GLM-4.7-Flash vs GLM-4.7: Welches passt zu Ihrem Projekt?

Hallo meine Freunde. Ich bin Dora. Falls dir das bekannt vorkommt, bist du nicht allein. Ich war schon dort: starrend auf eine Warteschlange von winzigen, repetitiven Anfragen, die nur eine schnelle, solide Antwort brauchen – während ein paar störrische, mehrstufige Reasoning-Aufgaben in der Ecke sitzen und still deutlich mehr Rechenleistung fordern.
Also habe ich die Frage endlich laut gestellt: wo glänzt das leichtgewichtige, blitzschnelle GLM-4.7-Flash wirklich, und wo musst du das schwerere, bedachtsamere GLM-4.7 einbringen? Das ist die ehrliche, ohne Hype Antwort, auf die ich gestoßen bin – gestützt auf echte Läufe, Benchmarks wenn sie wichtig sind, und dem stillen Ziel, deinen täglichen Stack deutlich leichter anfühlen zu lassen. Falls du je bei der Frage „welches Modell sollte ich hier überhaupt nutzen?” inne gehalten hast, ist das für dich.
30-Sekunden-Antwort
Wenn Geschwindigkeit und niedrige Kosten deine Top-Hebel sind, wird sich GLM-4.7-Flash wahrscheinlich richtig anfühlen. Wenn deine Arbeit auf Reasoning-Tiefe, Tooling oder höhere Treuoutputs setzt, ist GLM-4.7 die stabilere Wahl. Der Rest ist Nuancierung um Latenz-Budgets, Kontextgröße und wie sich deine Prompts unter Druck verhalten.
Wähle Flash, wenn…
Flash ist nicht „schwächer” – es ist nur sehr ehrlich darüber, worin es gut ist.
- Du sendest viele kleine Aufgaben aus: Zusammenfassungen, Tags, Entwürfe, schnelle Transformationen.
- Latenz ist wichtiger als die letzten 10% Qualität herauszuquetschen.
- Du experimentierst, Prototypen erstellst oder UI-Interaktionen baust, die sich sofort anfühlen sollten.
- Gelegentliche Schwankungen in langen Reasoning-Schritten werden dich nicht entgleisen.
- Du möchtest ein günstigeres Standard-Modell und kannst nur bei Bedarf zu GLM-4.7 eskalieren.
Wähle GLM-4.7, wenn…
Das ist dein „vermass das nicht”-Modell.
- Code-Zuverlässigkeit, mehrstufiges Reasoning oder Präzision bei der Toolnutzung ist dir wichtig.
- Die Prompts sind lang, die Anweisungen streng oder die Outputs müssen konsistent sein.
- Du führst Evaluators, Tests oder Workflows aus, bei denen ein Fehler teuer ist.
- Du brauchst stärkere Ergebnisse bei Coding- und Long-Context-Aufgaben.
- Du kannst höhere Kosten und etwas mehr Latenz für bessere Ergebnisse tolerieren.
Architektur-Unterschiede
 Ich verfolge nicht aus Spaß Parameterzahlen, aber die Architektur erklärt viel über das Verhalten: warum sich ein Modell knackig anfühlt und das andere bewusst.
Ich verfolge nicht aus Spaß Parameterzahlen, aber die Architektur erklärt viel über das Verhalten: warum sich ein Modell knackig anfühlt und das andere bewusst.
Parameterzahl & Aktive Experten
GLM-4.7 scheint ein größeres Backbone zu betreiben und nutzt (aus öffentlichen Notizen) Expert-Routing, das Reasoning priorisiert. Flash ist für Durchsatz optimiert, leichteres Routing, weniger aktive Experten pro Token und aggressive Effizienzeinstellungen. In der Praxis zeigt sich das meist als:
- Flash: niedrigere Pro-Token-Berechnung, schnelle First-Token-Zeiten, aber es kann Reasoning-Ketten unter Druck abbrechen.
- GLM-4.7: mehr Berechnung pro Token, stabilere Reasoning-Pfade, bessere Tool-Call-Entscheidungen.
Wenn du Provider-Diagramme überfliegst, siehst du Hinweise auf Mixture-of-Experts (MoE) und Aktivierungssparsität. Die genauen Zahlen driften über Versionen hinweg, also behandle ich sie als direktional, nicht absolut. Die große Idee: Flash gibt weniger „Denk”-Zeit pro Token aus, daher geht es schneller voran; GLM-4.7 denkt länger und stolpert weniger über Grenzfälle.
Kontextfenster & Output-Limit
Zwei praktische Fragen sind wichtiger als die Schlagzahl-Kontextnummer:
- Wie weit in langen Prompts hält die Qualität?
- Wenn Outputs lang werden, verliert das Modell den Faden?
Flash wirbt normalerweise für ein gesundes Kontextfenster, aber die Qualität neigt dazu, mit sehr langen Prompts oder dichten Anweisungen früher abzunehmen. GLM-4.7 hält Kohärenz tiefer in langen Kontexten und bleibt bei Struktur in langen Outputs gehorsamer. Falls du eine Wissensbasis einspeist, ist GLM-4.7 die sicherere Standard-Wahl. Wenn du Eingaben chunking oder Retrieval nutzt um Prompts schlank zu halten, reicht Flash oft aus – und ist viel schneller.
Benchmark-Vergleich
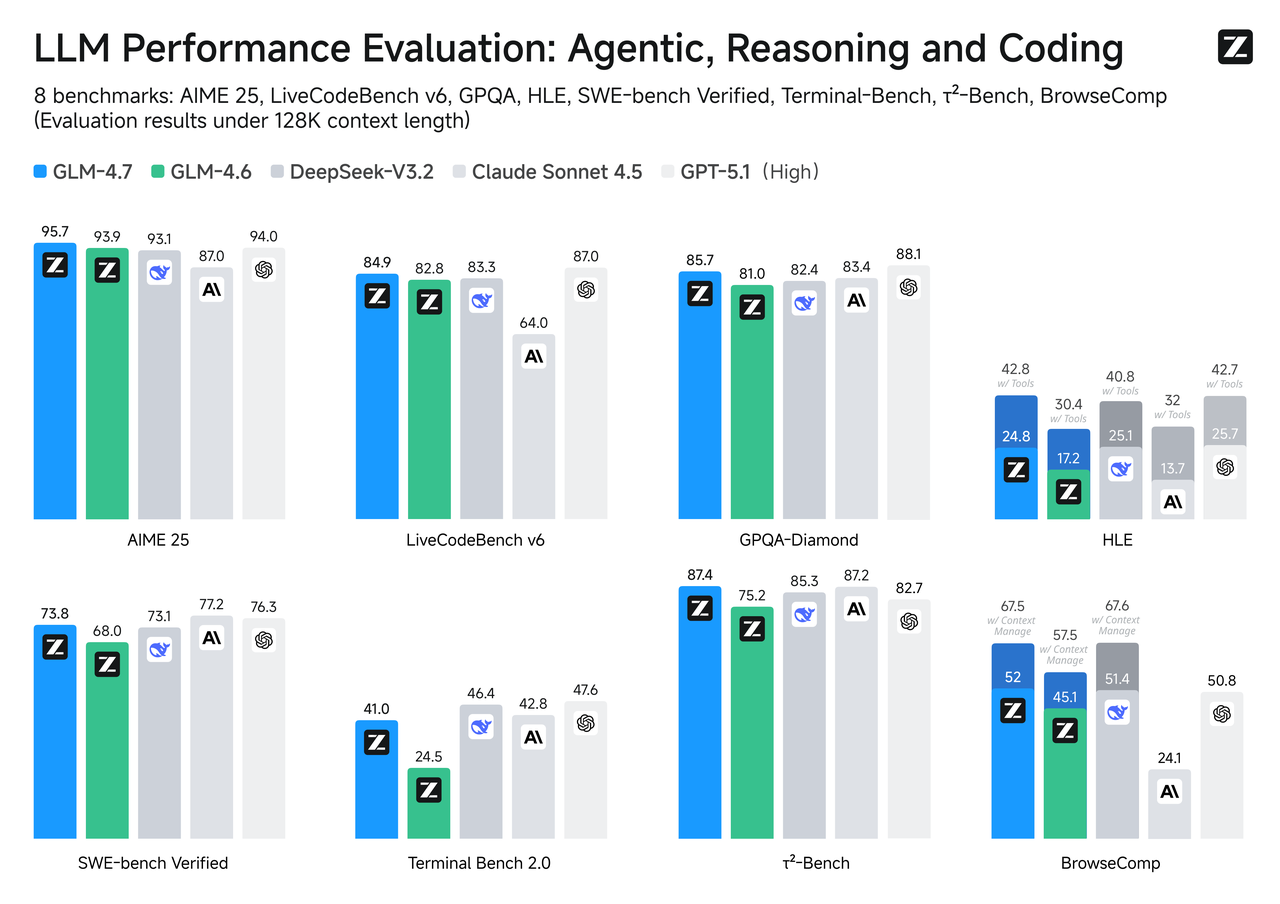 Benchmarks sind nicht die ganze Geschichte, aber sie sind ein nützlicher Kompass, besonders wenn dein Use-Case sich mit der Aufgabe deckt.
Benchmarks sind nicht die ganze Geschichte, aber sie sind ein nützlicher Kompass, besonders wenn dein Use-Case sich mit der Aufgabe deckt.
SWE-bench Verified
Für Code-Änderungen, die tatsächlich kompiliert werden und Tests bestehen müssen, tendiert GLM-4.7 dazu, über sein Flash-Pendant hinauszusteigen. Das entspricht dem, was du von einem Modell erwartet, das auf Reasoning-Tiefe und Toolnutzung optimiert ist. Flash kann Fixes entwerfen und Code schön erklären, aber wenn der Patch mehrere koordinierte Edits über Dateien hinweg braucht, ist GLM-4.7 eher wahrscheinlich, die Kette ohne abgebrochene Schritte zu folgen.
Falls deine Pipeline Auto-PRs oder Repair-Loops enthält, lohnt es sich, mit einem kleinen Sample zu sanity-checken. Der Unterschied zeigt sich mehr bei Multi-Hop-Problemen als bei Single-File-Tweaks.
LiveCodeBench / τ²-Bench
Bei Live- oder Zeit-rotierenden Coding-Benchmarks trackt GLM-4.7 generell näher an der Top-Tier angesichts seines schwereren Reasoning-Budgets. Flash, optimiert für Geschwindigkeit, sitzt eine Ebene tiefer aber antwortet schnell. Falls dein Produkt auf Code-Synthesequalität mehr verlässt als auf Interaktionsgeschwindigkeit, ist GLM-4.7 die konservative Wahl. Falls der Code beratend ist (du wirst ihn eh überprüfen) und Responsivität wichtig ist, kann Flash die richtige Abwägung sein.
Geschwindigkeit & Latenz
Hier fühlt sich die Aufteilung am klarsten an. Flash gibt das erste Token oft merklich schneller zurück, und die Gesamtzeit-bis-letztes-Token bleibt niedrig für kurze und mittlere Outputs. Das summiert sich, wenn du viele kleine Aufrufe laufen lässt oder zu einer UI streamst.
GLM-4.7 startet langsamer und läuft schwerer, aber es ist stabiler bei langen Generierungen und komplexen Tool-Call-Sequenzen. Du wirst weniger Stalls, weniger seltsame Umwege und bessere Einhaltung von Funktionsschemas sehen.
Falls du ein System baust:
- Nutze Flash für High-Traffic-UX-Momente: Autocomplete, schnelle Zusammenfassungen, Inline-Hilfe.
- Nutze GLM-4.7 für die langsame Spur: Evaluators, Code-Aktionen, Policy-Checks, Final-Passes.
Eine einfache Routing-Regel zahlt sich oft von selbst aus: Start mit Flash, eskaliere zu GLM-4.7 wenn Vertrauen sinkt oder Schwellwerte überschritten werden. Lass Regeln entscheiden, damit du das nicht musst.
Preis-Aufschlüsselung
Die Preisgestaltung variiert je Region und Provider, daher behandle ich Zahlen als bewegliche Ziele und halte die Struktur stabil.
Flash kostenlos vs GLM-4.7 Pay-per-Token
-
Flash: Viele Plattformen exponieren einen kostenlosen oder kostengünstigen Tier für Flash-ähnliche Modelle, mit großzügigen Rate-Limits verglichen mit Flaggschiff-Modellen. Großartig zum Prototypieren, für Hintergrund-Aufgaben und UI-Polish.
-
GLM-4.7: Normalerweise berechnet pro Token zu einer höheren Rate. Besseres Kosten-zu-Wert-Verhältnis bei ernsthaften Aufgaben, aber es ist leicht, zu viel auszugeben, wenn du es als Default behältst.
 Praktische Tipps:
Praktische Tipps: -
Cap Output-Tokens standardmäßig. Erhöhe das Cap nur in Routes, die es brauchen.
-
Nutze Retrieval um Prompts kurz zu halten: gieße nicht das ganze Korpus ins Fenster.
-
Cache deterministische Sub-Ergebnisse (Regex-Maps, Schema-Snippets, Few-Shot-Blöcke), damit du nicht dafür bezahlst, sie erneut zu machen.
-
Logge Token-Kosten pro Route. Der Report, den du tatsächlich liest, ist der, der in deinem wöchentlichen Workflow sitzt, nicht der mit den meisten Charts.
Im Zweifel, start günstig, mess, dann promoviere. Eskalation schlägt Optimismus.
Pick nach Use-Case
Hier ist, wie ich sie einsortieren würde, wenn das Ziel weniger Kopfschmerzen ist:
- High-Churn Content Ops (Snippets, Subject Lines, Metadaten): Flash. Der Gewinn ist Durchsatz und Konsistenz bei niedrigen Kosten.
- Support Makros und schnelle Triage: Flash zuerst, dann eskaliere zu GLM-4.7, wenn die Detektion Komplexität oder Policy-Risiko flaggt.
- Research-Notizen, Synthese, strukturierte Zusammenfassungen: Flash für Skimmen; GLM-4.7 für den Pass, der quelltreu und gut strukturiert sein muss.
- Code-Assistance: Flash für Erklärungen und „was macht das?”; GLM-4.7 für Multi-File-Edits, Migrationen und Test-aware-Änderungen.
- Daten-Cleanup und Transformation: Flash reicht für einfaches Mapping; GLM-4.7 für strikte Schemas, Validierung und Multi-Step-Joins.
- Agents und Tool-Use: GLM-4.7. Du wirst zuverlässigere Funktionsargumente und weniger Retries bekommen.
- Long-Context-Lesen oder Doc-gestützte QA: GLM-4.7, wenn du das Fenster pushst; Flash, wenn du Chunks schlank hältst.
Ein paar Field-Notizen, die ich nah halte:
- Kurze Prompts verstecken Unterschiede. Die Lücke zeigt sich, wenn Anweisungen dicht sind oder Outputs eine Struktur folgen müssen.
- Routing hilft. Auch eine einfache Regel, „Flash es sei denn Prompt > N Tokens, dann GLM-4.7”, spart Geld ohne Drama.
- Guardrails sind wichtiger als Modellwahl für repetitive Aufgaben. Validierung, Retries und kleine Checker verhindern Downstreamverwüstungen.
- Vergöttere Geschwindigkeit nicht. Unter einer Sekunde fühlt sich „sofort” für die meisten Nutzer an. Danach, stabiles Verhalten schlägt 100 ms Einsparungen.
Warum das wichtig ist: Tools altern gut, wenn sie mentale Last reduzieren. Flash hält das Kleine leicht. GLM-4.7 trägt die schweren Boxen ohne sie fallen zu lassen. Die meisten Stacks brauchen beide.
Wenn du dir unsicher bist, start mit Flash als deinen Default und erstelle eine klare Spur für GLM-4.7. Lass Routes, nicht Laune, entscheiden. Dein Kilometerstand kann variieren, und das ist okay.
Ich bemerke immer noch, an ruhigen Tagen, wie diese Aufteilung Entscheidungsmüdigkeit reduziert. Nichts Flashiges – nur weniger Kopfschmerzen.
Wie ich diese Aufteilung in der Praxis wirklich laufe
 Wenn ich schnelle Jobs zu Flash routen und schwerere zu GLM-4.7 eskalieren muss, ohne Scripts zu babysitzen, nutze ich WaveSpeed – unsere eigene Plattform.
Wenn ich schnelle Jobs zu Flash routen und schwerere zu GLM-4.7 eskalieren muss, ohne Scripts zu babysitzen, nutze ich WaveSpeed – unsere eigene Plattform.
Wir haben es gebaut um Modellwechsel, Concurrency und Batch-Aufrufe sauber zu handhaben, damit das „Flash zuerst, eskaliere wenn nötig”-Muster einfach bleibt statt zerbrechlich.
Falls du viele kleine Aufrufe laufen lässt und nicht willst, dass Routing-Logik zu einer weiteren Sache zum Pflegen wird, versuche Wavespeed!
FAQ: GLM-4.7-Flash vs GLM-4.7
1. Was sind die Hauptunterschiede zwischen GLM-4.7-Flash und GLM-4.7?
GLM-4.7-Flash ist eine leichtgewichtige, optimierte Variante von GLM-4.7. Es erreicht schnellere Inferenz und niedrigere Kosten durch Reduktion der Anzahl aktiver Experten, vereinfachtes Routing und Effizienz-Tweaks. GLM-4.7 behält ein größeres Backbone und stärkere Reasoning-Fähigkeiten, glänzt in komplexem mehrstufigem Reasoning, Long-Context-Kohärenz und präzisem Tool-Calling.
Kurz gesagt: Flash tauscht etwas Intelligenz gegen Geschwindigkeit; GLM-4.7 priorisiert Tiefe und Zuverlässigkeit.
2. Welches Modell ist schneller, und in welchen Szenarien ist der Geschwindigkeitsunterschied am auffälligsten?
GLM-4.7-Flash hat deutlich niedrigere Time-to-First-Token (TTFT) und Pro-Token-Latenz. Es glänzt in High-Throughput-, Low-Latency-Use-Cases wie Echtzeit-UI-Interaktionen, Content-Zusammenfassung, Metadaten-Generierung und schneller Prototyping.
GLM-4.7 hat höhere Startup-Overhead und schwerere Berechnung, bleibt aber stabiler für lange Outputs oder komplexe Tool-Call-Sequenzen. In der Praxis ist Flash für kurze bis mittlere Outputs (unter 500 Tokens) deutlich schneller.
3. Welches Modell ist stärker in Intelligenz und Reasoning?
GLM-4.7 outperformt Flash bei mehrstufigem Reasoning, Code-Zuverlässigkeit, Tool-Use und Long-Context-Aufgaben. Beispiele:
- SWE-bench Verified: GLM-4.7 führt bei Multi-File-Code-Editing und koordinierten Patches.
- LiveCodeBench / τ²-Bench: GLM-4.7 liefert höherqualitäts-Code, besonders für Deep-Reasoning-Szenarien.
Flash eignet sich für Single-File-Edits oder assistive Aufgaben, die menschliche Überprüfung tolerieren, aber es degradiert schneller auf langen Reasoning-Ketten oder dichten Prompts.
4. Wie vergleichen sich Kontextlänge und Output-Limits?
Beide Modelle teilen ähnliche Kontextfenster, aber GLM-4.7 wahrt bessere Kohärenz und Anweisungsfolge bei sehr langen Kontexten (>32k Tokens) oder dichten Prompts. Flash degradiert schneller unter extremer Prompt-Länge oder Dichte – paare es mit Chunking oder RAG für beste Ergebnisse.
5. Wie sollte ich basierend auf Preisgestaltung und Kostenkontrolle wählen?
GLM-4.7-Flash bietet normalerweise höhere kostenlose Quoten und niedrigere (oder sogar null) Pro-Token-Preisgestaltung, was es ideal für Prototyping, Hintergrund-Aufgaben und High-Volume-Low-Risk-Aufrufe macht. GLM-4.7 hat höhere Pro-Token-Kosten aber besseres Wert-für-Kritische-Aufgaben.
Empfehlung: Default zu Flash, eskaliere zu GLM-4.7 für komplexe Arbeit, und setze immer Token-Caps und Caching um Overspending zu verhindern.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
