der Wind als pfeifende Luftpartikel dargestellt wird.
5. Automatische Videolängen-Anpassung
Durch Setzen des Videolängen-Parameters auf -1 wählt Seedance 1.5 Pro automatisch die am besten geeignete Dauer innerhalb eines 4–12 Sekunden-Bereichs (nur Ganzzahlsekunden).
Das Modell bewertet Erzählrhythmus, Bewegungsvollständigkeit und audiovisuelle Abgeschlossenheit, um einen natürlichen Endpunkt zu wählen. Dies reduziert verschwendete Generierungen und manuelle Optimierungen durch schlecht gewählte feste Dauern.
Prompts: 8-Bit-Pixel-Art-Stil, ein Held, der bei Sonnenuntergang läuft und springt, mit Scanline-Effekten und Retro-Videospielmusik.
6. Eingebaute Effekte über Prompt-Kontrolle
Seedance 1.5 Pro umfasst eine Reihe von eingebauten Effekten direkt im Basis-Modell. Diese können über Prompt-Anweisungen ausgelöst werden, statt sich ganz auf Post-Production-Compositing zu verlassen.
Dies ist besonders wertvoll für animations-lastige oder stilisierte Inhalte – wie Motion Comics – wo Effektdichte und Timing kritisch sind.
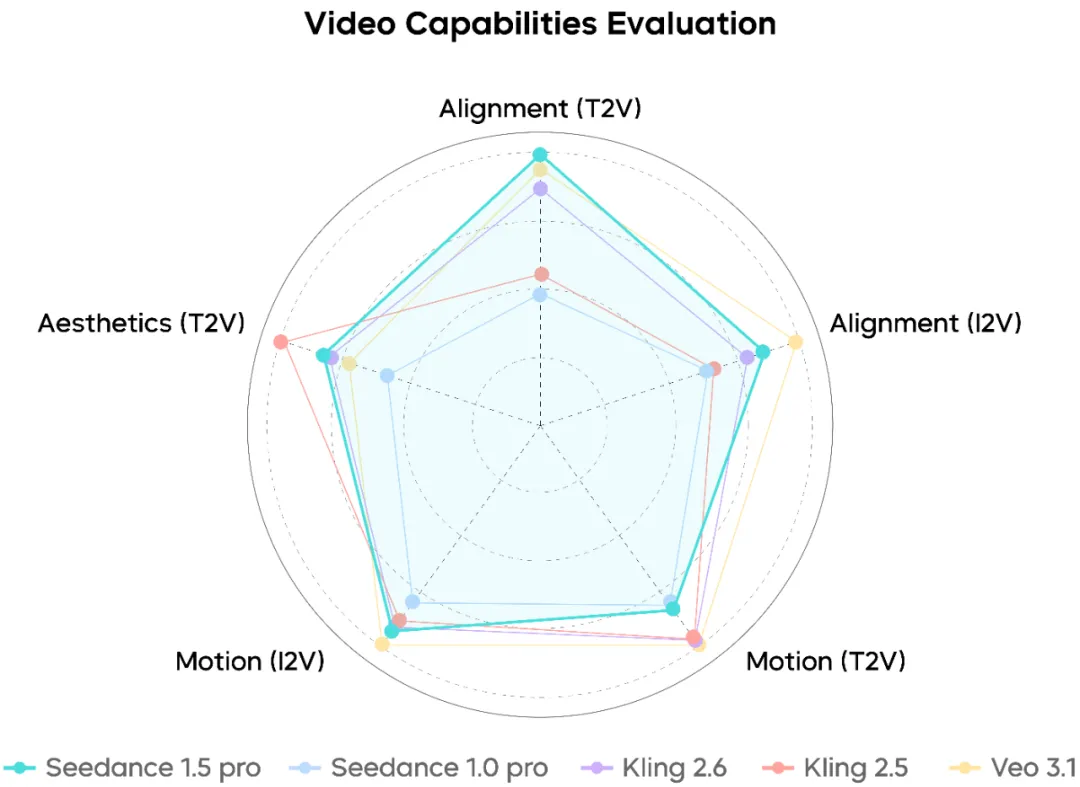
Video-Generierungs-Leistung
Seedance 1.5 Pro zeigt starkes Verständnis für komplexe Prompts mit Kamerachoreographie, Action-Sequenzierung und Erzählrhythmus. Gesichtsnahaufnahmen wirken natürlich, während lange Einstellungen und zusammengesetzte Kamerabewegungen relativ glatt und zusammenhängend bleiben.
Allerdings gibt es unter extrem hochintensiven Bewegungsszenarien noch Raum für weitere Stabilitätsverbesserungen.
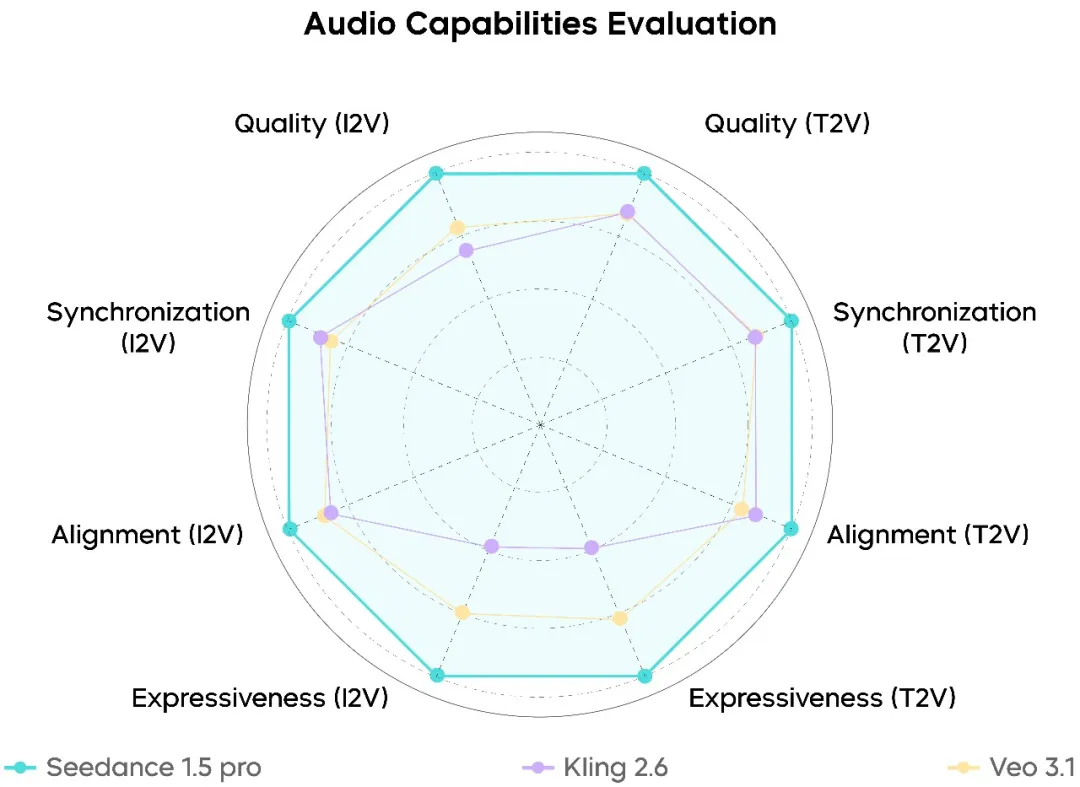
Audio-Generierungs-Leistung
Auf der Audio-Seite sitzt Seedance 1.5 Pro fest in der obersten Klasse aktueller Modelle:
- Hochgradig natürliche menschliche Stimmen mit reduzierten mechanischen Artefakten
- Realistischere räumliche Audio- und Hallcharakteristiken
- Deutlich weniger audiovisuelle Ausrichtungsfehler
Die Leistung ist besonders stark bei Chinesisch und dialektlastigem Dialog, wo Aussprache-Vollständigkeit und Klarheit bereits realen Produktionsanforderungen entsprechen.
Multimodale Co-Generierungs-Architektur: Wie Vision und Audio synchron bleiben
Seedance 1.5 Pro ist kein Flickenteppich unabhängiger Module – seine Trainings- und Inferenz-Pipeline wurde von Ende zu Ende neu gestaltet.
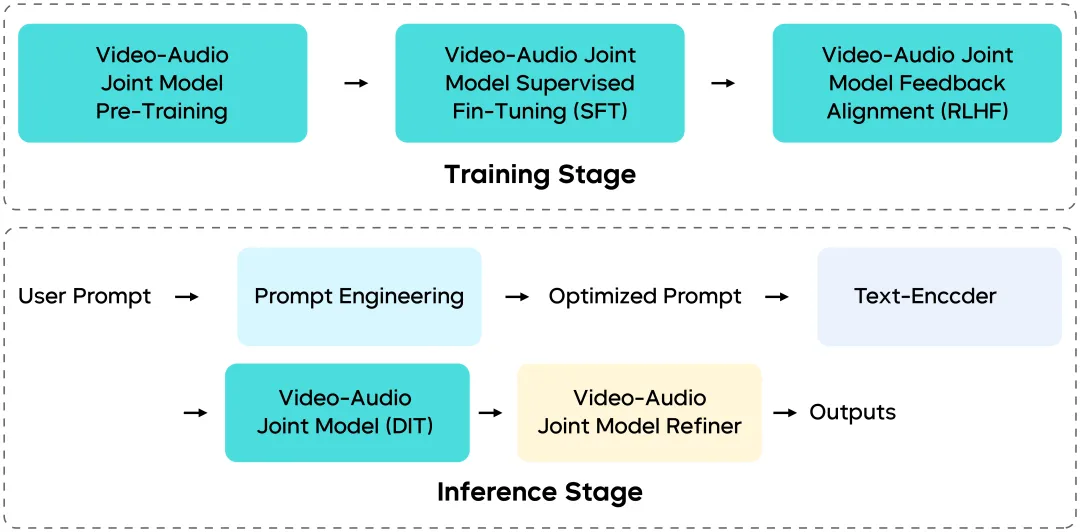
Einheitliche multimodale Architektur (auf MMDiT-Basis)
Gebaut auf einer verbesserten MMDiT-ähnlichen Architektur, ermöglicht das Modell tiefe Interaktion zwischen visuellen und Audio-Streams im gleichen zeitlichen Raum und gewährleistet:
- Zeitliche Synchronisierung
- Semantische Konsistenz
- Koordinierte Emotion und Rhythmus
Großflächiges gemischtes Modell-, Multi-Task-Training verbessert die Verallgemeinerung über nachgelagerte Aufgaben hinweg.
Multi-Stufen-Datenpipeline
Die Datenpipeline wurde entwickelt, um auszugleichen:
- Audiovisuelle Ausrichtung
- Bewegungsausdruckskraft
- Lehrplan-basierte Trainingsplanung
Zusätzlich zu traditionellen Video-Caption-Daten werden strukturierte Audio-Beschreibungen systematisch eingeführt, was das Modell in die Lage versetzt, einen reichhaltigeren gemeinsamen audiovisuellen semantischen Raum zu internalisieren.
Feinkörniges Post-Training & RLHF
Hochwertige audiovisuelle Datensätze werden für überwachtes Fine-Tuning verwendet, zusammen mit speziell für audiovisuelle Ausgaben entwickelten RLHF-Modellen, die verstärken:
- Bewegungsqualität
- Visuelle Ästhetik
- Audio-Treue
Effiziente Inferenz & Einsatzbereitschaft
Durch mehrstufige Destillation, Quantisierung und parallele Inferenz-Optimierungen:
- Die Anzahl der Funktionsbewertungen (NFE) wird erheblich reduziert
- End-to-End-Inferenz erreicht 10×+ Geschwindigkeitssteigerungen unter Beibehaltung der Qualität
Diese Effizienz ist ein Schlüsselgrund, warum Seedance 1.5 Pro zuverlässig auf WaveSpeedAI eingesetzt werden kann.
Produktionsreife Anwendungsfälle
Seedance 1.5 Pro ist besonders geeignet für:
- Grenzüberschreitende E-Commerce und lokalisierte Werbung
- Kurzform-Narrative und episodische Inhalte
- Motion Comics und ausdrucksstarke Animation
- Brand-Storytelling und cinematische Vermarktung
- Film-Vorvisualisierung und Konzeptvalidierung
Abschließende Gedanken
Der Wert von Seedance 1.5 Pro liegt nicht darin, zu beweisen, dass Modelle Sound generieren können – es geht darum, den Grundstein dafür zu legen, dass audiovisuelle Koordination zu einem zuverlässigen Standard wird.
Für Teams, die skalierbare Content-Produktion anstreben, verspricht dieser einheitliche, von Grund auf aufgebaute Ansatz **weniger Post-Production-Korrektionen, größere kreative Freiheit und einen generativen Video-Workflow, der in echten Produktionsumgebungen bestehen kann.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Vidu Q3 Review: Vergleich mit Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1 und Grok Imagine Video
