DeepSeek V4 API Python: Minimale Code-Beispiele mit Streaming

Now I’ll create the German translation. Since the article in the prompt is different from what’s in the file (it’s about using the API with Python, not getting the API key), I’ll translate the article text provided in the user’s message.
Hallo Leute! Ich bin Dora hier. Es fing mit einer kleinen Frustration an: Ich kopierte mir ständig den gleichen Chat-Completion-Boilerplate zwischen Projekten, wechselte Base-URLs und Modellnamen wie Etiketten auf Gläsern aus. Keine schwere Arbeit, nur die Art, die deinen Tag mit Reibung füllt. DeepSeek war mir häufig genug begegnet, um neugierig zu werden, also reservierte ich mir ein paar Morgen Ende Januar 2026, um ihre “V4”-API in meinen Python-Stack zu integrieren und zu schauen, wie sie sich in der echten Nutzung anfühlte.
Ich jagte nicht hinter Benchmarks. Ich wollte wissen: Bleibt der Client mir aus dem Weg, kann ich zuverlässig streamen, und schlagen Fehler auf eine Weise fehl, die leicht zu verstehen ist? Hier ist, was ich versucht habe, womit ich stecken blieb, und was einfach funktioniert hat. Lass uns gehen!
Umgebungssetup
Abhängigkeiten
Ich hielt das Setup auf macOS mit Python 3.11 einfach. Du kannst das mit der Standardbibliothek machen, aber drei kleine Pakete machten das Leben leichter:
- requests (unkompliziertes HTTP: ausreichend für die meisten Fälle)
- httpx (async und Timeouts, die sich gut verhalten)
- python-dotenv (damit ich Keys nicht überall herumkopiere)
 Wenn du mit Server-Sent Events streamen möchtest, kannst du requests verwenden und Zeilen selbst analysieren (das habe ich gemacht), oder ein Hilfsmittel wie sseclient-py mitbringen. Ich blieb bei requests, weniger bewegliche Teile.
Wenn du mit Server-Sent Events streamen möchtest, kannst du requests verwenden und Zeilen selbst analysieren (das habe ich gemacht), oder ein Hilfsmittel wie sseclient-py mitbringen. Ich blieb bei requests, weniger bewegliche Teile.
Installation
pip install requests httpx python-dotenvIch erstellte auch eine minimale virtuelle Umgebung pro Projekt. Es ist langweilige Beratung, aber sie spart dir vor Abhängigkeits-Drift, wenn du das in drei Monaten wieder besuchst.
API-Schlüssel-Konfiguration
Ich speicherte den Schlüssel in einer Umgebungsvariable. Nichts Besonderes:
# .env
DEEPSEEK_API_KEY=your_key_hereDann in Python:
from dotenv import load_dotenv
import os
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not API_KEY:
raise RuntimeError("Missing DEEPSEEK_API_KEY")Zwei kleine Anmerkungen aus dem Setup:
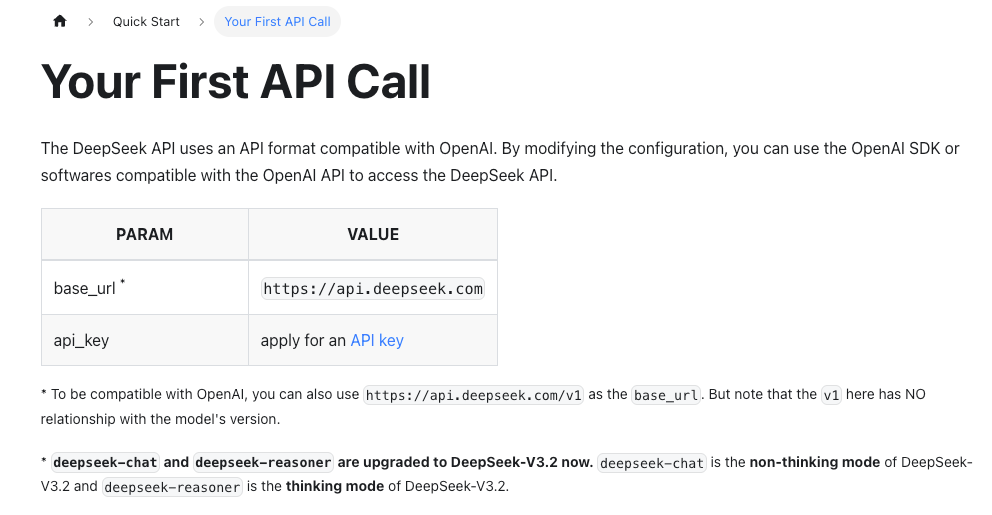
- Die Base-URL und Modellnamen ändern sich häufiger, als man denkt. Ich überprüfte die offizielle DeepSeek API-Dokumentation vor jedem Durchgang, um Pfade und verfügbare Modelle zu bestätigen.
- Ich behielt Timeouts explizit. Es ist eine Gewohnheit, die sich bezahlt macht, wenn du Ratenbegrenzungen oder Netzwerk-Rauschen triffst.
Grundlegende Chat-Anfrage
Das mentale Modell ist vertraut, wenn du Chat-Completions anderswo verwendet hast. DeepSeek bietet einen Chat-Endpunkt mit messages=[{"role": "...", "content": "..."}]. Das ist hilfreich, weil ich meine Prompts nicht neu rahmen musste.
Hier ist die minimale Anfrage, die ich mit requests verwendete. Modellnamen variieren je nach Konto und Region. Während meiner Tests sah ich Verweise wie deepseek-chat und deepseek-reasoner. Wenn deine Docs einen “V4”-Modellstring erwähnen, nutze diesen. Andernfalls wähle das nächstgelegene General-Purpose-Chat-Modell aus deiner Konsole.
import os
import requests
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat", # überprüfe Docs/Konsole für das genaue Modell
"messages": [
{"role": "system", "content": "Du bist ein prägnanter Assistent."},
{"role": "user", "content": "Gib mir zwei Aufzählungspunkte zum Wert klarer Commit-Nachrichten."}
],
"temperature": 0.3,
"max_tokens": 200
}
resp = requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
timeout=30
)
resp.raise_for_status()
data = resp.json()
content = data["choices"][0]["message"]["content"]
print(content)Feldnotizen
- Der erste Durchgang war ereignislos (eine Erleichterung). Die Struktur entsprach meinen Erwartungen, was die Migration einer kleinen Prompt-Bibliothek schnell machte.
- Ich hielt die Temperatur niedrig für wiederholbare Antworten. Das klingt offensichtlich, aber ich vergesse es trotzdem, wenn ich Fehler behebe.
- Wenn du deterministische Durchläufe brauchst, pin auch top_p und seed, falls die API das unterstützt. Wenn die Docs stumm sind, nehme ich an, nicht-deterministisch.
Wenn du Provider vergleichst, ist der Vorteil hier geringer Reibungswiderstand. Der Nachteil ist, dass sich Unterschiede an den Rändern verstecken: Fehler-Payloads, Token-Abrechnung und Streaming-Form. Diese Ränder sind dort, wo deine Integration sich entweder robust oder nervig anfühlt.
Code-Generierungs-Beispiel
Ich bitte Modelle nicht, vollständige Module zu schreiben. Es wird ein Aufräumjob. Aber für kleine Helfer wie “parse dieses Zeitstempelformat” oder “entwerfe die SQL mit Platzhaltern,” ist es praktisch.
Ich verwendete einen engen Prompt, einen klaren Vertrag und kleine Output-Limits. Das hielt das Modell davon ab, abzuschweifen und machte Diffs leicht überprüfbar.
import requests, os
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
messages = [
{"role": "system", "content": (
"Du generierst kleine, sichere Python-Helfer. "
"Gib nur Code in einem Block zurück."
)},
{"role": "user", "content": (
"Schreibe eine Python-Funktion `parse_yyyymmdd`, die eine Zeichenkette wie '2026-01-31' "
"nimmt und ein datetime.date zurückgibt. Wenn ungültig, gib None zurück. Keine externen Abhängigkeiten."
)}
]
resp = requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={
"model": "deepseek-chat", # oder dein V4-fähiges Modell
"messages": messages,
"temperature": 0,
"max_tokens": 250
},
timeout=30
)
resp.raise_for_status()
code = resp.json()["choices"][0]["message"]["content"]
print(code)Was in der Praxis half
- Ich sage ihm immer, nur Code zurückzugeben. Wenn ich das überspringe, bekomme ich Wrap-up-Sätze, die ich nicht brauche.
- Temperatur 0 reduziert fummelige Bearbeitungen.
- Ich lese die Logik trotzdem durch. In meinem Durchgang behandelte es ValueError, aber ich fügte trotzdem eine zusätzliche Prüfung auf Leerzeichen hinzu. Zwei zusätzliche Minuten jetzt sparen Stunden Überraschungen später.
Das sparte Zeit beim ersten Versuch nicht. Nach drei oder vier kleinen Helfern bemerkte ich, dass es mentale Anstrengung reduzierte: weniger Tab-Wechsel, weniger “Was ist nochmal der genaue strptime-Code?”-Momente. Das reicht mir.
Streamen von Antworten
Ich mag Streaming für jeden Prompt, der wachsen könnte. Es lässt mich früh aussteigen, wenn die Antwort abdriftet, und macht lange Antworten weniger belastend anfühlen.
DeepSeeks Streaming verwendete das übliche Muster in meinen Tests: setz stream=true und lese Datenzeilen bis [DONE]. Ich brauchte keinen speziellen Client, requests mit iter_lines war ausreichend.
import os, json, requests
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "Sei prägnant."},
{"role": "user", "content": "Fasse zusammen: Streaming hält die UI responsiv und lässt mich früh stoppen."}
],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line:
continue
if line.startswith("data: "):
chunk = line[len("data: "):]
if chunk == "[DONE]":
break
try:
obj = json.loads(chunk)
delta = obj["choices"][0]["delta"].get("content", "")
if delta:
print(delta, end="", flush=True)
except json.JSONDecodeError:
# Ich halte ein kleines Log, wenn das passiert: normalerweise Netzwerk-Ausreißer
pass
print()Zwei kleine Verhaltensweisen, die ich mochte:
- Frühe Tokens kamen schnell an (eine oder zwei Sekunden bei einer sauberen Verbindung). Nicht wissenschaftlich, nur genug um sich knackig zu anfühlen, wenn ich es in ein CLI-Tool verdrahtete.
- Der
[DONE]-Marker erschien zuverlässig. Es klingt trivial, bis es das nicht tut. Fehlende Terminatoren hängen UIs auf.
Wenn du in eine Web-App streamen musst, würde ich eine dünne Server-Schicht dazwischen legen um Events zu normalisieren. Es ist ein zusätzlicher Schritt, aber es hält dein Frontend einfach.
Server-Sent Events
Unter der Haube liest du praktisch Server-Sent Events. Wenn du ein Hilfsmittel bevorzugst, funktioniert sseclient-py, aber dein eigenes Schreiben hier ist in Ordnung, solange du dich gegen unvollständige Zeilen und Timeouts schützt. Die Docs-Seite zum Streaming in der DeepSeek API-Dokumentation reichte aus, um das ohne Überraschungen zum Laufen zu bringen.
Fehlerbehandlung
 Die meisten meiner Fehler waren vorhersehbar: fehlender Schlüssel, schlechter Modellname oder Timeouts, wenn ich mein Netzwerk drosselte um Travel-Wi-Fi zu simulieren.
Die meisten meiner Fehler waren vorhersehbar: fehlender Schlüssel, schlechter Modellname oder Timeouts, wenn ich mein Netzwerk drosselte um Travel-Wi-Fi zu simulieren.
Ein kleines Muster, das ich wiederverwendbar mache:
import httpx, time, os
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
RETRIABLE = {408, 409, 425, 429, 500, 502, 503, 504}
async def chat_once(client, messages):
resp = await client.post(
BASE_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json={
"model": "deepseek-chat",
"messages": messages,
"temperature": 0.2,
"max_tokens": 300,
},
timeout=30,
)
if resp.status_code == 401:
raise RuntimeError("Unauthorized. Überprüfe DEEPSEEK_API_KEY und Kontozugriff.")
if resp.status_code == 404:
raise RuntimeError("Endpunkt oder Modell nicht gefunden. Bestätige Modellnamen in Konsole/Docs.")
if resp.status_code in RETRIABLE:
raise RuntimeError(f"Wiederholbarer Status: {resp.status_code}")
resp.raise_for_status()
return resp.json()
async def chat_with_retries(messages, attempts=4):
backoff = 0.5
async with httpx.AsyncClient() as client:
for i in range(attempts):
try:
return await chat_once(client, messages)
except RuntimeError as e:
msg = str(e)
if "Retryable status" in msg and i < attempts - 1:
time.sleep(backoff)
backoff *= 2
continue
raiseEin paar praktische Anmerkungen:
- Ratenbegrenzungen: Ich sah 429, wenn ich parallele Tests abschoss. Exponentieller Backoff half, aber ich fügte auch kleine Jitter hinzu (zufällig 50–150ms) um Thundering-Herds zu vermeiden.
- Timeout-Hygiene: Ich setze kürzere Connect/Read-Timeouts für schnelle Checks (5–10s) und längere für große Prompts. Timeouts sollten nicht alle standardmäßig 30s sein: es versteckt Probleme.
- Fehler-Payloads: Wenn Dinge fehlschlugen, enthielt der JSON-Body eine Nachricht, die ich protokollieren konnte. Ich wickle sie immer noch in meine eigenen Exceptions, um zu kontrollieren, was die UI erreicht.
Wenn dein Codebase bereits das OpenAI-Stil-Schema spricht, ist das handhabbar: gleiche Nachrichtenform, leicht unterschiedliche Ränder. Das Wichtigste ist, bei Modellnamen streng zu sein und den vollständigen Response-Body beim Fehler zu protokollieren, damit du nicht rätst.
Dokumentations-weise lehnte ich mich auf die offizielle DeepSeek API-Dokumentation an für Parameternamen und Streaming-Form. Wann immer ein Provider vertraute Endpunkte nutzt, ist es verlockend, Parität anzunehmen. Ich habe gelernt, zuerst die Docs zu überprüfen und weniger zwischen Clients zu kopieren als ich denke, dass ich kann.
Wem könnte das gefallen

- Wenn du einen existierenden Python-Wrapper für Chat-Completions hast, ist der Migrationspfad sanft.
- Wenn dir Streaming und einfache Retries wichtig sind, verhält es sich vorhersehbar.
- Wenn du sehr spezifische Tools brauchst (Function-Calling-Schemas, Reasoning-Tokens oder Batch-Jobs), wirst du die Docs genau lesen und mit einer engen Aufgabe prototypisieren wollen, bevor du dich festlegst.
Ich habe nicht versucht, lange Multi-Step-Agenten hier zu orchestrieren. Ich konzentrierte mich auf kleine, tägliche Prompts, die Art, die Reibung abbaut. Das ist dort, wo die DeepSeek V4 API mit Python sich stabil genug anfühlte zum Weitermachen.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
