WaveSpeed API Preisgestaltung: Wie Credits funktionieren + Ein einfacher Kostenrechner

Hallo, erinnert ihr euch an mich? Ich bin Dora.
Ich wollte mich ursprünglich nicht mit Pricing auseinandersetzen. Ich wollte einfach einen ruhigen Nachmittag zum Testen. Aber in der Mitte des Aufbaus eines kleinen Prototyps (Januar 2026) begannen meine Notizen von “funktioniert das?” zu “was kostet das, wenn es wirklich in die Produktion geht?” abzudriften. Das ist normalerweise der Moment, in dem ich innehalte. WaveSpeed API Pricing ist nicht glänzend. Es ist die Art, die sich in den Ecken versteckt: Kontextgröße, Wiederholungen, Datengröße. Nichts davon ist dramatisch, aber es summiert sich. Hier ist, wie ich es kalkuliert habe, mit echten Zahlen, wo ich kann, und einfachen Schätzungen, wo nicht. Wenn ihr wie ich arbeitet und kleine Experimente ausliefert, die möglicherweise wachsen, könnte das euch helfen, zu planen, ohne zu raten.
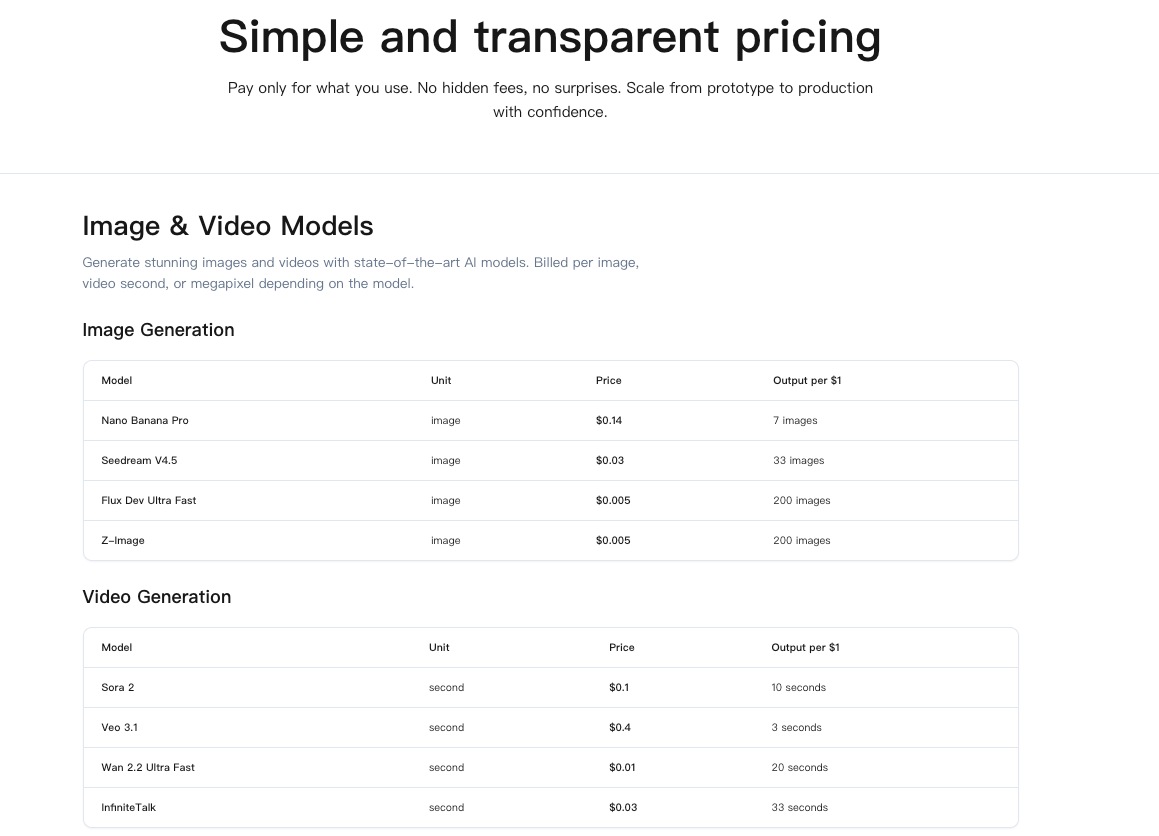
Wie Pricing gemessen wird
Ich konnte keine einzelne Zahl finden, die das WaveSpeed API Pricing sauber darstellt. Also behandle ich es als drei Bereiche:
- Basis-Aufruf: die Gebühr für einen einmaligen Endpunkt-Hit. Stellt euch das als “Eintrittsgebühr” vor.
- Variable Arbeitslast: der Teil, der mit dem wächst, was ihr sendet und verlangt: Tokens, Dateigröße, Modellstufe, verwendete Tools, Kontextlänge.
- Extras: Speicher, Daten-Egress und alles, was Daten persistiert oder nach außen bewegt.
Für die Planung verwende ich eine einfache Formel:
Geschätzter Preis = (Läufe × Basis_pro_Aufruf) + (Eingabevolumen × Satz_ein) + (Ausgabevolumen × Satz_aus) + (Speicherdaten × Speichersatz × Monate) + (Egress_GB × Egress_Satz)
Es ist langweilig, was ist warum es funktioniert. Ich speichere Sätze in einem kleinen Sheet und passe sie an, wenn sich die Docs ändern. Wenn ihr das auch macht, setzt ein Lesezeichen auf die offiziellen Pricing- und Limits-Seiten: sie ändern sich oft, und kleine Änderungen dort wirken sich auf alles andere aus.
Faktoren, die Kosten multiplizieren
Einige Dinge erhöhen die Gesamtsummen leise. Keine davon sind allein “Fallstricke”. Zusammen sind sie der Grund, warum Budgets abweichen.
- Lange Prompts und großzügige Outputs: Jedes extra 1k Token zeigt sich auf der Rechnung. Ich setze max Output Tokens, es sei denn, es gibt einen Grund, nicht zu.
- Wiederholungen und Fallbacks: Solide für Zuverlässigkeit, rau bei den Kosten, wenn sie offen gelassen werden. Ich verwende exponentielles Backoff mit einer festen Obergrenze.
- Große Dateien: Transkription, Vision oder PDF-Parsing wird teuer, wenn ihr große Assets werft. Ich reduziere die Auflösung oder unterteile.
- Tooling-Ketten: Eine Benutzeraktion kann sich zu mehreren API-Aufrufen ausweiten. Es ist leicht zu vergessen, dass jeder Tool-Schritt ein weiterer billbarer Lauf ist.
- Concurrency: Parallelismus ist großartig für Latenz, multipliziert aber die Kosten während Lasttests. Ich erhöhe es spät, nicht früh.
- Logging und Captures: Hilfreich zum Debuggen. Teuer, wenn ihr alles für immer speichert. Ich halte strukturierte Logs dünn und rotiere aggressiv.
Wenn ihr nichts anderes messt, messt Tokens, Dateigrößen und Wiederholungszähler. Diese drei erklären die meisten Überraschungen für mich.
3 reale Szenarien (10 / 50 / 100 Läufe)
Das sind keine offiziellen Zahlen. Das sind meine Planungsschätzungen aus einem Januar-2026-Prototyp. Tauscht eure eigenen Sätze aus: die Form sollte halten.
Angenommene Platzhaltersätze (nur für Mathematik):
- Basis pro Aufruf: $0,002
- Eingabe-Tokens: $0,50 pro 1M Tokens ($0,0005 pro 1k)
- Ausgabe-Tokens: $1,00 pro 1M Tokens ($0,001 pro 1k)
- Speicher: $0,02 pro GB-Monat
- Egress: $0,09 pro GB
Szenario A: kurzer Prompt → kurze Antwort
- Durchschnittliche Eingabe: 600 Tokens; Ausgabe: 200 Tokens; keine Dateien.
- Pro Lauf: Basis $0,002 + Eingabe (0,6k × $0,0005 = $0,0003) + Ausgabe (0,2k × $0,001 = $0,0002) = $0,0025
- 10 Läufe ≈ $0,025; 50 Läufe ≈ $0,125; 100 Läufe ≈ $0,25
Wie es sich anfühlte: praktisch kostenlos, bis Wiederholungen eintraten. Als ich 3 Wiederholungen erlaubte, verdoppelten sich die Kosten fast während einer fehlerhaften Stunde. Ich hielt bei 1 Wiederholung an und setzte den Rest in die Warteschlange.
Szenario B: Zusammenfassung einer mittleren PDF
- Durchschnittliche Eingabe: 6.000 Tokens aus aufgeteiltem Text; Ausgabe: 1.000 Tokens.
- Pro Lauf: Basis $0,002 + Eingabe (6k × $0,0005 = $0,003) + Ausgabe (1k × $0,001 = $0,001) = $0,006
- 10 Läufe ≈ $0,06; 50 Läufe ≈ $0,30; 100 Läufe ≈ $0,60
Hinweis: die versteckten Kosten hier waren Extraktion. Als ich vollständige PDFs statt sauberer Text-Chunks sendete, addierte der Vorbereitungsschritt Zeit hinzu und manchmal einen zweiten Aufruf. Text zuerst war billiger und vorhersehbarer.
Szenario C: leichte Vision + Zusammenfassung + Export
- Bild: durchschnittlich 1,5 MB; Eingabe 2.000 Tokens; Ausgabe 500 Tokens; Ergebnis für 1 Monat speichern; insgesamt 0,5 GB über Läufe exportieren.
- Pro Lauf (API): Basis $0,002 + Eingabe (2k × $0,0005 = $0,001) + Ausgabe (0,5k × $0,001 = $0,0005) = $0,0035
- Speicher: wenn jedes Ergebnis ~200 KB Artefakte hinzufügt, 100 Läufe ≈ 20 MB = 0,02 GB × $0,02 ≈ $0,0004/Monat (vernachlässigbar)
- Egress: 0,5 GB × $0,09 = $0,045 insgesamt über den Batch
- 10 Läufe ≈ $0,035 + winziger Speicher; 50 Läufe ≈ $0,175 + Egress wenn ihr exportiert; 100 Läufe ≈ $0,35 + ~$0,045 Egress
Was mich überraschte: Egress war die einzige Zeile, die ich fühlte. Nicht riesig, aber bemerkbar, wenn ich Medien für Clients exportierte.
An einem bestimmten Punkt wollte ich nicht mehr schätzen und wollte einfach, dass die Dinge vorhersehbar bleiben. Das ist der Grund, warum wir WaveSpeed gebaut haben — um Experimente wie diese durchzuführen, ohne ständig Token-Counts, Wiederholungen oder überraschende Egress-Zeilen zu beobachten.
Wenn ihr Ideen stress-testet, die skalieren könnten, probiert es aus.
Cost-Calculator-Tabelle
Ich halte ein winziges Arbeitsblatt. Es ist nicht schick, nur ehrliche Mathematik. Wenn ihr eine schnelle Skizze möchtet, gebt eure Zahlen in dieses Muster ein.
| Läufe | Basis/Aufruf ($) | Input-Tokens/Lauf | Output-Tokens/Lauf | Satz ein ($/1k) | Satz aus ($/1k) | Egress (GB) | Egress $/GB | Geschätzter Gesamtpreis ($) |
|---|---|---|---|---|---|---|---|---|
| 10 | 0,002 | 600 | 200 | 0,0005 | 0,001 | 0 | 0,09 | (10×0,002) + (10×0,6×0,0005) + (10×0,2×0,001) + (0×0,09) |
| 50 | 0,002 | 6000 | 1000 | 0,0005 | 0,001 | 0 | 0,09 | (50×0,002) + (50×6×0,0005) + (50×1×0,001) |
| 100 | 0,002 | 2000 | 500 | 0,0005 | 0,001 | 0,5 | 0,09 | (100×0,002) + (100×2×0,0005) + (100×0,5×0,001) + (0,5×0,09) |
Hinweis: Ersetzt die Platzhaltersätze durch die aktuellen Zahlen von WaveSpeed’s Pricing-Seite. Ich halte Versionen im Sheet, nur eine Datumsspalte, damit ich mich erinnere, was sich geändert hat und wann.
Wie man Verschwendung reduziert
Was mir am meisten geholfen hat, war nicht Magie, nur Leitplanken, die hielten:
- Max-Output-Tokens setzen. Lange Antworten sind schön: vorhersehbare Rechnungen sind schöner.
- Prompts trimmen. System-Prompts wiederverwenden und Referenz-IDs verwenden, statt Textmauern einzufügen.
- Zwischenergebnisse cachen. Nicht erneut einbetten oder unveränderte Inhalte zusammenfassen.
- Batch wo sicher. Zehn kleine Aufrufe können billiger sein als einer großer, oder umgekehrt. Testet beide.
- Dateien richtig bemessen. Bilder mit reduzierter Auflösung, Text aus PDFs extrahieren, bevor ihr sie sendet.
- Wiederholungen und Timeouts kappen. Zuverlässigkeit ist gut: Endlosschleifen sind nicht.
- Sparsam loggen. Hashes und IDs behalten: rohe Payloads ablegen, es sei denn, ihr braucht sie wirklich.
Team-Billing-Tipps

Ich bin mehrmals über Team-Kosten gestolpert. Ein paar Gewohnheiten sparten mir:
- Separate Keys pro Umgebung und Projekt. Macht die Zuordnung offensichtlich.
- Anfragen mit Benutzer- oder Feature-IDs taggen. Kosten pro Feature nach dem Facto ist Gold bei der Planung.
- Gemeinsames Dashboard mit wöchentlichen Snapshots. Niemand liest täglich Geräusch.
- Soft Budgets auf Projektebene. Wenn 80% erreicht sind, verlangsamen sich Features oder wechseln zu einem billigeren Pfad.
- Eine Person besitzt Pricing-Updates. Nicht um zu kontrollieren, sondern um Drift zu reduzieren.
- Runbook führen: Was zuerst drosseln, wenn Kosten spitzen (Output-Tokens, Concurrency oder optionale Tools).
Budget-Leitplanken
Hier ist, was ich vor allem einsetzte, was echter Benutzer gegenübersteht:
- Preflight-Schätzer: eine kleine Funktion, die geschätzte Kosten pro Aktion berechnet und zu Logs hinzufügt.
- Pro-Aktion Obergrenzen: wenn ein einzelner Lauf über $X projiziert, lehnt er höflich ab.
- Täglich und monatlich Obergrenzen mit Alerts. Alerts gehen auf einen ruhigen Kanal, den jemand wirklich beobachtet.
- Slow Mode: ein Flag, das Concurrency unter Budgetdruck halbiert.
- Feature Flags für schwere Pfade: Vision oder Long-Context-Features deaktivieren, ohne umzusetzen.
- Review Kadenz: 15 Minuten jeden zweiten Freitag, um Sätze von der offiziellen Pricing-Seite zu aktualisieren.

Ehrlich gesagt ist nichts davon glamourös. Aber WaveSpeed API Pricing verhält sich, wenn ihr das tut. Das Lustige ist, dass die Leitplanken einmal gesetzt sind, das Tool wieder in den Hintergrund verblasst, genau wo ich es mag.
Ich ertappe mich immer noch dabei, wie ich die Token-Counts aus Gewohnheit überprüfe, dann das Tab schließe, wenn die Zahlen angemessen aussehen. Alte Gewohnheiten. Kleine Erleichterungen. Ich nehme es.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
