DeepSeek V4 1M Token Context: So prompten Sie ganze Codebases

Hey meine Freunde. Ich bin Dora. Das erste Mal, als ich ein ganzes Projekt in DeepSeeks V4 mit seinem 1-Million-Token-Fenster warf, fühlte ich mich nicht mächtig. Ich war vorsichtig. Eine Million Token klingt wie endlos Kaffee, aber wer jemals versucht hat, stundenlang auf Koffein nachzudenken, weiß, dass die Grenzen verschwimmen. Ich wollte sehen, ob diese neue Kontextgröße meine Arbeitsweise tatsächlich ändern würde, oder nur dazu verleitet, mehr zu kopieren und einzufügen.
Ich verbrachte einige Tage (27.–30. Januar 2026) damit, DeepSeek V4 mit 1 Million Token für drei Aufgaben zu nutzen, denen ich oft begegne:
- einen mittelgroßen Monorepo lesen, ohne ihn lokal einzurichten,
- einen Bug über Services hinweg verfolgen, die zu viel miteinander reden,
- und Umgestaltungsvorschläge anfordern, die die Tests nicht kaputt machen.
Was ich gelernt habe: Man kann viel unterbringen, aber das Modell braucht trotzdem deine Hilfe, um die richtige Richtung zu finden. Die Gewinne kamen nicht davon, mehr Dateien einzufügen: Sie kamen davon, wie ich den Prompt strukturierte und wie ich das Modell durch ihn führte.
Was 1 Million Token wirklich bedeutet
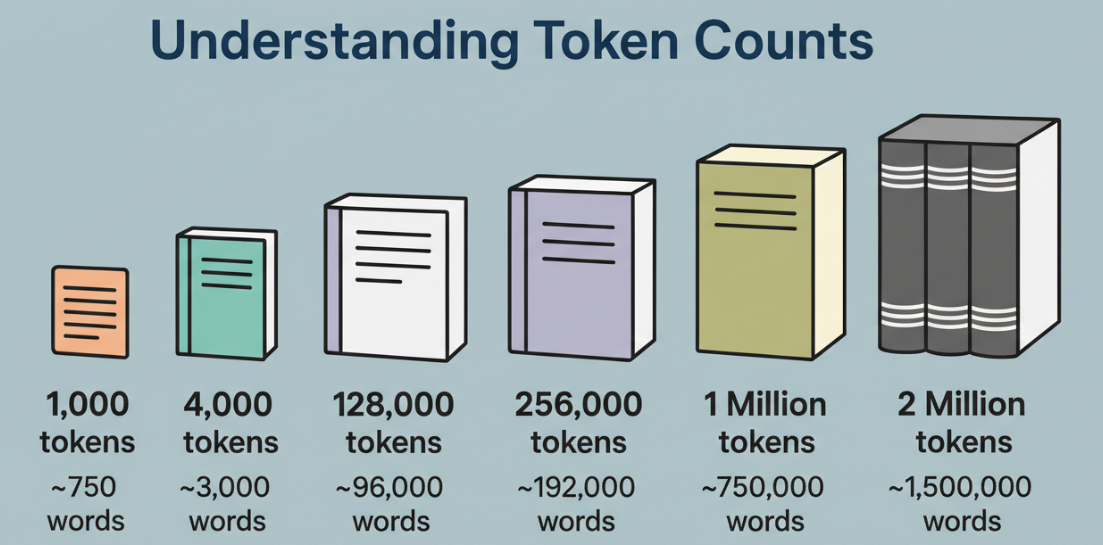 Mir ist die Zahl selbst egal. Mir ist wichtig, was sie mit klarem Kopf enthält.
Mir ist die Zahl selbst egal. Mir ist wichtig, was sie mit klarem Kopf enthält.
Ein Token ist kein Wort. Es ist ein Stück, manchmal ein ganzes Wort, manchmal Teil eines, manchmal Satzzeichen. Bei englischem Text behandle ich normalerweise 1 Token als etwa 0,75 Wörter für grobe Planung. Bei Code kommen Token schnell: Klammern, Punkte, Methodennamen, alles in Scheiben geschnitten. Eine Million Token ist viel Territorium, aber es ist nicht unendliche Aufmerksamkeit.
Was sich für mich diese Woche geändert hat: Ich hörte auf, so aggressiv zu kürzen. Mit 128K-Kontexten würde ich aggressiv zusammenfassen und nur den kritischen Pfad behalten. Mit 1M konnte ich den kritischen Pfad plus die „kalten” Dateien behalten, die mich später überraschen (Config, Migrationen, Build-Skripte, Workflow-Glue). Allerdings, wenn ich alles auf einmal eingegeben hätte, wären die Antworten vage geworden. Wenn ich das Modell in Etappen mit klaren Anhaltspunkten fütterte, fühlten sich die Outputs fundiert an.
Äquivalent zu Codezeilen
Ungefähre Mathematik, die ich während der Arbeit verwendete:
- Viele Repos mischen Code und Dokumentation. In Code-intensiven Ordnern sah ich ~2–3 Token pro Zeichen in dichten Sprachen, aber ein praktischer Trick: denke ~4 Token pro Zeile für einfache Zeilen, ~8–12 für echte Zeilen mit Einrückung, Namen und Kommentaren.
- In diesem Tempo fasst 1 Million Token etwa 80.000–150.000 Codezeilen, je nach Stil und Sprache. Ein TypeScript-Service mit Kommentaren und Lint-freundlicher Benennung sitzt auf der höheren Seite. Minifizierte Bundles lassen die Anzahl explodieren und sind nicht wert, einzufügen.
In der Praxis war mein „sicherer Umfang” ~60.000 Zeilen aussagekräftiger Quellcode + gezielte Docs und Tests. Ich könnte höher gehen, aber die Latenz stieg und die Antworten wurden weicher. Dein Kilometerstand wird mit Tokenizer-Regeln und Sprachenmischung variieren.
vs. aktuelle Modelle (128K)
Von 128K auf 1M zu wechseln fühlt sich weniger wie ein größerer Rucksack und mehr wie das Mitbringen eines Rollkoffers an. Du kannst mehr tragen, aber du wirst nicht sprinten.
Was mir auffiel:
- Latenz: Prompts mit vollem Kontext dauerten merklich länger. Wenn ich die Session chunkte (Etappe für Etappe), fühlte sich die Latenz handhabbar an.
- Erinnerung: Mit 128K vergaß das Modell oft frühere Dateien, es sei denn, ich wiederholte den kritischen Teil. Mit 1M vergaß es nicht, aber es verallgemeinerte manchmal statt spezifisch zu zitieren. Ich hatte bessere Erfolge, wenn ich es bat, Dateipfade und Zeilenbereiche wo möglich anzugeben.
- Präzision: Je größer der Kontext, desto mehr brauchst du Indexierungsverhalten in deinem Prompt. Sonst bekommst du kompetente Zusammenfassungen, die die unordentlichen Grenzfälle ausweichen, um die es dir eigentlich geht.
Wenn du hoffst, dass 1 Million Token „kein Prompt Engineering mehr” bedeutet, würde ich nicht darauf zählen. Es verschiebt die Art von Steuerung, die du machst.
Prompt-Struktur für große Codebases
 Ich hörte auf, den Prompt als Nachricht zu sehen und begann, ihn wie einen Leseplan zu behandeln. Das Modell kann jetzt viel lesen, profitiert aber immer noch von einem Inhaltsverzeichnis und einem Pfad.
Ich hörte auf, den Prompt als Nachricht zu sehen und begann, ihn wie einen Leseplan zu behandeln. Das Modell kann jetzt viel lesen, profitiert aber immer noch von einem Inhaltsverzeichnis und einem Pfad.
Was für mich am besten funktionierte, sah so aus: kurze System-Rahmung, prägnanter Projektindex, eine erklärte Explorationssreihenfolge, dann eine spezifische Aufgabe. Und dann führte ich das Gespräch in Runden fort, nicht in einem Mega-Prompt.
Datei-Reihenfolge
Ich bekam zuverlässigere Antworten, wenn ich dem Modell sagte, was es zuerst, zweiter, dritter Stelle öffnen sollte. Eine einzelne Liste oben half ihm, einen mentalen Stack aufzubauen:
- Beginne mit den Entry Points (CLI, HTTP Handler, Jobs). Es verankert den Fluss.
- Dann die Kompositionsebene (DI-Container, main.ts, app.py) wo Abhängigkeiten verdrahtet werden.
- Nächstes, die Kerndomänenmodule und ihre Schnittstellen.
- Erst dann: Helfer, Utils und querschnittliche Teile (Logging, Telemetrie, Config).
- Tests zuletzt, es sei denn, ich debugge einen spezifischen Fehler, dann beginne ich mit der fehlgeschlagenen Spec, um Erwartungen zu setzen.
Ich included auch „nicht lesen”-Notizen für Ordner, die wichtig aussehen, aber nicht sind: generierter Code, kompilierte Assets, Snapshots. Das sparte Token und behielt die Aufmerksamkeit des Modells auf lebendem Code.
Ein kleiner Trick: Ich bat das Modell, eine rollende Liste von „aktiven Dateien” (Pfade und kurze Zusammenfassungen) zu pflegen und sie zu aktualisieren, während wir uns bewegten. Wenn es abwich, könnte ich auf diese Liste zeigen und sagen: „Bleibe jetzt in diesem Satz.” Das hielt die Antworten konkret.
Abhängigkeitszuordnung
Einer der nützlichsten Durchläufe war, früh eine Abhängigkeitszuordnung zu fordern, nicht als Diagramm sondern als einfache Tabelle von Kanten: Modul A importiert B, B nutzt C, C trifft Umgebungsvariablen, und so weiter. Ich hielt es textuell und knapp.
Was das in der Praxis tat:
- Es offenbarte verirrte Abhängigkeiten (die Art, die Bedenken über Ordner hinweg bluten).
- Es gab mir eine Shortlist von „Druckpunkten” zum Überprüfen vor jeglicher Umgestaltung.
- Es half dem Modell, die richtige Stelle zu referenzieren, wenn ich um Änderungen bat.
Ich ließ das Modell auch Annahmen aussprechen, was es aus Naming, Kommentaren oder Tests schloss. Wenn eine Annahme falsch war, korrigierte ich sie einmal, und die späteren Schritte blieben sauberer.
Eine Warnung: Eine vollständige Abhängigkeitszuordnung auf einem großen Repo auf einmal zu fordern führte zu Timeouts und vagen Graphen. Ich hatte bessere Ergebnisse, es nach Ebene zu scoped (z.B. nur Datenzugriff, nur HTTP Handler) und dann die Notizen selbst zu mergen. Es dauerte zehn Minuten länger, zahlte sich aber in Genauigkeit aus.
Chunking-Strategien bei Bedarf
 Auch mit einem 1-Million-Token-Fenster chunkte ich immer noch. Nicht weil es nicht passte, sondern weil mein Denken in Etappen besser war, und das Modell antwortete präziser, wenn ich sein Sichtfeld verengte.
Auch mit einem 1-Million-Token-Fenster chunkte ich immer noch. Nicht weil es nicht passte, sondern weil mein Denken in Etappen besser war, und das Modell antwortete präziser, wenn ich sein Sichtfeld verengte.
Ein paar Muster, die diese Woche standhielten:
- Etappiere die Anweisung: Ich startete mit einem kleinen Kontext, Projektindex, Aufgabe, bekannte Einschränkungen, dann bat ich um einen Lese- und Verifikationsplan. Erst danach fütterte ich den Code in der Reihenfolge, auf die wir uns einigten.
- Begrenze die aktive Menge: Für eine Umgestaltung behielt ich nur die 5–12 Dateien in Spiel und forderte Änderungen mit expliziten Pfaden. Wenn eine Bearbeitung ein gemeinsames Util berührte, addierte ich diese Datei in der nächsten Wendung. Das Modell blieb straffer.
- Zusammenfassung an Kanten: Bevor ich zu einem neuen Ordner wechselte, forderte ich eine kurze Zusammenfassung dessen, was wir lernten und alle Unsicherheiten. Diese Zusammenfassungen waren wie Brotkrumen über Wendungen hinweg, ohne jede Datei neu einzufügen.
- Nutze Abruf mit Absicht: Für Repos, die nicht bequem passten, nutzte ich Embeddings, um Dateien nach Anfrage zu rufen („Zahlungs-ID-Normalisierung”, „Wiederholung-Backoff”). Ich hielt die abgerufene Menge kleine pro Wendung, normalerweise unter 40K Token, damit Antworten nicht unscharf wurden.
- Verifiziere vorwärts, nicht rückwärts: Statt zu fragen, „Hast du alles verwendet, das ich eingefügt habe?” bat ich, „Zeige auf die spezifischen Funktionen und Zeilen, von denen dein Vorschlag abhängt.” Das erzwang konkrete Referenzen und machte Fehler offensichtlich.
Reibung, auf die ich traf:
- Latenz klettert, wenn du jede Wendung vollständige Kontextnachrichten sendest. Das Etappieren schnitt meine durchschnittliche Antwortzeit von 70–90s auf 20–40s für die gleichen Aufgaben.
- Kosten zählen. Große Prompts summieren sich. Ich sparte Token, indem ich Kommentare kürzelte, die das Offensichtliche wiederholten, kompilierte Artefakte entfernte und Vendor-Bundles übersprang.
- Positionseffekte sind real. Inhalte ganz am Anfang oder Ende eines gigantischen Prompts sind dazu geneigt, mehr „verfügbar” zu sein. Dem begegnete ich, indem ich die winzigen, kritischen Einschränkungen am Ende jeder Wendung wiederholte.
Wer profitiert vom 1-Million-Token-Fenster?

- Wenn du in Monorepos lebst, Audits bearbeitest oder querschnittliche Umgestaltungen machst, spart es dir weniger Setup-Schritte und weniger lokalen Indexierungs-Overhead. Es ist ein ruhigerer Ausgangspunkt.
- Wenn deine Arbeit meist fokussierte Bugfixes in kleinen Services sind, wird dir die zusätzliche Kapazität nicht viel helfen. Ein kleinerer Kontext plus eine enge Abruf-Pipeline werden sich schneller anfühlen.
Eine Anmerkung zum Vertrauen: Ich bat das Modell, exakte Code-Zeilen für riskante Änderungen zu zitieren (Migrationen, Auth). Wenn es zögerte oder umschrieb, behandelte ich das als Flagge, um den Umfang zu verengen oder die spezifische Datei erneut einzufügen. Diese kleine Gewohnheit verhinderte ein Paar von knappen Fehlschlägen.
Wenn du die formale Beschreibung von Modellgrenzen oder Tokenizer-Verhalten willst, überprüfe die Dokumentation des Anbieters. Wenn ich Spezifika brauchte, ging ich zurück zur offiziellen Modellkarte und Kontext-Fenster-Notizen. Es hielt mich ehrlich über das, worum ich das Modell bat.
Das ist keine Magie. Es ist einfach ein größerer Tisch. Nützlich, wenn du die Stühle arrangierst.
Ich denke immer noch über eine kleine Sache von Dienstag nach: Ich bat um eine Korrektur, und das Modell schlug vor, eine Funktion zu ändern, die auf den ersten Blick richtig aussah. Es war nicht. Der Bug lebte in einem Helper zwei Ebenen unten. Eine Million Token änderten das nicht. Meine Notizen taten es.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
