LTX-2 in ComfyUI unter Windows installieren: CUDA-Setup & Erste-Schritte-Anleitung

Hallo, ich bin Dora. An jenem Tag wollte ich nur schnell einen Text-to-Video-Pass für eine Skizze machen, und ich sah ständig LTX‑2 in ComfyUI-Foren erwähnt. Am späten Vormittag starrte ich auf einen leeren Graph und einen Ordner namens “ltx” und fragte mich, ob ich mich gerade erneut für Treiber-Roulette angemeldet hatte.
Ich machte mir Notizen, während ich es auf Windows 11 einrichtete. Falls du nach “ltx‑2 comfyui windows” suchst, weil du gerade mittendrin bist, bin ich da gewesen. Hier ist, was mir geholfen hat.
Checkliste vor der Installation (GPU / CUDA / Treiberversionen)
Ein schneller Check, bevor du anfängst, erspart dir die Stunde, die du später mit DLL-Fehlern verbringst:
- GPU: Eine NVIDIA-Karte mit mindestens 12 GB VRAM machte LTX‑2 für mich bei bescheidenen Einstellungen nutzbar (512–768 Breite, kurze Clips). 8 GB können mit sehr konservativen Einstellungen funktionieren, aber es ist eng und oft frustrierend.
- Treiber: Aktualisiere auf einen aktuellen Game Ready oder Studio Treiber (ich habe 552.xx verwendet).
- CUDA: Du installierst keinen vollständigen CUDA Toolkit für ComfyUI Portable. Du brauchst nur die Runtime-DLLs, die mit PyTorch mitgeliefert werden. Deshalb ist es wichtig, den PyTorch+CUDA Build zu beachten (cu121 oder cu122, usw.).
- Python: Der ComfyUI Portable Build wird mit eigenem Python geliefert. Falls du ein benutzerdefiniertes venv laufen lässt, halte es mit dem PyTorch-Wheel abgestimmt, das du wählst.
- VC++ Redistributable: Installiere oder repariere das neueste Microsoft Visual C++ Redistributable. Es ist eine stille Lösung für “procedure entry point”-artige DLL-Fehler.
Zwei Plausibilitätsprüfungen, die ich vor jedem großen Modell durchführe:
nvidia-smiwird in einem Terminal ausgeführt und zeigt den Treiber sauber.python -c "import torch: print(torch.version, torch.cuda.is_available())"gibt True für CUDA in der Umgebung zurück, die ComfyUI verwenden wird.
Nichts davon garantiert einen reibungslosen Ablauf, aber es grenzt die Fehlermöglichkeiten ein.
ComfyUI auf LTX-2-kompatible Version aktualisieren
Was ich tat:
- Aktualisiere ComfyUI zuerst. Falls du den Portable Build von GitHub verwendest, schnapp dir die neueste Version oder führe git pull aus und starte die Update-Skripte.
- Öffne ComfyUI Manager (falls du ihn verwendest) und aktualisiere die Kernabhängigkeiten. Ich ließ Manager das venv neu aufbauen, wenn es dazu aufforderte.
- Installiere das LTX‑2 Node-Paket aus seinem offiziellen Repo. Der Name variiert (ich habe “ComfyUI-LTXVideo”/“LTX‑Video”-artige Repos gesehen): Ich habe die verwendet, die von der offiziellen Seite des Modells verlinkt ist. Falls eine Repo-Beschreibung besagt, dass sie LTX‑Video v2/LTX‑2 unterstützt, das ist die, die du brauchst.
Warum das in der Praxis wichtig ist:
- LTX‑2 beruht auf PyTorch 2.3+-Funktionen und CUDA 12.x Builds. Das Mischen von altem torch (cu118) mit neuen Nodes ist eine schnelle Methode, um kryptische Import-Fehler zu bekommen.
- Manche Packs stellen FP8/BF16-Umschalter unterschiedlich dar. Das Abgleichen des Node-Pakets und der ComfyUI-Version vermeidet nicht übereinstimmende Eingaben und Sackgassen-Graphs.
Ich widersetzte mich der Neuinstallation anfangs, es wirkte unnötig. Dann verglich ich: Der neue Build startete beim ersten Versuch; die ältere Version fragte immer nach fehlenden Ops. Ich vermisste das Ratespiel nicht.
Modell-Datei-Platzierung (Schritt für Schritt)
Hier verschwende ich normalerweise Zeit. Unterschiedliche Nodes erwarten unterschiedliche Ordner. Hier ist, was bei mir mit dem LTX‑2 Node-Paket, das ich installiert habe, funktionierte, und das allgemeine Muster gilt auch, falls deine Ordnernamen unterschiedlich sind.
-
Finde die erwarteten Pfade des Nodes.
In ComfyUI öffnest du den LTX-Loader-Node und fährst mit der Maus über eine Dateieingabe. Die meisten Packs zeigen den relativen Pfad, den sie scannen (z.B.models/ltx,models/checkpoints, oder einen benutzerdefinierten Unterordner wiemodels/ltx_video).
Falls du dir unsicher bist, schau in die Repo-README. Sie listen normalerweise das genaue Verzeichnis auf. -
Lade die LTX‑2-Gewichte von der offiziellen Quelle herunter (oft Hugging Face, verlinkt von der Modell-Seite).
Du bekommst normalerweise eine Haupt-.safetensorsoder.pth-Datei plus Configs. Manche Repos teilen Text-Encoder/VAEs separat auf; andere bündeln sie. -
Platziere die Dateien genau dort, wo der Node schaut.
Für mein Paket:ComfyUI/models/ltx_video/hielt die primäre Modelldatei. Falls dein Paketmodels/checkpointssagt, verwende das stattdessen. Der Name sollte nach einem Neustart oder Rescan in der Node-Dropdown-Liste erscheinen. -
Optional: Text-Encoder / VAE.
Falls der Node separate Eingaben für Encoder oder eine VAE zeigt, folge seiner Anleitung. Viele LTX‑2 Nodes verstecken das und bündeln Komponenten intern. Falls es sichtbar ist, platziere CLIP/Tokenizer-Dateien inmodels/clipodermodels/text_encoderswie in der README instruiert. -
Starte ComfyUI neu.
Ich weiß, es ist offensichtlich. Aber Hot-Reloading scannt diese Ordner nicht immer erneut, und ich habe zu viele Male auf eine leere Dropdown-Liste gestarrt, als mir lieb ist.
Kleine Anmerkung: Falls Windows die heruntergeladenen Dateien als blockiert kennzeichnet (Rechtsklick > Eigenschaften > Entsperren), entferne das. Ich habe erlebt, dass Python sich weigert, “von Internet heruntergeladene” Dateien in strengeren Setups anzufassen.
Häufige Windows-Fehler (DLL / Berechtigungen)
“DLL load failed while importing …” oder fehlende nvrtc64_X.dll
- Ursache: PyTorch Build stimmte nicht mit der CUDA Runtime überein, die der Node-Pack erwartet, oder die Umgebung vermischte cu118 und cu12x.
- Lösung: Installiere/bestätige PyTorch 2.3+ mit cu121/cu122 innerhalb der ComfyUI-Umgebung erneut. Falls du Portable laufen lässt, lass Manager das handhaben. Das Aktualisieren der NVIDIA-Treiber half einmal.
 “Access is denied” beim Schreiben von Frames/Video
“Access is denied” beim Schreiben von Frames/Video - Ursache: Ich zeigte den SaveVideo-Node auf einen synchronisierten Ordner mit aggressiven Berechtigungen (OneDrive).
- Lösung: Schreibe zuerst in einen lokalen, nicht synchronisierten Pfad (z.B.
ComfyUI/output/ltx_test). Verschiebe die Datei später.
Lange Pfadprobleme beim Entpacken
- Ursache: Windows-Pfadlängenbeschränkungen plus tiefe ComfyUI-Unterordner.
- Lösung: Aktiviere lange Pfade unter Windows (Lokale Gruppenrichtlinie oder Registry) oder entpacke näher an
C:\.
Antivirus scannt Temp-Frames während des Renderings
- Symptom: ComfyUI-Hängung oder Stottern während der Codierung.
- Lösung: Füge eine Ausnahme für den ComfyUI-Ordner oder nur den Output-Temp-Pfad hinzu.
“Could not find model” obwohl korrekter Ordner
- Lösung: Starte ComfyUI neu. Falls es immer noch nicht angezeigt wird, überprüfe den genauen erwarteten Ordner des Nodes. Manche LTX‑2 Nodes schauen in einen benutzerdefinierten Verzeichnisnamen. Stimme ihn genau ab.
Ich bin auch auf die Klassiker “funktioniert einmal, schlägt beim nächsten Lauf fehl” gestoßen. Für mich kam das darauf an, dass ein Browser-Tab die partielles MP4 in der Vorschau zu betrachten versuchte, während der Encode-Node immer noch schrieb. Ich wechselte dazu, pro Durchlauf in einen neuen Dateinamen zu schreiben. Die Instabilität verschwand.
Erster Inference-Test Workflow
Ich hielt den ersten Graph klein. Nichts Cleveres, nur genug, um die Pipeline zu bestätigen.
Was ich baute:
- Ein Prompt-Node mit einem Satz (10–20 Tokens). Halte es einfach.
- LTX‑2 Loader-Node, der auf das heruntergeladene Modell zeigt.
- Ein LTX‑2 Sampler/Scheduler-Node (wie auch immer dein Paket es nennt) mit niedrigen Steps.
- Ein Video Decode/Assemble-Pfad, der Frames in einen SaveVideo-Node schreibt (MP4, H.264 ist in Ordnung für einen Smoke-Test).
Parameter, die mich nicht bekämpften:
- Auflösung: 512×288 oder 640×360
- Frames: 8–16 Frames (0,5–1 Sekunde)
- Steps: 6–12
- Guidance/CFG: Mittelgrund (5–7)
- Seed: feste Zahl (macht Troubleshooting weniger laut)
- Genauigkeit: FP16 (Standard) sofern dein Node BF16 auf Ada nicht vorschlägt: Beide funktionieren bei mir, FP16 verwendete weniger VRAM
Worauf ich beim ersten Lauf achte:
- VRAM-Spitzen in
nvidia-smi. Falls du sofort bei 99% VRAM gepinnt bist, senke die Auflösung oder Frames. - Zeit bis zum ersten Frame. Mein erster sauberer Lauf war ~25–40 Sekunden für 16 Frames bei 512×288 auf einer 4070, steps=8. Alles deutlich länger deutete normalerweise auf CPU-Codierung oder einen I/O-Engpass hin.
Falls dein Render fertiggestellt wird, aber das Video leer oder beschädigt ist, versuche:
- Schreibe zuerst PNG-Frames, dann lass einen separaten Node oder ein externes Tool das Video zusammensetzen.
- Wechsle zu einem anderen Encoder (H.264 vs H.265) oder CRF-Wert.
Der nützliche Teil war nicht die Geschwindigkeit, es war, einen kohärenten Clip zu sehen. Das ist der Moment, in dem ich mich entspanne. Dann skaliere ich vorsichtig auf.
Performance-Tuning (Batch / Genauigkeit)
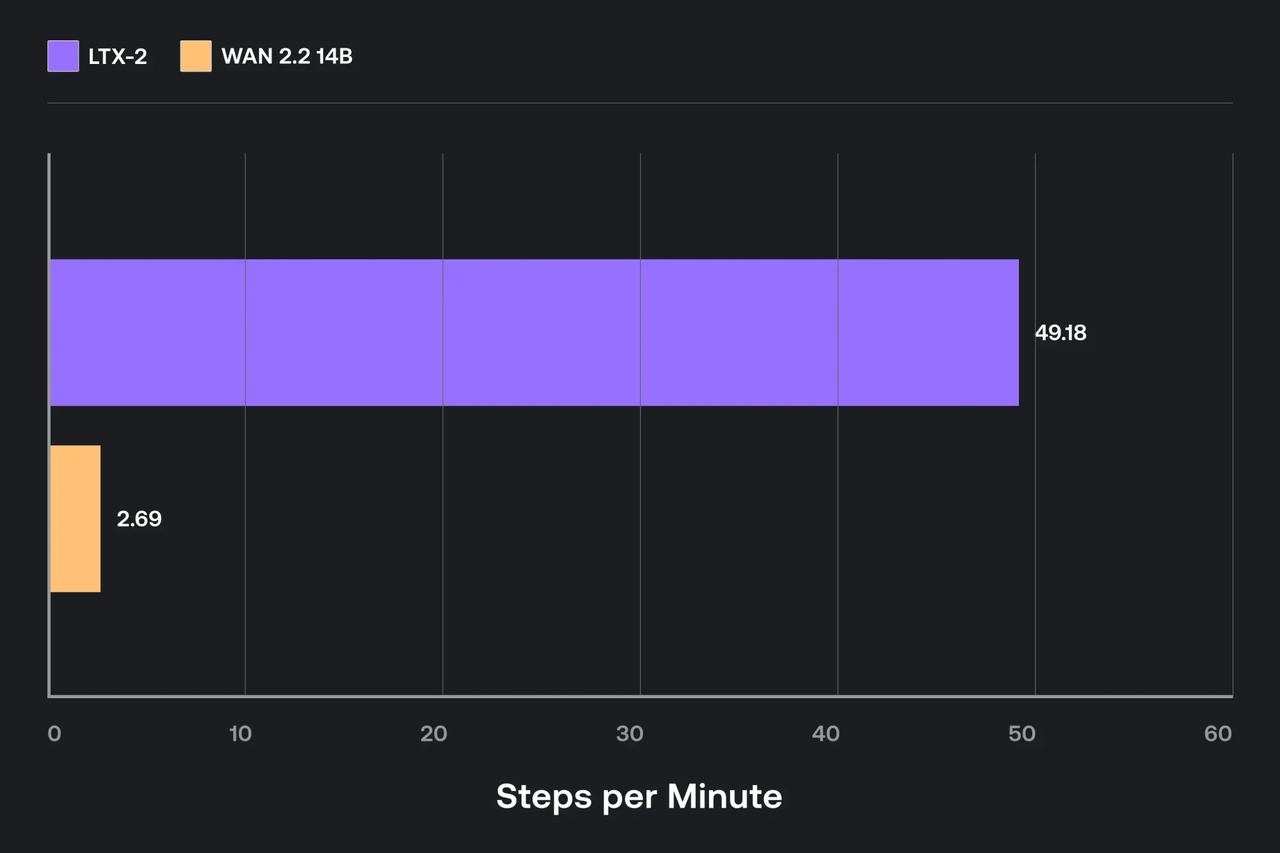 Ich jagte keine Benchmark-Herrlichkeit hinterher. Ich wollte einfach Einstellungen, die mich davon abhielten, den Speicher zu beaufsichtigen.
Ich jagte keine Benchmark-Herrlichkeit hinterher. Ich wollte einfach Einstellungen, die mich davon abhielten, den Speicher zu beaufsichtigen.
Was den Unterschied machte:
- Frames vor Breite. Es war einfacher auf VRAM, 12–16 Frames zu halten und die Breite auf 640 zu erhöhen, als auf 24+ Frames zu springen. Längere Clips steigen schnell im Speicher.
- Genauigkeit: FP16 funktionierte am besten auf meiner 4070. BF16 funktionierte auch, aber verwendete etwas mehr Speicher. Ich gewann keine sichtbare Qualität von BF16 bei diesen Größen.
- Attention Backend: Falls dein Paket einen Umschalter für
scaled_dot_product_attention(PyTorch native) vs xFormers zeigt, versuche zuerst native auf neuem PyTorch. Es war stabiler für mich unter Windows. - Batch-Größe: Halte sie auf 1 für Video. Mini-Batches bestraften hauptsächlich VRAM, ohne die Wall-Clock-Zeit auf meinem Setup zu sparen.
- Torch Compile: Wert zu testen, aber ich sah nur kleine Gewinne für längere Läufe. Für kurze 8–16 Frame-Tests könnte die Compile-Zeit die Einsparungen aufzehren.
- Gemischte I/O: Das Schreiben auf eine schnelle lokale SSD war wichtiger als ich erwartet hatte. Langsame Netzwerk-Ordner ließen die Encode-Phase wie ein Modell-Problem aussehen, wenn es nicht so war.
Eine einfache Leiter, die nicht VRAM für mich zerbombte:
- 512×288, 12 Frames, steps=8
- 640×360, 16 Frames, steps=10
- 768×432, 16–24 Frames, steps=12–14
Falls du keinen Speicher mehr hast:
- Senke Frames um 4, bevor du die Breite senkst.
- Senke Steps zuerst, wenn du nur einen Draft brauchst.
- Schließe andere GPU-Apps (Video-Player, Browser mit Hardware-Beschleunigung). Mühsam, aber es funktioniert.
Ich versuchte auch einen winzigen Tile/Patch-Modus, den manche Packs anbieten. Es half bei höheren Breiten, aber manchmal führte es zu Nähten. Gut für Experimente: nicht meine Standardeinstellung.
WaveSpeed-Pfad (keine lokale CUDA nötig)
 Ich testete einen Durchlauf über einen gehosteten Pfad, um das GPU-Shuffle zu vermeiden. Die Idee: Lass ComfyUI mit einem Remote Worker sprechen, der LTX‑2 ausführt, sodass dein lokaler Windows-Computer nur die Graph-UI handhabt.
Ich testete einen Durchlauf über einen gehosteten Pfad, um das GPU-Shuffle zu vermeiden. Die Idee: Lass ComfyUI mit einem Remote Worker sprechen, der LTX‑2 ausführt, sodass dein lokaler Windows-Computer nur die Graph-UI handhabt.
Wie das in der Praxis aussah:
- Installiere einen Connector/Extension in ComfyUI (der, den ich verwendete, nannte sich “WaveSpeed” in der Manager-Liste). Nach der Installation erschien eine neue Reihe von Nodes für Remote-Ausführung.
- Authentifiziere dich oder zeige auf einen Worker-Endpoint. Der meine verwendete einen Dashboard-Schlüssel. Das Setup dauerte ein paar Minuten.
- Wechsle den lokalen LTX‑2 Loader/Sampler zu den WaveSpeed-Äquivalenten. Gleiche Prompts, gleiche Graph-Form, nur unterschiedliche Nodes.
Überspringe den Setup-Kopfschmerz: Teste LTX‑2 sofort auf WaveSpeed — keine lokale GPU, keine Treiber-Jonglage, einfach deinen Prompt eingeben und anfangen zu rendern.
Falls du neugierig bist, schau dir die offiziellen Docs des Connectors für die aktuellen Setup-Schritte an. Ich würde meinen ganzen Workflow nicht um dies herum neu aufbauen, aber als kein-CUDA-Pfad war es erfrischend langweilig, auf gute Weise.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung
