LTX-2 Modell herunterladen: Hugging Face Dateien, Größen & Ordnerstruktur

Das erste Mal, als ich nach einem LTX-2-Download suchte, war es kein großer Plan. Ich wollte nur einen kleinen Batch durch ComfyUI laufen lassen und stieß immer wieder auf die gleichen zwei Probleme: langsame Downloads, die bei 92% hängenblieben, und eine kryptische Fehlermeldung „Model not found”, sobald ich die Dateien endlich hatte. Nichts Dramatisches. Nur die Art von wiederkehrenden Problemen, die dich dazu bringen, innezuhalten und den Workflow zu ordnen.
Ich verbrachte ein paar Abende in der ersten Januarwoche 2026 damit, verschiedene Quellen, Formate (NVFP4 vs. NVFP8) und Ordnerlayouts auf einer 24-GB-GPU-Box zu testen. Nichts Spektakuläres, nur genug Durchläufe, um zu sehen, was solide war und was fragil. Hier ist der Weg, der das Chaos für mich reduziert hat – mit Notizen, die du überfliegen und übernehmen kannst.
Offizielle LTX-2-Download-Quellen (Hugging Face Model Card)
 Ich jage nicht hinterher Spiegeln. Wenn ein Modell für meinen Workflow wichtig ist, soll die Spur langweilig und zuverlässig sein. Für LTX-2 bedeutet das, mit der offiziellen Hugging Face Model Card zu beginnen.
Ich jage nicht hinterher Spiegeln. Wenn ein Modell für meinen Workflow wichtig ist, soll die Spur langweilig und zuverlässig sein. Für LTX-2 bedeutet das, mit der offiziellen Hugging Face Model Card zu beginnen.
Auf das achte ich, bevor ich auf Download klicke:
- Herausgeber: Ist es die verifizierte Organisation oder der Autor hinter LTX-2? Ich überprüfe das Org-Badge und dass andere Repos im Namespace aktiv und konsistent aussehen.
- Lizenz & Bedingungen: Einige LTX-2-Varianten sind gated oder haben Nutzungsbeschränkungen. Wenn das Akzeptieren von Bedingungen einen Token erfordert, bevorzuge ich, das einmal zu tun, statt später Authentifizierungsfehler zu debuggen.
- Artifacts-Liste: Ich scanne nach dem Hauptmodell, eventuellen Encodern und einer destillierten oder quantisierten Variante. Klare Dateinamen sind besser als raffinierte.
- Anweisungen: Wenn die Card auf ComfyUI oder node-spezifische Dokumentation verlinkt, folge ich diesen zuerst. Eine Zeile über erwartete Ordner kann eine halbe Stunde Raterei sparen.
Praktischer Tipp: Nutze die Hugging Face CLI mit gesetzten Anmeldedaten. Ein gated Repo wird über raw git-lfs ohne Token nicht gepullt, und das ist der schnellste Weg, mit Teildateien und keinem Fehler bis zur Ausführung zu enden.
pip install huggingface_hub git-lfs
huggingface-cli login # dein Token einfügenIch weiß, offensichtlich. Aber die Anzahl der Male, die ich ein stilles 403 in „model not found” umwandeln sah – nicht Null.
Dateiliste & Größen (Hauptmodell / Encoder / Destilliert)
Ich memoriere Dateigröße nicht. Ich brauche nur eine ungefähre Vorstellung, um Speicherplatz zu planen und zu entscheiden, welche Variante ich zuerst hole. Hier ist, was ich tatsächlich über die letzten LTX-2-Drops gesehen habe. Dein Repo kann anders sein, vertraue immer der Model Card mehr als meinen Notizen.
Typische Artifacts, die du sehen wirst:
- Hauptmodell-Checkpoint (oft
.safetensorsoder ein runtime-spezifisches Format): ~2,5–6,0 GB. Größer, wenn es zusätzliche Heads oder Multi-Präzision enthält; kleiner, wenn quantisiert. - Text-/Bild-Encoder (CLIP oder ähnlich): ~400 MB–1,5 GB. Einige Builds bündeln dies; andere versenden es als separate Datei.
- VAE oder latentes Adapter (falls zutreffend): ~100–500 MB.
- Destillierte Variante: ~1–3 GB. Schneller und leichter, manchmal mit etwas weicheren Outputs. Gut zum Prototyping.
- Quantisierte Varianten (NVFP8/NVFP4): Größe variiert, aber erwarte 30–60% weniger Speicherplatz als volle Präzision.
Benennungsmuster, auf die ich achte:
ltx-2.safetensors(Haupt)ltx-2-encoder.safetensorsoderopen_clip-vit-…(Encoder)ltx-2-vae.safetensors(falls separat)ltx-2-distilled-…(kleiner, schneller)ltx-2-nvfp8/ltx-2-nvfp4(format-spezifisch)
Wenn der Speicherplatz begrenzt ist, hole ich zuerst die destillierte Variante, validiere meine Pipeline, dann pullt dann das Vollmodell. Es geht nicht nur um Geschwindigkeit: Die Reduzierung der kognitiven Last beim ersten Durchlauf hilft mir, Prompts und Nodes zu testen, ohne sofort mit VRAM zu kämpfen.
ComfyUI-Ordnerstruktur für LTX-2 (Exakte Pfade)
Hier bin ich am ersten Tag gestolpert: Meine Dateien waren okay, aber ComfyUI wusste nicht, wo es schauen sollte. Verschiedene Custom Nodes erwarten leicht unterschiedliche Positionen, aber die Defaults unten waren für mich sicher.
Bei einer Standard-ComfyUI-Installation (keine Custom-Node-Overrides):
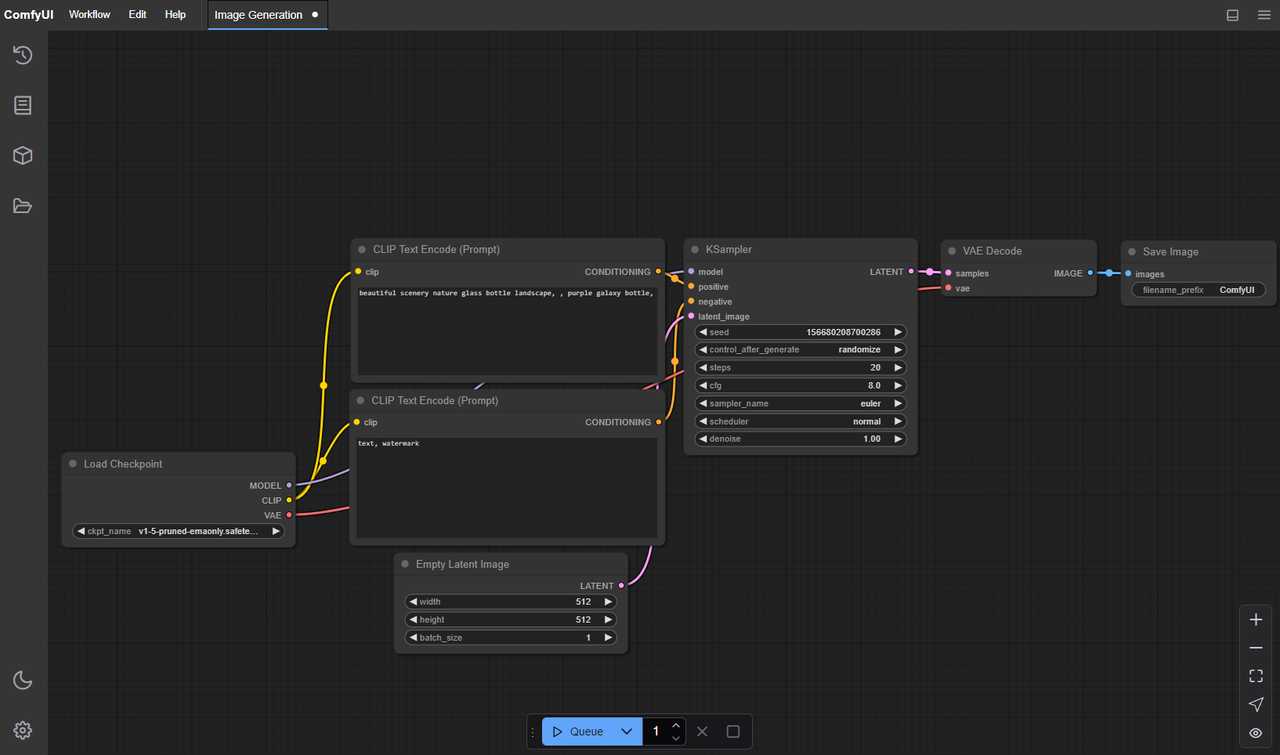
- Hauptmodell-Checkpoint:
ComfyUI/models/checkpoints/LTX-2.safetensors - Text-/Bild-Encoder (CLIP oder ähnlich):
ComfyUI/models/clip/LTX-2-encoder.safetensors- Einige Builds verwenden open_clip-Benennungen: Lege auch diese in
models/clip/ab.
- Einige Builds verwenden open_clip-Benennungen: Lege auch diese in
- VAE (falls separat):
ComfyUI/models/vae/LTX-2-vae.safetensors - LoRA/Patches (falls du sie nutzt):
ComfyUI/models/loras/
Wenn du Nodes verwendest, die auf TensorRT oder Engine-Dateien angewiesen sind:
ComfyUI/models/trt/ltx-2/*.engineComfyUI/models/unet/ltx-2/*.engine
Zwei langweilig, aber nützliche Gewohnheiten:
- Dateinamen genau auf das abstimmen, was dein Node erwartet. Ich halte Namen kurz und entferne Leerzeichen.
- Nach dem Verschieben von Dateien ComfyUI’s Modell-Refresh verwenden oder neu starten. Hot Reload funktioniert manchmal: ein vollständiger Neustart ist konsistenter.
Wenn du eine externe Festplatte oder einen freigegebenen Modelle-Ordner verwendest, stelle ComfyUI’s Extra Model Paths ein, damit es nicht stillschweigend das falsche Laufwerk durchsucht. Groß-/Kleinschreibung unter Linux hat mir mehr als einmal Probleme bereitet.
NVFP4 vs. NVFP8 Gewichte: Welche sollte ich herunterladen?
 Ich war neugierig, ob NVFP4 die zusätzliche Kompression wert ist. Kurze Antwort: vielleicht, wenn du bei VRAM knapp bist und deine Nodes es tatsächlich unterstützen.
Ich war neugierig, ob NVFP4 die zusätzliche Kompression wert ist. Kurze Antwort: vielleicht, wenn du bei VRAM knapp bist und deine Nodes es tatsächlich unterstützen.
Hier ist, wie es sich auf meiner Box anfühlte (Hopper-Klasse GPU, Januar 2026 Builds):
NVFP8
- Balance: Guter Mittelweg. Deutlich weniger Speicher als volle Präzision mit minimalem Output-Drift.
- Kompatibilität: Besser. Mehr Nodes und Runtimes akzeptieren FP8 als FP4 im Moment.
- Wann ich es wähle: Tägliche Durchläufe, wenn ich Stabilität über dem kleinsten Footprint möchte.
NVFP4
- Footprint: Kleiner. Es ließ mich Auflösung oder Kontext ein bisschen erhöhen, wo FP8 nicht würde.
- Drift: Etwas mehr Artefakte oder Weichheit bei Grenzfällen. Nicht immer, aber gerade genug, dass ich es merke.
- Kompatibilität: Wählerischer. Einige Loader fallen zurück oder schlagen fehl, wenn sie die richtigen Kernel nicht erkennen.
- Wann ich es wähle: Schnelle Entwürfe, Grid-Suchen oder wenn der Workflow streng vom FP4-Pfad des Nodes unterstützt wird.
Noch etwas: Diese Formate setzen normalerweise voraus, dass du auf einem NVIDIA-Stack bist, der sie richtig beschleunigen kann. Wenn dein Node nicht explizit „NVFP4/NVFP8 unterstützt” sagt, greife ich auf volle Präzision oder einen destillierten .safetensors-Build zurück. Marginale Gewinne zu verfolgen ist nicht das Risiko eines rätselhaften Absturzes mitten im Rendering wert.
LTX-2-Download-Beschleunigung & Checksum-Verifikationstipps
Ich behandle große Modell-Pulls wie jeden anderen großen Dateijob: Beschleunige ihn, dann verifiziere.
Beschleunigung, die wirklich geholfen hat:
- Hugging Face Transferbeschleunigung: Setze env var
HF_HUB_ENABLE_HF_TRANSFER=1, bevor duhuggingface_hubnutzt. Dies schaltet ihren beschleunigten Backend ein, wo verfügbar.
aria2c für parallele Chunks:
aria2c -x 16 -s 16 -k 1M -cDas -c Flag setzt Teildownloads sauber fort, wenn meine Verbindung bei 97% hängengelebt.
git-lfs abgestimmte Pulls
git lfs installdanngit clone.- Nach dem Git LFS Installationshandbuch verwende ich manchmal Sparse-Checkout, um zu vermeiden, dass ich Beispiele pullt, die ich nicht nutze.
Verifikation, die ich mache (und nicht mehr überspringe)
Vergleiche SHA256 von der Model Card (oder der .sha256-Dateien des Repos) gegen deine lokale Datei.
- macOS/Linux:
shasum -a 256 - Windows:
certutil -hashfile SHA256
Dateigröße-Sanity-Check
- Wenn die erwartete Größe 4,2 GB ist und ich sehe 3,3 GB, stoppe ich dort. Teildateien laden manchmal, werfen dann später Müll-Fehler.
Kleine Gewohnheit, die Zeit spart: Ich behalte ein winziges README.txt neben den Modelldateien mit der Herkunfts-URL, Datum und Hash. Wenn ich drei Monate später zurückkomme, muss ich nicht meiner Vergangenheit’s Entscheidungen rückwärts machen.
„Model Not Found”-Fixes
Dieser Fehler aß eine Stunde, die ich nicht zurückbekomme. Hier sind die Fixes, die den Unterschied für mich gemacht haben:
- Falscher Ordner: ComfyUI erwartet Checkpoints in
models/checkpoints/, Encoder inmodels/clip/und VAEs inmodels/vae/. Lege sie wo anders hin und der Scanner kann sie ignorieren. - Dateinamen-Mismatch: Einige Nodes suchen nach einem spezifischen Basis-Namen. Wenn der Node
ltx-2.safetensorssagt, nenne es nichtLTX-2 (final).safetensors. Ich benenne aggressiv. - Groß-/Kleinschreibung:
ltx-2.safetensors≠LTX-2.safetensorsunter Linux. Frag mich, wie ich das weiß. - Cache-Indizierung: Modelle aktualisieren oder ComfyUI nach dem Verschieben von Dateien neu starten. Der Index ist nicht immer Echtzeit.
- Fehlende Abhängigkeit: Wenn der Node einen externen Encoder erwartet und du nur das Hauptmodell heruntergeladen hast, bekommst du einen vagen Fehler. Pullt den Encoder von der Model Card und versuch nochmal.
- Gated Modell ohne Token: Wenn du geklont hast, ohne dich anzumelden (oder dein Token ist abgelaufen), können lokale Dateien Stubs sein. Re-login mit
huggingface-cli loginund re-pull. - Custom Nodes und alternative Pfade: Einige Nodes overriden Standard-Ordner. Überprüfe ihr README für erwartete Pfade oder env vars. Im Zweifelsfall erstelle einen symbolischen Link von deinem freigegebenen Modelle-Dir zum erwarteten lokalen Pfad.
Wenn ich steckenbleibe, zeige ich den Node temporär auf ein bekanntes, winziges Modell, um zu bestätigen, dass der Loader funktioniert. Wenn die kleine lädt, lebt der Bug in den LTX-2-Dateien, nicht in meiner Umgebung.
LTX-2-Downloads über WaveSpeed überspringen
Ich versuchte eine andere Route auf einem Reise-Laptop: Überspringe lokale Downloads ganz und führe LTX-2 durch WaveSpeed aus. Es streamt oder hostet die Gewichte remote, damit du einen ComfyUI-ähnlichen Graph verdrahten kannst, ohne 10+ GB auf deine Festplatte zu parken.
 Was für mich funktionierte:
Was für mich funktionierte:
- Das Onboarding war leicht. Ich zeigte den Graph auf ihren LTX-2-Endpoint und rührte keine lokalen Ordner an.
- Kaltstarts waren langsamer (erster Durchlauf spult eine Session auf), aber warme Durchläufe fühlten sich normal für kleine Batches an.
- Es hielt meinen Laptop-Lüfter davon ab, zu heulen. Das alleine machte es auf Reisen nützlich.
Trade-offs, die ich bemerkte:
- Latenz: Es gibt einen kleinen Overhead, bei vielen kurzen Durchläufen offensichtlicher. Für lange Renders habe ich aufgehört, es zu bemerken.
- Kontrolle: Du gibst etwas Versions-Pinning auf. Sie halten Modelle gepatcht, was nett ist, bis du ein älteres Ergebnis reproduzieren möchtest.
- Kosten/Quoten: Es ist nicht „kostenlos wie ein Download”. Wenn du ein knappes Budget hast oder schwere Batch-Arbeit brauchst, gewinnt lokal immer noch.
- Datenschutz: Ich halte sensible Prompts und Assets lokal. Für öffentliche oder Test-Arbeit bin ich okay damit.
Wer könnte das mögen: Leute, die LTX-2 auf unterpowered Maschinen testen, oder jeder, der einen Workflow skizzieren möchte, bevor er sich auf ein vollständiges lokales Setup einigt. Wenn du VRAM-reich bist und um exakte Reproduzierbarkeit sorgst, fühlen sich lokale Installs immer noch besser an.
Ich habe nicht erwartet, es zu mögen, aber für schnelle Experimente war das Überspringen des Downloads eine kleine Erleichterung.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung
