下載 LTX-2 模型:Hugging Face 檔案、大小與資料夾結構

我第一次尋找 LTX-2 下載 時,這並不是一項宏大的計畫。我只是想在 ComfyUI 上執行一個小批次,卻一再遇到同樣兩個問題:下載速度很慢,在 92% 處停滯,最後終於有了檔案後卻出現神秘的「找不到模型」訊息。沒什麼戲劇性的。只是那種反覆出現的小煩惱,促使你停下來整理工作流程。
我在 2026 年 1 月初花了幾個晚上,在一台 24GB GPU 機器上測試不同的來源、格式(NVFP4 vs NVFP8)和資料夾佈局。沒什麼花哨的,只是足夠的執行次數來看看什麼是穩定的,什麼是脆弱的。以下是為我減少混亂的方法,附註你可以快速查閱並借鑑。
官方 LTX-2 下載來源(Hugging Face 模型卡)
 我不會追蹤鏡像。如果一個模型對我的工作流程很重要,我希望這個過程是單調而可靠的。對於 LTX-2,這意味著從官方 Hugging Face 模型卡 開始。
我不會追蹤鏡像。如果一個模型對我的工作流程很重要,我希望這個過程是單調而可靠的。對於 LTX-2,這意味著從官方 Hugging Face 模型卡 開始。
在點擊下載前我會檢查的事項:
- 發行者: 這是與 LTX-2 相關聯的經過驗證的組織或作者嗎?我會檢查組織徽章,以及該命名空間中的其他倉庫看起來是否活躍且一致。
- 授權與條款: 某些 LTX-2 變體可能是閘道式的或有使用限制。如果接受條款需要令牌,我寧願一次性做好也不要後來除錯身份驗證錯誤。
- 成品清單: 我會快速查看主模型、任何編碼器和任何蒸餾或量化變體。清晰的檔名勝過聰明的檔名。
- 說明: 如果卡片連結到 ComfyUI 或特定節點的文件,我會先遵循那些。關於預期資料夾的一行說明可以節省半小時的猜測。
實用提示: 使用 Hugging Face CLI 並設定認證。閘道式倉庫不會在沒有令牌的原始 git-lfs 上拉取,這是最快導致檔案不完整且在嘗試載入前沒有錯誤的方式。
pip install huggingface_hub git-lfs
huggingface-cli login # 貼上你的令牌我知道,很明顯。但我見過無聲的 403 變成下游「找不到模型」的次數…非零。
檔案清單與大小(主模型 / 編碼器 / 蒸餾版本)
我不會記住檔案大小。我只是需要一個大致估計來規劃磁碟空間並決定先取哪個變體。以下是我在最近 LTX-2 版本中實際看到的內容。你的倉庫可能不同,始終相信模型卡而不是我的筆記。
你會看到的典型成品:
- 主模型檢查點(通常是
.safetensors或特定運行時格式):約 2.5–6.0 GB。如果包含額外頭或多精度則更大;如果量化則更小。 - 文本/影像編碼器(CLIP 或類似):約 400 MB–1.5 GB。某些構建會捆綁此項;其他則作為單獨檔案提供。
- VAE 或潛在適配器(如適用):約 100–500 MB。
- 蒸餾變體:約 1–3 GB。更快更輕,有時輸出稍微柔和。適合原型設計。
- 量化變體(NVFP8/NVFP4):大小不同,但預期磁碟空間比完整精度少 30–60%。
我注意的命名模式:
ltx-2.safetensors(主模型)ltx-2-encoder.safetensors或open_clip-vit-…(編碼器)ltx-2-vae.safetensors(如果分開)ltx-2-distilled-…(更小、更快)ltx-2-nvfp8/ltx-2-nvfp4(格式特定)
如果磁碟空間緊張,我先取蒸餾版本,驗證我的管道,然後拉取完整模型。這不只是關於速度:減少第一次執行的認知負擔有助於我測試提示和節點,而不是立即與 VRAM 對抗。
LTX-2 的 ComfyUI 資料夾結構(精確路徑)
這是我第一天絆倒的地方:我的檔案沒問題,但 ComfyUI 不知道去哪裡找。不同的自訂節點期望略有不同的位置,但以下預設對我一直都很安全。
在標準 ComfyUI 安裝 上(無自訂節點覆蓋):
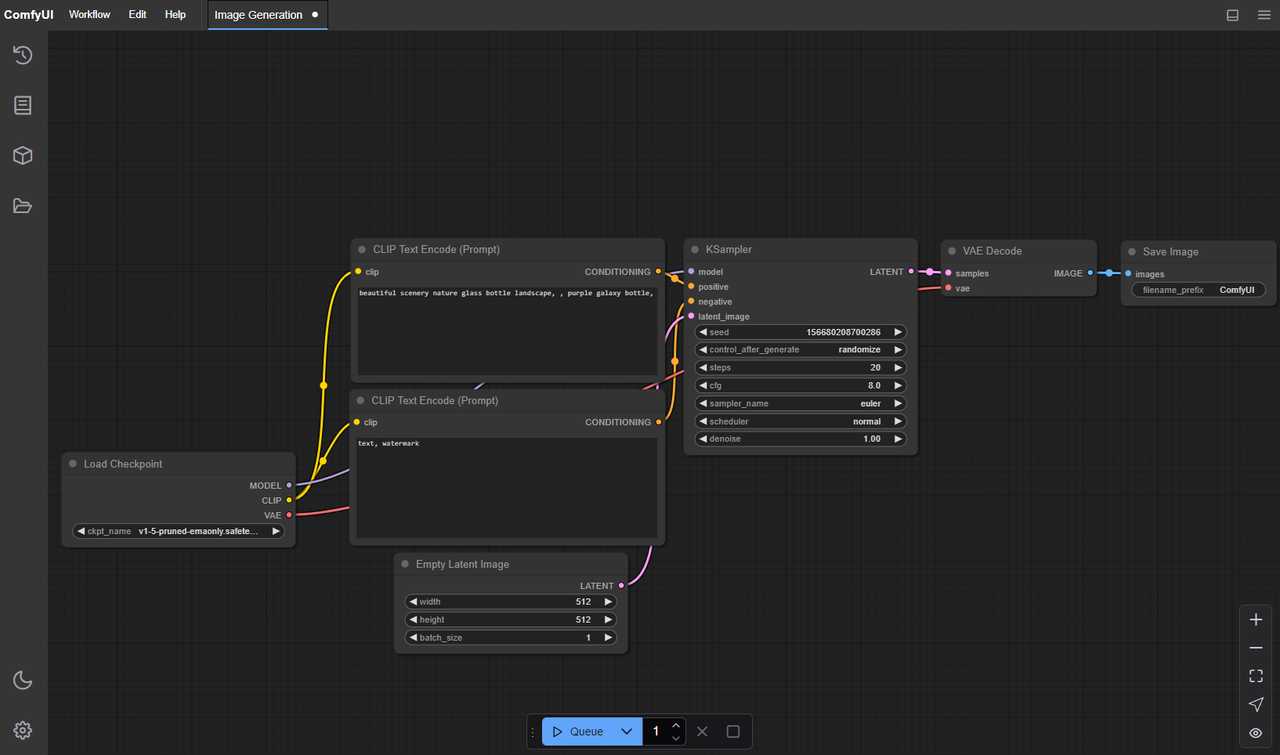
- 主模型檢查點:
ComfyUI/models/checkpoints/LTX-2.safetensors - 文本/影像編碼器(CLIP 或類似):
ComfyUI/models/clip/LTX-2-encoder.safetensors- 某些構建使用 open_clip 命名:也將那些放在
models/clip/中。
- 某些構建使用 open_clip 命名:也將那些放在
- VAE(如果分開):
ComfyUI/models/vae/LTX-2-vae.safetensors - LoRA/補丁(如果你使用):
ComfyUI/models/loras/
如果你使用依賴 TensorRT 或引擎檔案的節點:
ComfyUI/models/trt/ltx-2/*.engineComfyUI/models/unet/ltx-2/*.engine
兩個無聊但有用的習慣:
- 將檔名與你的節點期望的完全匹配。我保持名稱簡短並移除空格。
- 移動檔案後,使用 ComfyUI 的模型刷新或重啟。熱重載有時有效:完整重啟更一致。
如果你使用外部磁碟或共享模型資料夾,設定 ComfyUI 的額外模型路徑,以免它默默掃描錯誤的磁碟。Linux 上的大小寫敏感性讓我吃過不止一次的虧。
NVFP4 vs NVFP8 權重:下載哪個
 我很好奇 NVFP4 是否值得額外的壓縮。簡短的答案:也許吧,如果你 VRAM 緊張且你的節點實際支援它。
我很好奇 NVFP4 是否值得額外的壓縮。簡短的答案:也許吧,如果你 VRAM 緊張且你的節點實際支援它。
以下是它在我的機器上實際感受(Hopper 級 GPU,2026 年 1 月構建):
NVFP8
- 平衡:很好的折衷方案。相比完整精度明顯較低的記憶體,輸出漂移最小。
- 相容性:更好。目前更多節點和運行時接受 FP8 而不是 FP4。
- 何時選擇:我想要穩定性而不是最小佔用空間的日常執行。
NVFP4
- 佔用空間:更小。它讓我在 FP8 不會的地方提升解析度或上下文。
- 漂移:邊界情況下稍微多一些偽影或柔和度。不總是,但足以讓我注意到。
- 相容性:更挑剔。如果某些載入器沒有偵測到正確的核心,它們會回退或失敗。
- 何時選擇:快速草稿、網格搜索,或當工作流程嚴格由節點的 FP4 路徑支援時。
還有一件事:這些格式通常假設你在可以適當加速它們的 NVIDIA 堆疊上。如果你的節點沒有明確說「支援 NVFP4/NVFP8」,我預設為完整精度或蒸餾 .safetensors 構建。追蹤邊際收益不值得神秘的中途崩潰。
LTX-2 下載加速與校驗和驗證提示
我像對待任何其他大檔案工作一樣處理大模型拉取:加速它,然後驗證。
實際有幫助的加速:
- Hugging Face 傳輸加速:在使用
huggingface_hub之前設定環境變數HF_HUB_ENABLE_HF_TRANSFER=1。這在可用的地方啟用他們的加速後端。
aria2c 用於平行分塊:
aria2c -x 16 -s 16 -k 1M -c-c 旗標在我的連線在 97% 時打嗝時乾淨地恢復部分下載。
git-lfs 調整拉取
git lfs install然後git clone。- 遵循 Git LFS 安裝指南,如果是一個巨大的倉庫,我有時會使用稀疏簽出來避免拉取我不會使用的範例。
我實際做過的驗證(也不再跳過)
將模型卡(或倉庫的 .sha256 檔案)中的 SHA256 與你的本地檔案進行比較。
- macOS/Linux:
shasum -a 256 - Windows:
certutil -hashfile SHA256
檔案大小合理性檢查
- 如果預期大小是 4.2 GB 但我看到 3.3 GB,我會停在那裡。部分檔案有時可以「載入」,然後稍後拋出垃圾錯誤。
一個小習慣能節省時間:我在模型檔案旁邊放一個小的 README.txt,其中包含原始 URL、日期和雜湊。當我三個月後重新訪問時,我不必反向工程我過去的選擇。
「找不到模型」修復
這個錯誤花了我一小時我拿不回來。以下是對我實際有幫助的修復:
- 資料夾錯誤: ComfyUI 期望檢查點在
models/checkpoints/中,編碼器在models/clip/中,VAE 在models/vae/中。將它們放在其他地方,掃描器可能會忽略它們。 - 檔名不符: 某些節點尋找特定的基名。如果節點說
ltx-2.safetensors,不要叫它LTX-2 (final).safetensors。我會激進地重新命名。 - 大小寫敏感性:
ltx-2.safetensors≠LTX-2.safetensors在 Linux 上。問我怎麼知道的。 - 快取索引: 移動檔案後刷新模型或重啟 ComfyUI。索引不總是即時的。
- 缺少依賴: 如果節點期望外部編碼器而你只下載了主模型,你會得到一個模糊的錯誤。拉取模型卡上列出的編碼器並再試一次。
- 沒有令牌的閘道式模型: 如果你在不登入的情況下克隆(或你的令牌過期),本地檔案可能是存根。使用
huggingface-cli login重新登入並重新拉取。 - 自訂節點和替代路徑: 某些節點會覆蓋預設資料夾。檢查他們的 README 以了解預期的路徑或環境變數。有疑問時,從你的共享模型目錄到預期的本地路徑建立符號連結。
當我卡住時,我暫時將節點指向一個已知良好的小模型,只是為了確認載入器有效。如果小的載入,bug 就在 LTX-2 檔案中,而不是我的環境中。
使用 WaveSpeed 跳過 LTX-2 下載
我在旅行筆記本上嘗試了不同的路線:完全跳過本地下載,通過 WaveSpeed 執行 LTX-2。它遠程流式傳輸或託管權重,讓你可以連接類似 ComfyUI 的圖形,而無需將 10+ GB 停在磁碟上。
 對我有效的東西:
對我有效的東西:
- 入職很輕鬆。我將圖形指向他們的 LTX-2 端點,沒有接觸本地資料夾。
- 冷啟動更慢(第一次執行會啟動一個會話),但溫啟動對小批次感覺正常。
- 它防止我的筆記本電腦風扇狂鳴。僅此一項就讓它在路上很有用。
我注意到的權衡:
- 延遲: 有一個小開銷,對許多短執行更明顯。對於長渲染,我停止注意。
- 控制: 你放棄了某些版本釘選。他們保持模型修補,這很好,直到你想重現一個較舊的結果。
- 成本/配額: 它不是「像下載一樣免費」。如果你的預算緊張或需要大量批次工作,本地仍然獲勝。
- 隱私: 我將敏感的提示和資產保存在本地。對於公開或測試工作,我很好。
誰可能喜歡這個: 在性能不足的機器上測試 LTX-2 的人,或任何想在承諾完整本地設定前素描工作流程的人。如果你 VRAM 豐富且關心精確的可重現性,本地安裝仍然感覺更好。
我不認為我會喜歡它,但對於快速實驗,跳過下載是一點小安慰。





