GLM-4.7-Flash: Veröffentlichungsdatum, kostenlose Tier & Hauptfunktionen (2026)

Hallo, ich bin Dora.
Kürzlich tauchte GLM-4.7-Flash immer wieder in Threads von Personen auf, denen ich vertraue, normalerweise mit einem kleinen Schulterzuckend erwähnt: „schnell genug, um nicht im Weg zu sein.” Dieser Satz ist mir hängengeblieben. Ich bin im Moment nicht hinter glänzenden Modellen her: Ich bin auf der Suche nach Tools, die alltägliche Arbeit leichter machen. Verstehst du, was ich meine?
Also habe ich GLM-4.7-Flash ein paar Tage lang in meinen Stack integriert (20.–21. Jan. 2026). Kurze Prompts, kleine API-Skripte, ein paar Batch-Jobs. Nichts Dramatisches. Die Frage, die ich mir immer wieder gestellt habe, war einfach: Ist dies eine praktische Ergänzung oder einfach ein weiterer Modellname, der vorbeizieht?
Was ist GLM-4.7-Flash?
GLM-4.7-Flash ist eine geschwindigkeitsorientierte Variante der GLM-4.7-Familie von Zhipu AI. Stell dir vor, es ist das Modell, zu dem du greifst, wenn du responsive, latenzarme Generierungen ohne schwere Reasoning-Overhead möchtest. Es versucht nicht, Langform-Benchmarks zu gewinnen oder über Philosophie zu debattieren: Es zielt darauf ab, anständige Antworten schnell und günstig zu liefern.
Wer hat es entwickelt (Zhipu AI / Z.ai)
 Zhipu AI (auch bekannt als Z.ai) ist das Team hinter der GLM-Serie. Wenn du frühere GLM-Modelle probiert hast, wird dir die Benennung vertraut vorkommen: Die Nummer spiegelt die Generation wider, und das Suffix (Flash, Standard usw.) deutet auf die Kompromisse hin. Ihre Dokumentation ist unkompliziert und wird regelmäßig aktualisiert: Wenn du integrierst, speichere die offiziellen API-Dokumente auf Zhipus Entwicklerportal in deinen Lesezeichen.
Zhipu AI (auch bekannt als Z.ai) ist das Team hinter der GLM-Serie. Wenn du frühere GLM-Modelle probiert hast, wird dir die Benennung vertraut vorkommen: Die Nummer spiegelt die Generation wider, und das Suffix (Flash, Standard usw.) deutet auf die Kompromisse hin. Ihre Dokumentation ist unkompliziert und wird regelmäßig aktualisiert: Wenn du integrierst, speichere die offiziellen API-Dokumente auf Zhipus Entwicklerportal in deinen Lesezeichen.
Ich habe Zhipu-Modelle im Laufe des letzten Jahres gelegentlich verwendet, wenn ich mehrsprachige Unterstützung und stabile, vorhersehbare Ausgaben brauchte. GLM-4.7-Flash setzt diesen Trend fort, nur mit mehr Fokus auf Geschwindigkeit und Durchsatz.
Flash vs. Standard, Positionierung
So habe ich die Unterschiede in der Praxis empfunden:
- Flash: optimiert für Geschwindigkeit, geringerer Compute pro Anfrage, großartig für hochvolumige Endpoints, UI-Assistenten und Batch-Klassifizierung oder Tagging. Ich bemerkte, dass es mit prägnanten Prompts und klarer Struktur am besten funktionierte.
- Standard (nicht-Flash): langsamer, aber steiler bei Reasoning-intensiven Aufgaben. Wenn ich Multi-Step-Analysen an Flash übertrug, versuchte es, aber ich konnte sehen, dass es Schritte komprimierte, um die Latenz niedrig zu halten.
Wenn du dich zwischen ihnen entscheiden musst, eine sanfte Regel: Wenn Latenz und Kosten deinen Alltag bestimmen, fang mit Flash an. Wenn Korrektheit bei Multi-Hop-Reasoning deine primäre Einschränkung ist, wird Standard (oder ein größeres Reasoning-gestimmtes Geschwister) wahrscheinlich besser landen. Du weißt, wähle deinen Kämpfer.
Offizielle Markteinführung: 19. Januar 2026
Zhipu AI kündigte GLM-4.7-Flash am 19. Januar 2026 an. Ich begann am nächsten Tag mit Tests. Der Versionskontext ist wichtig mit diesen Modellen: Die frühen Tage bringen oft schnelle Iterationen mit sich. Wenn du dies später liest, überprüfe die Release Notes in der offiziellen Dokumentation, um alle Änderungen an den Limits oder dem Verhalten zu bestätigen.
Architektur auf einen Blick
Ich muss nicht die Interna eines Modells kennen, um es zu verwenden, aber bestimmte Details helfen mir, Kosten zu schätzen und zu sehen, wo es gut funktioniert.
30B MoE, 3B aktive Parameter
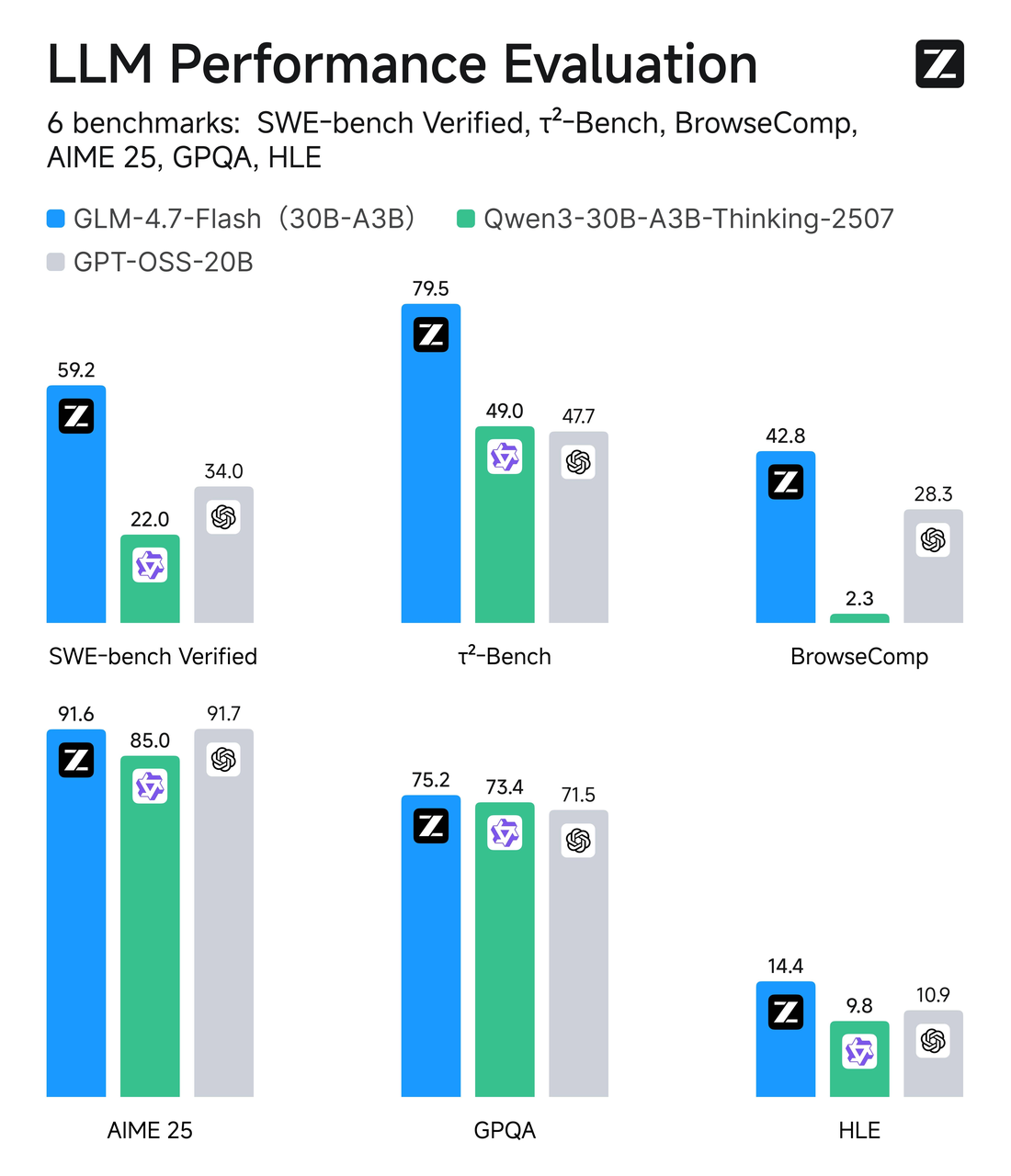 GLM-4.7-Flash verwendet ein Mixture-of-Experts-Design (MoE) mit einer Gesamtparameteranzahl von etwa 30B, aber nur ~3B Experten sind pro Token aktiv. In einfachen Worten: Es ist ein breites Modell mit selektivem Routing. Meistens arbeitet nur ein kleiner Teil des Netzwerks an deinem Token, was den Inference schlank hält.
GLM-4.7-Flash verwendet ein Mixture-of-Experts-Design (MoE) mit einer Gesamtparameteranzahl von etwa 30B, aber nur ~3B Experten sind pro Token aktiv. In einfachen Worten: Es ist ein breites Modell mit selektivem Routing. Meistens arbeitet nur ein kleiner Teil des Netzwerks an deinem Token, was den Inference schlank hält.
In der Praxis gibt MoE dir oft das Gefühl eines „größeren Gehirns wenn nötig”, ohne immer den vollständigen Compute-Preis zu zahlen. Während meiner Tests führte das zu responsiven Ausgaben selbst unter Last und konsistenterer Latenz als dichte Modelle ähnlicher Größe. Es ist keine Magie, nur eine intelligente Art, Kapazität und Geschwindigkeit zu balancieren.
MLA (Multi-Headed Latent Attention)
Die Dokumente erwähnen MLA (Multi-Headed Latent Attention). Mein Fazit als Benutzer: Es ist eine Attention-Strategie, die darauf abzielt, effizienter zu sein als klassische vollständige Self-Attention, besonders bei längeren Kontexten. Ich habe hier die Limits für lange Kontexte nicht ausgereizt: Meine Läufe waren größtenteils unter ein paar tausend Token. Trotzdem blieb der Speicher-Footprint überschaubar, und ich sah nicht den üblichen langsamen Rutsch in der Latenz, wenn Prompts von „kurz” zu „mittel” wuchsen.
Wenn du Retrieval-intensive Workflows oder Agent-Loops planst, ist MLA plus MoE ein hilfreicher Hinweis: Dieses Modell ist darauf ausgelegt, den Durchsatz zu halten, anstatt maximale Single-Shot-Reasoning-Tiefe anzustreben.
Kostenlose API — Was enthalten ist
Der kostenlose Zugriff stach heraus. Ich bin hier vorsichtig, weil kostenlose Tiers sich manchmal wöchentlich ändern. Was ich teile, ist, was ich am 20.–21. Jan. 2026 beobachtete, und was Zhipus Dokumente bei der Markteinführung nahelegten. Überprüfe immer die Limits, bevor du dies in die Produktion integrierst.
 Kurz gesagt: Die kostenlose API ließ mich echte Anfragen mit vernünftigen Standardwerten machen. Ich führte kleine Jobs durch, ohne eine Paywall in der Mitte des Tests zu treffen. Das reduzierte die Reibung, um es in einem echten Skript zu versuchen, anstatt von einem Playground aus.
Kurz gesagt: Die kostenlose API ließ mich echte Anfragen mit vernünftigen Standardwerten machen. Ich führte kleine Jobs durch, ohne eine Paywall in der Mitte des Tests zu treffen. Das reduzierte die Reibung, um es in einem echten Skript zu versuchen, anstatt von einem Playground aus.
Rate Limits & Concurrency
Was ich sah:
- Concurrency: Ich konnte problemlos mehrere parallele Anfragen von einem kleinen Worker durchführen, ohne Fehler auszulösen. In meinen Tests blieben 5–10 gleichzeitige Anfragen stabil. Wenn ich höher sprang, begann ich, Drosseln zu sehen, was in einem kostenlosen Tier zu erwarten ist.
- Durchsatz: Kurze Prompts (Klassifizierung, kleine Transformationen) wurden in der Sub-Sekunden- bis Niedrig-Sekunden-Spanne zurückgegeben. Im Durchschnitt sah ich 300–900 ms für sehr kurze Antworten und 1,5–3 s für bescheidene Ausgaben. Netzwerk-Varianz gilt.
- Sicherheit: Die API antwortete mit klaren Fehlercodes, wenn ich Limits überschritt. Das allein sparte mir Zeit, ich musste nicht erraten, was schief gelaufen war.
Ich bin nicht hinter exakten TPS-Decken hergebunden: Mein Ziel war zu sehen, ob kleine Pipelines ohne Babysitting laufen konnten. Das taten sie. Es fühlt sich wie Freiheit an, ehrlich gesagt. Wenn du spiky Workloads planst, teste mit realistischer Concurrency und baue einfache Retry/Backoff. Kostenlose Tiers sind großzügig, bis sie es nicht mehr sind.
FlashX Bezahlter Tier
Zhipu erwähnt eine „FlashX” bezahlte Option, die auf höheren Durchsatz und vorhersehbarere Leistung abzielt. Ich habe meine Tests während dieses Runs nicht zu FlashX verschoben, aber hier ist, was sich normalerweise ändert, wenn du bei Anbietern wie diesem auf einen höheren Tier upgradest:
- Höhere und garantierte Rate Limits mit weniger Drosseln.
- Mehr gleichzeitige Anfragen pro Schlüssel, nützlich für Batch-Jobs und benutzerorientierten Assistenten.
- Prioritäts-Routing (niedrigere Tail-Latenz). Das ist wichtig, wenn dir die schlechtesten 5% der Anfragen wichtig sind, nicht nur der Median.
Wenn du ein kundenorientiertes Feature versendest, ist FlashX die sicherere Route. Wenn du herumspielst, reicht der kostenlose Tier, um ein Gefühl für Stabilität und Integrationarbeiten zu bekommen. Dein Kilometerstand hängt von deinem Latenz-Budget und davon ab, wie oft du Batches erstellst.
Beste Anwendungsfälle
Ich habe eine Handvoll echte Aufgaben versucht. Nichts Glamouröses, nur was in meiner Woche auftaucht.
- Interface-Assistenten, bei denen Verzögerung die Stimmung killt. Denk an: Inline-Umschreibungen, kleine Klarstellungen, kurze Nachverfolgungen. GLM-4.7-Flash hielt die UI unmittelbar.
- Batch-Texttransformationen. Ich führte ein kleine CSV (ein paar tausend Reihen) für Toneinstellungen und Kategorientags durch. Das Modell blieb konsistent und driftete nicht halbwegs durch.
- Entwurf von Gerüsten. Gliederungen, Punkt-für-Punkt-Erweiterungen, einfache Briefs. Es handhabte Struktur gut, wenn ich es mit prägnanten Anweisungen gab. Wie einen Mini-Helfer zu haben, den man nicht bestechen muss.
- Retrieval-Zusammenfassungen mit kurzen Kontextfenstern. Wenn ich 2–4 Snippets eingab, antwortete es sauber, ohne merkwürdige Brücken zu halluzinieren. Mit langen, unordentlichen Kontext versuchte es, hilfreich zu sein, komprimierte aber manchmal zu aggressiv.
- „Erste Durchgang” Code-Kommentare oder Docstrings. Keine tiefen Umgestaltungen. Nur Absicht und Benennung klarstellen, schnell und nützlich.
Wo ich es nicht verwenden würde:
- Multi-Hop-Analyse mit Edge Cases, wo Genauigkeit wichtiger ist als Geschwindigkeit. Ich würde zu einem schwereren Reasoning-Modell greifen.
- Langform-Generierung, bei der du konstante Tonlage und tiefe Fakten-Zusammenfügung über Tausende von Token brauchst. Flash kann es, aber es fühlt sich unpassend an.
Warum das wichtig ist: Schnelle Modelle, die dein Budget nicht plündern, eröffnen Features, die du sonst kürzen würdest. Wenn dein Produkt Dutzende winziger Modell-Aufrufe pro Sitzung benötigt, fügten rasierte Latenz und geringerer Compute pro Aufruf zusammen. Kleine Erfolge, große Auszahlung.
💡 Um das Ausführen von Modellen wie GLM-4.7-Flash in echten Workflows einfacher und zuverlässiger zu machen, verwende ich WaveSpeed — unsere eigene Plattform, die API-Anfragen, Concurrency und Batch-Jobs sanft handhabt, damit du dich auf Ergebnisse konzentrieren kannst, anstatt Skripte zu babysitting.
Versuche WaveSpeed →
 Eine kleine Notiz aus den Gräben: Meine erste Stunde war nicht schneller. Ich bastelte an der Prompt-Struktur, Temperatur und max Tokens herum. Nach ein paar Läufen fand ich ein Muster, kurzer System-Prompt, explizites Output-Format, klare Einschränkungen. Das reduzierte sowohl Zeit als auch mentale Anstrengung. Es war keine Magie: Es war Setup.
Eine kleine Notiz aus den Gräben: Meine erste Stunde war nicht schneller. Ich bastelte an der Prompt-Struktur, Temperatur und max Tokens herum. Nach ein paar Läufen fand ich ein Muster, kurzer System-Prompt, explizites Output-Format, klare Einschränkungen. Das reduzierte sowohl Zeit als auch mentale Anstrengung. Es war keine Magie: Es war Setup.
Wer hat einen „schnellen 10-Minuten-Test” von GLM-4.7-Flash (oder einem Flash-Modell) gestartet und blickte dann auf und stellte fest, dass die Uhr Mitternacht sagte? Teile deine persönliche Bestleistung — und den einen Prompt-Tweak, der es endlich zum Funktionieren brachte — in den Kommentaren.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
