LTX-2 NVFP4 vs NVFP8:速度、品質與 VRAM 比較(RTX 指南)

我沒有刻意尋找精度設定。我是在LTX-2在批量渲染時不斷推動我的16GB GPU接近極限時才碰到的。預覽卡住了,風扇呼嘯著,而那個小下拉菜單——NVFP4或NVFP8——突然不再像一個細節選項,而是度過難關的方式。
在過去一周(2026年1月),我在幾個穩定、乏味的場景中測試了LTX-2的NVFP4和NVFP8:1080p和2K的短片用於概念通過,以及幾個4K靜幀和平移用於客戶情緒板。沒什麼了不起的。就是那種堆積起來的工作。以下是我注意到的、有效的,以及每種設定無聲地幫助或阻礙的地方。
NVFP4 vs NVFP8 解釋(一句話總結)
 NVFP4為了降低VRAM和更快的吞吐量而犧牲一點品質和穩定性:NVFP8保留細節效果更好但對GPU的要求更高。
NVFP4為了降低VRAM和更快的吞吐量而犧牲一點品質和穩定性:NVFP8保留細節效果更好但對GPU的要求更高。
速度 / VRAM / 品質權衡矩陣
我會簡化這一點,因為現實很簡單。
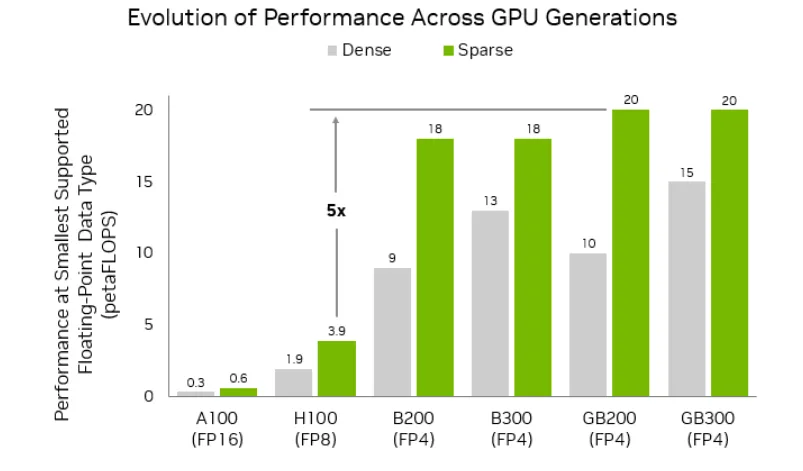
- 速度: NVFP4在我的測試中通常快15–30%,取決於解析度和批次大小:NVFP8略有變慢但保持一致。
- VRAM: NVFP4為我減少了大約25–40%的內存佔用:NVFP8使用更多但減少了偽影。
- 品質: NVFP8保留了精細邊緣(頭髮、標牌、微紋理)並減少了運動中的閃爍:NVFP4使細節變軟,有時會增加小的時間抖動。
就是這樣的情況。其他的都是因情況而異。
在RTX 4090(24GB)和4080(16GB)上進行可重複測試的一些現場筆記:
- 1080p,短片(4–6秒):NVFP4保持預覽流暢,讓我可以提高批次大小:NVFP8逐幀保持面部和文字更清潔。
- 2K,中等片長(8–12秒):NVFP4適合首次通過:NVFP8在平移時避免了紋理上的微小「爬行」。
- 4K,靜幀:NVFP8值得。我寧願多等一會,也不願花時間修飾邊緣。
這些都不算戲劇化。但我能感受到。NVFP4的VRAM壓力更小意味著更少的中斷。NVFP8的輸出更清潔意味著更少的重做。
何時使用NVFP4(批量生產 / 低VRAM)
 當我更關心流程而非完成度時,我會選擇NVFP4。
當我更關心流程而非完成度時,我會選擇NVFP4。
NVFP4的幫助之處
- 批量概念通過:我可以在16GB上以1080p並行運行3–6個提示,不需要調整內存。這意味著我能保持流程並更快地比較選項。
- 粗剪和分鏡:對於帶有佔位符鏡頭的快速板,輕微的柔和並無所謂。它實際上隱藏了奇怪之處。
- 長時間會話:VRAM迴旋空間意味著更少的重啟。少一點摩擦會在一天內累積。
我實際注意到的權衡
- 微觀細節丟失:精細圖案(網眼、髮線類型、小反射)略有變淡。沒有壞掉,只是不那麼清晰。
- 時間穩定性:在緩慢平移上,NVFP4有時在高頻區域引入微小閃爍。在時間軸上並不總是很明顯,但在暫停時會顯示出來。
對我來說感到安全的實際範圍
- 1080p,短片:NVFP4搭配適度批次大小(2–4)舒適地低於16GB。
- 2K,短片:NVFP4如果我不推高上下文長度,在16GB上保持順暢。
為什麼使用它:NVFP4是一個很好的「思考精度」。它降低了探索想法的成本。如果輸出只是供你或團隊檢查,NVFP4使LTX-2感覺輕量。
何時使用NVFP8(品質 / 精細細節)
當我準備完成時,我切換到NVFP8。
NVFP8值得的地方
- 套牌的最終幀:如果一幀可能會旅行、客戶分享、作品集或社群媒體,NVFP8會減少清理。
- 面部和手:邊緣保留得更好,睫毛/髮線周圍的小抖動平息了。
- 文字和標牌:不完美,但更經常清晰。更少的重新渲染只是為了修復抖動的字母。
需要接受的成本
- 更重的VRAM:在16GB上,我在2K時保持低批次大小,並避免在同一圖形中堆疊額外節點。
- 慢一點:我不介意等待,因為我只在喜歡該鏡頭後才運行NVFP8。
如果你甚至觸及4K靜幀,NVFP8是更安全的預設。我試圖在4K上使用NVFP4節省時間:我花了那段時間來清理邊緣。
按解析度配置表(1080p / 2K / 4K)
這些不是規則。它們讓我保持移動而無需不斷調整。硬體很重要。這是在以下基礎上:
- RTX 4080 16 GB(桌面)
- RTX 4090 24 GB(工作室機器)
定義:
- 「批次」在這裡 = 在一個圖形運行中的並行提示或片段。
- 「上下文/長度」 = 你的序列運行多長或你打包多少調節。
1080p (1920×1080)
- 16 GB:NVFP4,批次3–4,短片(≤6秒)感到安全:NVFP8,批次2,穩定。
- 24 GB:NVFP4,批次6–8容易:NVFP8,批次3–4,還有額外空間。
2K (2048×1152 or 2048×1536)
- 16 GB:NVFP4,批次2–3:NVFP8,批次1–2:保持上下文適度。
- 24 GB:NVFP4,批次4:NVFP8,批次2–3,注意節點堆疊。
4K (3840×2160)
- 16 GB:NVFP4,僅單個,短上下文:NVFP8,單個,要有耐心。
- 24 GB:NVFP4,在精簡圖形中批次2:NVFP8,單個或批次2,如果其他節點很輕。
你超出極限的迹象:
- 在擦洗或中途改變種子時VRAM尖峰。
- 輸出開始時很好但在後來的幀中退化。
- ComfyUI預覽在幀之間暫停的時間比平常長。
如果你遇到任何這些,先降低批次大小。然後縮短序列。精度通常是我最後拉動的槓桿。
如何在ComfyUI中切換精度
這取決於你使用的節點包,但以下是我看到的(2026年1月):
- 模型加載器或LTX-2節點:通常有一個精度或Dtype下拉菜單。我看到過NVFP4、NVFP8和float16等選項。我在那裡切換它並保持圖形的其餘部分不變。
- 如果沒有下拉菜單:檢查節點的文檔或儲存庫自述。有些構建從全局配置或環境標誌繼承設定。
- 混合圖形:如果你將LTX-2與升級器或後節點鏈接,要注意dtype不匹配。大多數節點自動轉換,但有時你要支付隱藏的內存稅。
對我有效的
- 保存同一圖形的兩個版本:一個命名為
_fp4用於探索,一個_fp8用於最終版本。這樣我就不用尋找切換。 - 在NVFP4通過時保持預覽啟用。如果預覽卡頓,這通常表示即使對於fp4,我的批次或上下文也太高了。
如果你想要具體細節,官方文檔或節點儲存庫通常會說明精度標誌是如何傳遞的。當有些東西感覺不對時,我會交叉檢查這些。
在WaveSpeed上測試兩者
我不是單獨依靠我的眼睛,而是依靠一個簡單的迴圈:相同提示、相同種子、兩次運行,一次在NVFP4,一次在NVFP8,用一個小WaveSpeed工作流計時,並在側面用秒錶。我不那麼關心確切的數字,更關心差異的形狀。
我測量的(大約)
- 吞吐量:NVFP4在我的16GB機器上持續快15–30%完成:在24GB機器上接近20%。
- VRAM迴旋空間:NVFP4在1080p時留給我2–4GB額外空間,讓我保持一個輕型去噪節點活動。NVFP8吃掉了那個邊距。
- 視覺效果:在一個通過磚塊和樹葉的緩慢平移上,NVFP8保留了紋理。NVFP4略有模糊並增加了一點閃爍。在運動密集的片段上,我幾乎沒注意到。
WaveSpeed(或無論你使用什麼基準機器)幫助我保持誠實。我運行三對並拋出第一對作為預熱。然後我問一個乏味的問題:這個設定為我節省了步驟嗎?如果答案是肯定的,它就堅持下來。
如果你想比較NVFP4和NVFP8而不用擔心本地VRAM限制,WaveSpeed讓你在更大的雲GPU上運行相同的LTX-2提示和種子。這是在鎖定設定之前檢查速度、內存迴旋空間和視覺權衡的直接方式。
 誰可能更傾向於哪個:
誰可能更傾向於哪個:
- 如果你在大量分鏡、原型化功能或製作社群優先概念,NVFP4與截止日期很搭。
- 如果你在交付將被暫停、放大或打印就緒的幀,NVFP8賺取其價值。
我不會聲稱一個更好。它們是不同的檔位。既然我已經命名了每個什麼時候有幫助,我現在的切換頻率就少得多了。
我在筆記本角落保留的一個小注解:當一個渲染感覺「嘈雜」難以判斷時,這通常不是精度問題,而是設定蔓延問題。我先削減變數,然後切換NVFP4/NVFP8。
我會在這裡結束。昨天,NVFP8為我節省了我會在4K靜幀上清理邊緣花費的一小時。今天早上,NVFP4讓我一次預覽四種外觀而不用風扇聽起來像起飛。我不需要超過那個。





