Was ist Z-Image-Turbo? Das 6B Ultra-schnelle Text-zu-Bild-Modell erklärt

Hallo, ich bin Dora. Damals bin ich auf Z-Image-Turbo gestoßen, nachdem ich auf ein kleines Problem stieß: Ich brauchte sauberen, lesbaren Text in einem Bild, und mein übliches Setup lieferte mir immer nur Kringel-Buchstaben. Nicht unbrauchbar, aber immer etwas daneben, wie ein Schild, das in Hektik angestrichen wurde. Ich sah ständig Notizen über ein Modell, das Text nativ verarbeitet und auf einer 16-GB-Karte ohne Probleme läuft. Also habe ich letzte Woche (Februar 2026) Z-Image-Turbo auf meinem eigenen Computer und über eine API getestet. Die Kurzversion: Es ist schnell, praktisch, und versucht nicht, ein Spektakel zu sein. Diese Kombination machte mich aufhorchen.
Was ist Z-Image-Turbo?
 Z-Image-Turbo ist ein quelloffenes Bildgenerierungsmodell mit 6-Milliarden-Parametern, das für schnelle Iteration und lesbare Textwiedergabe konzipiert ist. Es zielt auf den sweet spot, den viele von uns brauchen: gute Visuals, zuverlässige Typografie und ein Setup, das keine vollständige Workstation erfordert. Es unterstützt zweisprachige Prompts (Englisch und Chinesisch) und ist für kurze Sampling-Zeitpläne optimiert, was die Latenz niedrig hält.
Z-Image-Turbo ist ein quelloffenes Bildgenerierungsmodell mit 6-Milliarden-Parametern, das für schnelle Iteration und lesbare Textwiedergabe konzipiert ist. Es zielt auf den sweet spot, den viele von uns brauchen: gute Visuals, zuverlässige Typografie und ein Setup, das keine vollständige Workstation erfordert. Es unterstützt zweisprachige Prompts (Englisch und Chinesisch) und ist für kurze Sampling-Zeitpläne optimiert, was die Latenz niedrig hält.
Ich testete es sowohl lokal als auch über einen gehosteten Endpunkt. Lokal lief es auf einer 16-GB-GPU ohne Device-Jonglerei. Über die API konnte ich einzelne Bilder mit einer konstanten Pro-Bild-Rate pushen, ohne mir Gedanken über Batch-Optimierung zu machen. Es versucht nicht, die kinematischsten Modelle zu übertrumpfen: Es versucht, dir schnell ein solides Bild mit lesbaren Wörtern zu geben.
Die 6-Milliarden-Parameter-Architektur
Ich wähle Modelle nicht nach der Parameteranzahl, aber das erklärt einiges über das Verhalten. Mit 6 Milliarden Parametern fühlt sich Z-Image-Turbo absichtlich eingeschränkt an: leichter als die riesigen Diffusions-Varianten, schwerer als die kleinsten mobilen Versionen. In der Praxis bedeutete das zwei Dinge für mich. Erstens blieb der Speicherverbrauch vorhersehbar, kein OOM in letzter Minute, wenn ich die Auflösung erhöhte. Zweitens sprachen die Prompts konsistent an. Ich musste die Anleitung nicht überengineeren, um die Typografie intakt zu halten.
Das Architektur-Detail, das am meisten zählte: Es ist trainiert, um Text-in-Bild als Ziel erster Klasse zu behandeln, nicht als glücklicher Zufall. Das merkt man, wenn man nach Beschilderung, UI-Mockups oder Produktfotos mit Beschriftungen fragt. Die Buchstaben schmelzen nicht, sobald man Stil hinzufügt. Sie sind nicht perfekt, aber stabil genug, dass ich aufhörte, den Prompt zu überwachen.
8-Schritt-Sampling, warum es so schnell ist
 Die meisten meiner Generierungen landeten zwischen 6 und 10 Schritten, mit 8 als Standard. Dort zeigt sich die Geschwindigkeit. Sampling-Zeitpläne mit niedriger Schrittanzahl fallen oft bei feinen Details auseinander, aber hier behielten die Outputs die Form bei, und der Text blieb häufiger lesbar als nicht. Auf meiner 16-GB-Laptop-GPU wurden 512×512-Bilder routinemäßig in ein paar Sekunden fertig: Über die gehostete API blieb die Latenz auch bei leichter Parallelität knackig.
Die meisten meiner Generierungen landeten zwischen 6 und 10 Schritten, mit 8 als Standard. Dort zeigt sich die Geschwindigkeit. Sampling-Zeitpläne mit niedriger Schrittanzahl fallen oft bei feinen Details auseinander, aber hier behielten die Outputs die Form bei, und der Text blieb häufiger lesbar als nicht. Auf meiner 16-GB-Laptop-GPU wurden 512×512-Bilder routinemäßig in ein paar Sekunden fertig: Über die gehostete API blieb die Latenz auch bei leichter Parallelität knackig.
Das sparte mir nicht sofort Zeit – ich fummelte immer noch an der Prompt-Formulierung herum. Aber nach ein paar Durchläufen bemerkte ich, dass die mentale Last sank. Weniger Wiederholungen. Weniger „ein Seed mehr”-Impulse. Wenn du in kurzen Schleifen arbeitest (Entwurf → Anpassung → Versand), summiert sich die kurze Schrittanzahl schnell auf.
Schlüsselfunktionen, die zählen
Ich versuche, Feature-Listen zu vermeiden, aber ein paar Entscheidungen hier prägten, wie ich das Modell nutzte.
Zweisprachige Prompt-Unterstützung (EN/ZH)
Ich testete englische und einfache chinesische Prompts nebeneinander: Beschriftungen, Beschilderung, kurze Bildunterschriften. Das Modell verarbeitete beide, ohne dass ich etwas in den Einstellungen wechseln musste. Was hervorstach, war, dass die Prompt-Absicht über Sprachen hinweg übertragen wurde. Wenn ich auf Chinesisch nach „einem sauberen Speiseplan mit drei Abschnitten” fragte, bekam ich die gleiche Struktur wie bei der englischen Eingabe, nicht eine lockere Neuinterpretation. Wenn du über Teams oder Märkte hinweg arbeitest, reduziert das die Reibung, keine zusätzliche Feinabstimmung, keine sprachspezifischen Tricks.
Grenzen: Gemischte Sprachanfragen in einem einzelnen Bild tendierten manchmal zu einer Sprache für den gerenderten Text. Ich konnte es mit expliziten Anweisungen lenken (z. B. „Titel auf EN, Untertitel auf ZH”), aber es ist nicht perfekt. Dennoch ist es für zweisprachige Workflows eine der unkomplizierteren Erfahrungen, die ich gemacht habe.
Native Textwiedergabe in Bildern
 Das ist der Grund, warum ich geblieben bin. Text sieht meistens wie Text aus: gerade Baselines, erkennbare Schriften und Zeichen, die milde Stiländerungen überstehen. Ich warf häufige Ausfallszenarien dagegen: gekrümmte Beschilderung, kleine Fußzeilen, Pseudo-UI-Beschriftungen. Es hielt besser als die üblichen Open-Source-Modelle, die ich nutze, besonders bei bescheidenen Größen. Keine Magazin-Cover-Typografie, aber gut genug, dass ich aufhörte, jedes Mal zu maskieren und zu compositen.
Das ist der Grund, warum ich geblieben bin. Text sieht meistens wie Text aus: gerade Baselines, erkennbare Schriften und Zeichen, die milde Stiländerungen überstehen. Ich warf häufige Ausfallszenarien dagegen: gekrümmte Beschilderung, kleine Fußzeilen, Pseudo-UI-Beschriftungen. Es hielt besser als die üblichen Open-Source-Modelle, die ich nutze, besonders bei bescheidenen Größen. Keine Magazin-Cover-Typografie, aber gut genug, dass ich aufhörte, jedes Mal zu maskieren und zu compositen.
Eine kleine praktische Anmerkung: kurze, präzise Text-Prompts funktionieren am besten. Lange Absätze werden immer noch unscharf. Wenn du schweren Text in ein Bild designst, wirst du wahrscheinlich immer noch ein Layout-Tool wollen. Aber für Logos, Tags, Banner und einfache UI-Mockups machte Z-Image-Turbo den „just render it here”-Weg praktikabel.
16-GB-VRAM-Kompatibilität
Ich habe es auf einer 16-GB-GPU ohne Sharding oder einen halben Tag Abhängigkeits-Bingo ausgeführt. 768px-Quadrat-Bilder funktioniert: 1024px brauchte etwas mehr Geduld und die richtigen Präzisions-Einstellungen, aber immer noch in Ordnung. Für mich zählt das mehr als eine fancyDemo. Wenn sich das Modell auf einer gemeinsamen Laptop-GPU gut verhält, kann ich es in meiner alltäglichen Schleife behalten, statt eine separate Maschine hochzufahren.
Wenn du 8–12 GB hast, musst du möglicherweise die Auflösung reduzieren oder dich auf die API verlassen. Wenn du 24 GB+ hast, bekommst du mehr Raum für große Formate, aber der Kernwert des Modells – schnelle, textstabile Ergebnisse – zeigt sich auch bei kleineren Größen.
Benchmark-Leistung
Benchmarks sind nicht die Arbeit, aber sie helfen, die Eindrücke zu überprüfen.
#1 Open-Source auf der Artificial-Analysis-Rangliste
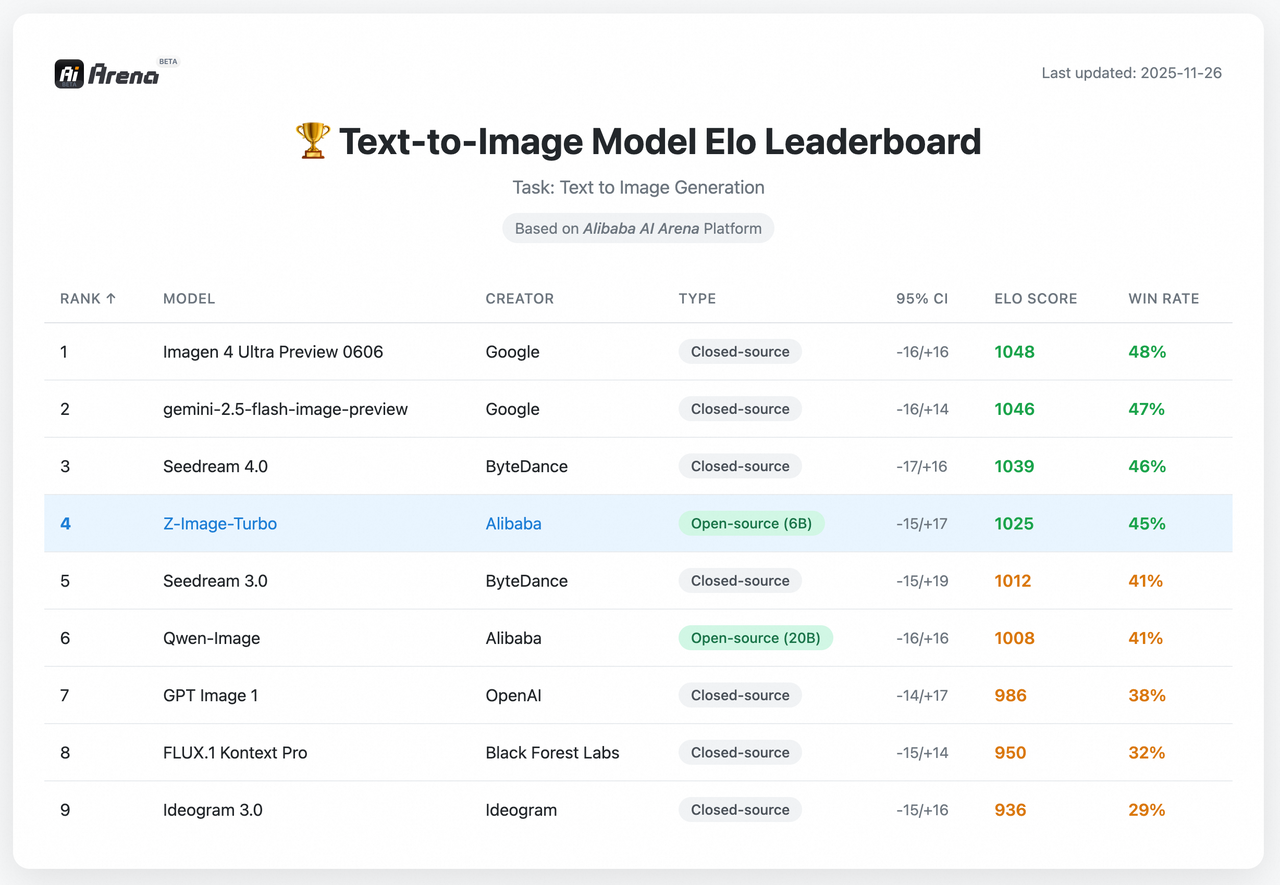 Seit Anfang Februar 2026 ist Z-Image-Turbo oben oder nahe der Spitze unter Open-Source-Bildmodellen auf der Artificial-Analysis-Rangliste gelistet (Rangplatzierungen verschieben sich, daher behandle dies als Schnappschuss). Das stimmt mit dem überein, was ich fühlte: Geschwindigkeit und Textgenauigkeit scheinen seine Stärken zu sein. Ranglisten messen nicht alles, aber sie sind ein nützlicher Proxy dafür, wie ein Modell über eine kurierte Demo hinaus verallgemeinert.
Seit Anfang Februar 2026 ist Z-Image-Turbo oben oder nahe der Spitze unter Open-Source-Bildmodellen auf der Artificial-Analysis-Rangliste gelistet (Rangplatzierungen verschieben sich, daher behandle dies als Schnappschuss). Das stimmt mit dem überein, was ich fühlte: Geschwindigkeit und Textgenauigkeit scheinen seine Stärken zu sein. Ranglisten messen nicht alles, aber sie sind ein nützlicher Proxy dafür, wie ein Modell über eine kurierte Demo hinaus verallgemeinert.
Wie es sich mit geschlossenen Modellen vergleicht
Gegenüber den großen gehosteten Modellen tauscht Z-Image-Turbo Spitzenfoto-Realismus gegen Geschwindigkeit, Kosten und kontrollierbaren Text. Wenn du glossy, kinematische Szenen mit ausgefeilter Beleuchtung willst, haben einige geschlossene Optionen immer noch einen Vorsprung. Wenn du ein sauberes Graphic mit lesbaren Wörtern in zwei Minuten willst, behält dieses sein Gleichgewicht. Ich bemerkte auch, dass weniger Prompt-Gymnastik nötig war, um die Typografie intakt zu halten, weniger Versuche, mehr Outcome. Für kleine Teams oder Solo-Creator ist diese Balance normalerweise der Unterschied zwischen „nettes Experiment” und „das wird heute versendet”.
Wer sollte Z-Image-Turbo verwenden?
Ideale Anwendungsfälle
- Social-Graphics mit kurzem, lesbarem Text (Ankündigungen, Banner, Thumbnails)
- Produkt-Mockups und einfache UI-Szenen, bei denen Beschriftungen überleben müssen
- Interne Dokumente und Folien, die von schnellen Visuals profitieren, ohne einen Design-Umweg
- Zweisprachige Assets, bei denen Prompt-Sprachenflexibilität Hin- und Hergespräche spart
- Schnelle Iteration in Sprints, wenn du 3–5 anständige Varianten schnell haben und weitermachen willst
In meinen Tests war der Gewinn nicht nur rohe Geschwindigkeit. Es war Vorhersagbarkeit. Ich konnte Stil oder Layout anpassen, ohne den Text völlig zu verlieren, was weniger Neustarts bedeutete.
Wann man lieber andere Modelle wählt
- Hochwertige Fotorealismus für großformatige Drucke oder Anzeigen – einige geschlossene Modelle liefern immer noch ein polishtes Finish.
- Lange Absätze oder komplexe Typografie-Systeme – nutze ein Layout-Tool oder Nachbearbeitung.
- Schweres Compositing oder Multi-Bild-Konsistenz (derselbe Charakter über Szenen hinweg) – du wirst ein Modell mit starker Identität und Multi-Shot-Kontrollen wollen.
Wenn deine Arbeit zu kinematischem Storytelling oder aufwändigen Beleuchtungsstudien neigt, bevorzugst du möglicherweise ein anderes Tool. Z-Image-Turbo ist eher ein alltäglicher Fahrer als ein Show-Auto.
So kommen Sie los
WaveSpeed-API-Schnelleinstieg
Ich versuchte zuerst die WaveSpeed-API, um Setup-Drift zu vermeiden. Die Authentifizierung war Standard, und der Request-Body war einfach: Prompt, Schritte (ich blieb bei 8), Größe und ein Seed, wenn du Reproduzierbarkeit willst. Die Standardwerte waren sinnvoll. Wenn du Textwiedergabe testest, fang mit kurzen Phrasen und mittlerer Auflösung an, dann skaliere hoch, sobald dir der Look gefällt. Ich ging von der Idee zum ersten brauchbaren Bild in unter fünf Minuten – der schnellste Teil dieses ganzen Experiments.
Wenn du lokal bevorzugst, lief das Modell sauber auf einer 16-GB-GPU mit typischen Präzisions-Einstellungen. Behalte VRAM im Auge, während du 768px kreuzt. Wenn du auf Grenzen stößt, reduziere Schritte, bevor du Guidance reduzierst: 8-Schritt-Sampling ist der Punkt hier.
Preis-Übersicht ($0,005/Bild)
 Über WaveSpeed betrug die Preisgestaltung etwa $0,005 pro Bild bei Standardeinstellungen. Das ist schwer zu kritisieren für Entwürfe, Social Assets oder schnelle Experimente. Wenn du großflächig generierst, achte auf Parallelitätsgrenzen – die Latenz blieb für mich mit kleinen Bursts niedrig, aber ich testete nicht über eine Handvoll paralleler Jobs hinaus.
Über WaveSpeed betrug die Preisgestaltung etwa $0,005 pro Bild bei Standardeinstellungen. Das ist schwer zu kritisieren für Entwürfe, Social Assets oder schnelle Experimente. Wenn du großflächig generierst, achte auf Parallelitätsgrenzen – die Latenz blieb für mich mit kleinen Bursts niedrig, aber ich testete nicht über eine Handvoll paralleler Jobs hinaus.
Das funktionierte für mich, deine Erfahrung kann anders ausfallen. Wenn du zweisprachige Prompts jonglierst oder einfach nur Text willst, der im Bild seinen Platz hat, lohnt sich ein Blick. Das letzte, das ich bemerkte – fast zufällig: Ich hörte auf, immer wieder Screenshots zu machen und zu bearbeiten. Weniger Umwege. Das fühlte sich wie der Sinn an.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
