OmniHuman-1.5:Toward Virtual Humans with “Soul”

你曾經看過配有流暢動畫數字人物的視頻,但感覺他們缺乏真實情感嗎?為了克服這一限制,我們推出了由字節跳動開發的OmniHuman-1.5——一個突破性框架,旨在生成超越表面模仿的角色動畫。它不僅為虛擬化身帶來生命,還賦予他們表達情感的能力。
從模仿到表達:技術突破
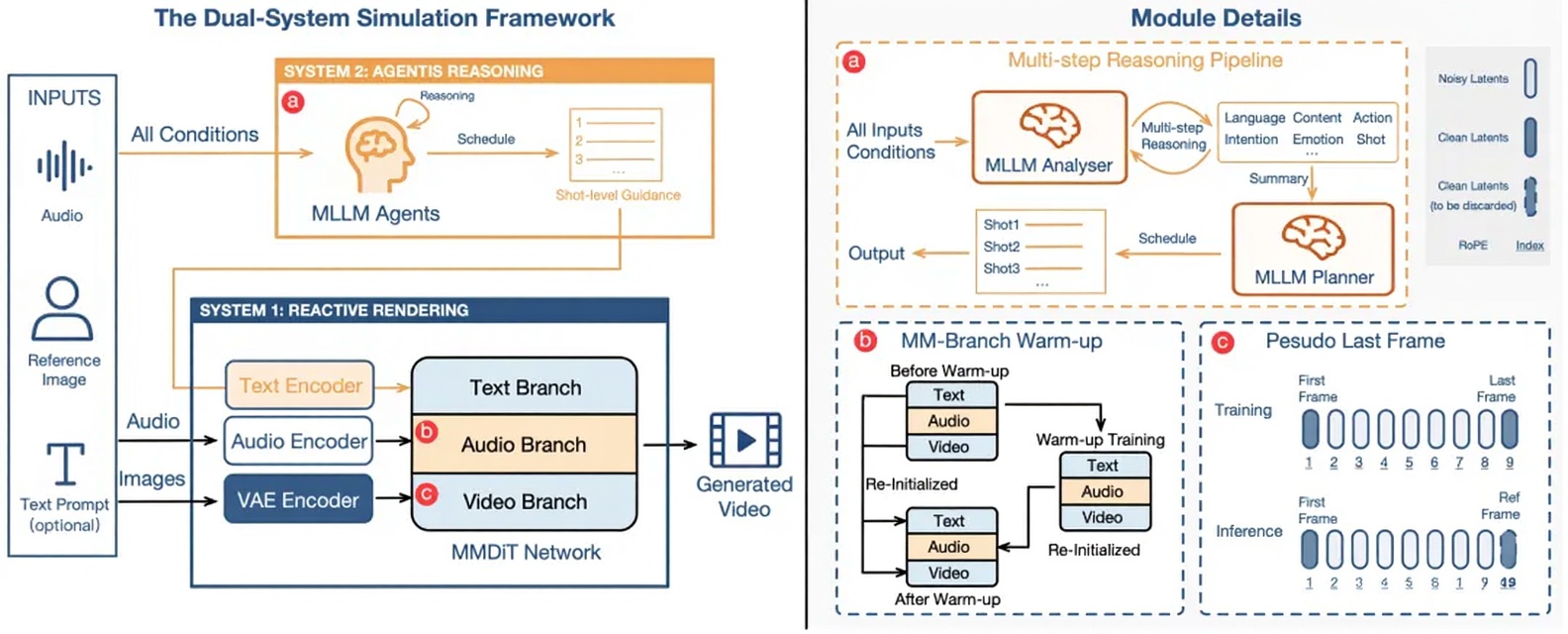
OmniHuman-1.5 採用雙系統模擬框架。
首先,該方法利用多模態大型模型生成結構化語義表示,提供高級語義指導,使動作生成能夠超越單純的節奏同步,更好地與上下文和情感相一致。
其次,通過特殊設計的多模態 DiT 架構和偽端幀機制,它能有效融合多模態信息,同時減輕衝突,從而生成與角色、場景和語言高度一致的動作。
OmniHuman-1.5 能做什麼?
🎶音樂表演
只需一張照片和一首歌曲,OmniHuman-1.5 就能創建一個「數字歌手」,精確模仿藝術家的停頓、呼吸和節奏。
🎭情感表演
OmniHuman-1.5 不僅可以創建數字歌手,還可以製作充滿情感的數字演員。
🗣️上下文感知手勢
動畫不是重複的手勢,而是與意義相符。例如,當音頻提到「心」時,角色自然地將手放在胸口。
✍️文本引導動畫
OmniHuman-1.5 支持提示控制。示例包括:
- 攝像機運動:「攝像機緩慢環繞角色,呈現藝術電影風格。」
- 物體生成:「化身伸向鏡頭,然後開始說話。」
- 特定動作:「一隻企鵝跳舞、戴著太陽眼鏡並在舞台上表演。」
👥多角色和風格化場景
與以前的數字人物不同,OmniHuman-1.5 可以進行集體對話和集體表演。
它也適用於人類、動物、擬人化人物和風格化卡通,展現了非凡的多功能性。
結論:邁向具有「靈魂」的虛擬人物
虛擬人物技術取得了新的突破。OmniHuman-1.5 的出現標誌著一個新時代的到來,虛擬人物已從表面模仿進化到深度表達。它能理解你所說的話,並與你進行真摯、發自內心的溝通。讓我們期待 OmniHuman-1.5 模型的推出!
立即在 WaveSpeedAI 上註冊。此外,你可以在下面的社交媒體上與我們聯繫。
Discord:Discord



