WaveSpeedAI X DataCrunch:B200 上的 FLUX 實時圖像推理

WaveSpeedAI X DataCrunch:B200 上的 FLUX 實時圖像推理
WaveSpeedAI 與歐洲 GPU 雲計算提供商 DataCrunch 攜手合作,在生成式圖像和視頻模型部署方面取得了突破。通過在 DataCrunch 最先進的 NVIDIA B200 GPU 上優化開源權重 FLUX-dev 模型,我們的合作實現了相比行業標準基準高達 6 倍更快 的圖像推理速度。
在本文中,我們提供了 FLUX-dev 模型和 B200 GPU 的技術概述,討論了使用標準推理堆棧擴展 FLUX-dev 的挑戰,並分享了基準測試結果,展示了 WaveSpeedAI 專有框架如何顯著改善延遲和成本效率。企業 ML 團隊將了解到 WaveSpeedAI + DataCrunch 解決方案如何轉化為更快的 API 響應和顯著降低的每張圖像成本,從而賦能實際應用中的 AI。(WaveSpeedAI 由 Zeyi Cheng 創立,他領導我們加速生成式 AI 推理的使命。)
本博客同時發佈在 DataCrunch 博客。
FLUX-Dev:SOTA 圖像生成模型
FLUX-dev 是一個最先進(SOTA)開源圖像生成模型,能夠執行文本轉圖像和圖像轉圖像生成。其功能包括出色的世界理解和提示詞遵循(得益於 T5 文本編碼器)、風格多樣性、複雜場景語義和構圖理解。模型輸出質量與流行的閉源模型如 Midjourney v6.0、DALL·E 3(HD)和 SD3-Ultra 相當或更優。FLUX-dev 迅速成為開源社區中最受歡迎的圖像生成模型,為質量、多功能性和提示詞對齐設定了新的基準。
FLUX-dev 使用流匹配,其模型架構基於多模態和並行擴散變換器塊的混合架構。該架構具有 12B 參數,約 33 GB fp16/bf16。因此,FLUX-dev 由於參數數量龐大和迭代擴散過程,計算需求很高。高效推理對於大規模推理場景至關重要,其中用戶體驗至關重要。
NVIDIA 的 Blackwell GPU 架構:B200
Blackwell 架構包含新功能,如第 5 代張量核心(fp8、fp4)、張量內存(TMEM)和 CTA 對(2 CTA)。
-
TMEM:張量內存是一個新的片上內存級別,增強了傳統的寄存器、共享內存(L1/SMEM)和全局內存層次結構。在 Hopper(例如 H100)中,片上數據通過寄存器(每個線程)和共享內存(每個線程塊或 CTA)管理,通過張量內存加速器(TMA)進行高速傳輸到共享內存。Blackwell 保留了這些,但添加了 TMEM 作為每個 SM 額外 256 KB 的 SRAM,專用於張量核心操作。TMEM 並不根本改變您編寫 CUDA 內核的方式(邏輯算法相同),但添加了新工具來** 優化數據流**(參見 ThunderKittens Now Optimized for NVIDIA Blackwell GPUs)。
-
2CTA(CTA 對)和集群合作:Blackwell 還引入了 CTA 對 作為一種方式來緊密耦合同一 SM 上的兩個 CTA。CTA 對本質上是一個大小為 2 的集群(兩個線程塊在一個 SM 上並發調度,具有特殊的同步能力)。雖然 Hopper 允許集群中最多 8 或 16 個 CTA 通過 DSM 共享數據,但 Blackwell 的 CTA 對使它們能夠在共同數據上集體使用張量核心。事實上,Blackwell PTX 模型允許兩個 CTA 執行訪問彼此 TMEM 的張量核心指令。
-
第 5 代張量核心(fp8、fp4):B200 中的張量核心明顯更大,** 比 H100 中的張量核心快約 2–2.5 倍**。高張量核心利用率對於實現主要的新一代硬件加速至關重要(參見對 Nvidia Hopper GPU 架構的基準測試和剖析)。
無稀疏性能數字
| 技術規格 | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| GPU 內存 | 80 GB HBM3 | 180GB HBM3E |
| GPU 內存帶寬 | 3.35 TB/s | 7.7TB/s |
| 每個 GPU 的 NVLink 帶寬 | 900GB/s | 1,800GB/s |
GEMM 和注意力的算子級微基準測試顯示以下結果:
- BF16 和 FP8 cuBLAS、CUTLASS GEMM 內核:比 H100 上的 cuBLAS GEMM ** 快達 2 倍**;
- 注意力:cuDNN 速度比 H100 上的 FA3 ** 快 2 倍**。
基準測試結果表明 B200 非常適合大規模 AI 工作負載,尤其是需要高內存吞吐量和密集計算的生成式模型。
標準推理堆棧的挑戰
在典型推理管道(例如 PyTorch + Hugging Face Diffusers)上運行 FLUX-dev,即使在 H100 等高端 GPU 上,也面臨多項挑戰:
- 單個圖像高延遲,由於 CPU-GPU 開銷和缺乏內核融合;
- GPU 利用率不理想 和張量核心閒置;
- 迭代擴散步驟期間的內存和帶寬瓶頸。
大規模和廉價推理服務的優化目標是更高的吞吐量和更低的延遲,從而降低圖像生成成本。
WaveSpeedAI 的專有推理框架
WaveSpeedAI 使用專有框架解決這些瓶頸,該框架專為生成式推理而構建。由創始人 Zeyi Cheng 開發,這個框架是我們內部高性能推理引擎,專門為 FLUX-dev 和 Wan 2.1 等最先進的擴散變換器模型優化。推理引擎的關鍵創新包括:
- 端到端 GPU 執行,消除 CPU 瓶頸;
- 自定義 CUDA 內核 和內核融合 以實現優化執行;
- 先進的量化和混合精度(BF16/FP8),使用 Blackwell 變換引擎同時維持最高精度;
- 優化的內存規劃和預分配;
- 延遲優先調度機制,優先考慮速度而非批處理深度。
我們的推理引擎遵循硬件-軟件共設計,充分利用 B200 的計算和內存容量。它代表了 AI 模型服務的重大飛躍,使我們能夠在生產規模上提供超低延遲和高效率的推理。 我們評估這些優化對輸出質量的影響,優先考慮無損與寬鬆優化。也就是說,我們不應用可能會顯著降低模型功能或完全破壞可見輸出質量的優化,例如文本呈現和場景語義。
基準測試:WaveSpeedAI 在 B200 上 vs. H100 基準
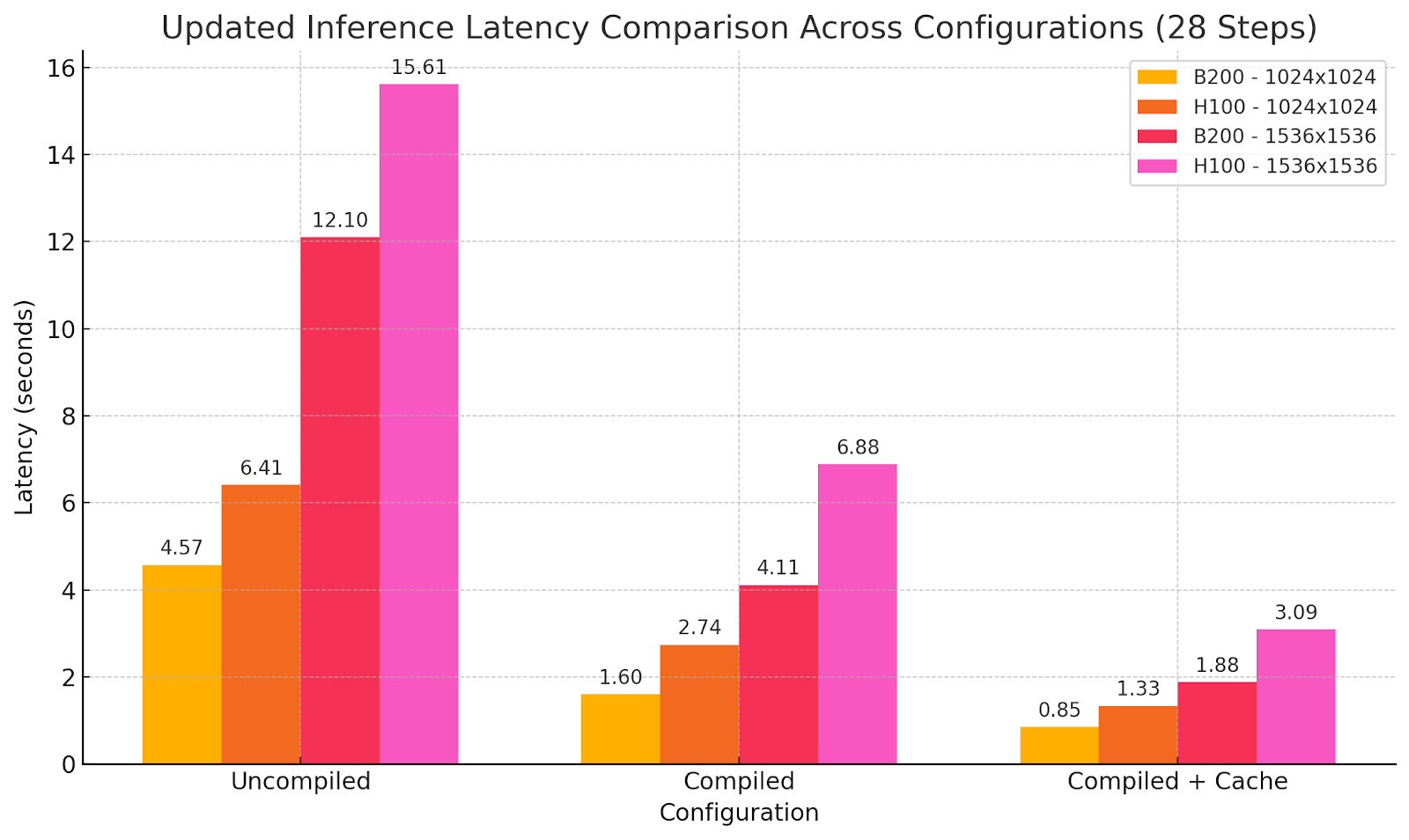
使用不同優化設置的模型輸出:

提示詞:橙色頭巾的另類女性的照片,淺棕色長髮,透明框架眼鏡,鼻中隔穿孔 [sic],米色背帶褲從一個肩膀掉下,裡面穿著白色管狀上衣,她坐在她公寓的波西米亞風地毯上,風格為時尚雜誌拍攝
影響
性能改進帶來了以下優勢:
- AI 算法設計(例如 DiT 激活緩存)和** 系統優化**,使用 GPU 架構調優的內核,以獲得更好的硬件利用率;
- 降低推理延遲,開啟新的可能性(例如擴散模型中的測試時間計算);
- 每張圖像的成本更低,由於效率提高和硬件利用率降低。
我們已實現 B200 等同於 H100 成本效益比但延遲時間減半。因此,每次生成的成本不增加,同時現在能夠實現新的實時可能性,而不犧牲模型功能。有時候更多並不是更好,而是不同,在這裡我們已經實現了性能的新階段,為使用 SOTA 模型的圖像生成提供了新級別的用戶體驗。
這實現了敏捷的創意工具、可擴展的內容平台和生成式 AI 大規模應用的可持續成本結構。
結論和後續步驟
使用 B200 的 FLUX-dev 部署展示了當世界級硬件遇上最佳級別軟件時的可能性。我們在 WaveSpeedAI 推進推理速度和效率的前沿,WaveSpeedAI 由 Zeyi Cheng 創立 — stable-fast、ParaAttention 和我們內部推理引擎的創造者。在下一個版本中,我們將專注於高效視頻生成推理,以及如何實現接近實時的推理。我們與 DataCrunch 的合作代表了一個訪問 B200 等尖端 GPU 和即將推出的 NVIDIA GB200 NVL72(從 DataCrunch 預訂 NVL72 GB200 集群)的機會,同時共同開發關鍵推理基礎設施堆棧。
立即開始:
加入我們,共同構建世界上最快的生成式推理基礎設施。



