ComfyUI-LTXVideo 擴展:LoRA 支援、工作流程與使用時機

我第一次嘗試ComfyUI LTXVideo時,並不是在追求新功能。我只是想要一個穩定的方式,能夠將粗糙的分鏡腳本轉變為動作,而不必逐幀監督。我的小摩擦點是:漫長的一天後又出現一個「缺少節點」的錯誤。我幾乎要關閉窗口了。但我還是給了它一週的時間(2026年1月初),並將其應用於幾個真實的項目:一個12秒的產品循環、一個課程教學片段,以及其中一個紋理到動作的實驗,看起來要麼巧妙,要麼令人詛咒。 我發現的不是魔法。但它確實在一些寧靜的地方使工作感覺輕鬆了一些。這通常是我尋找的信號。
核心內置與擴展:有什麼區別
我一直看到人們談論「ComfyUI中的LTXVideo支持」,但不清楚什麼是原生的,什麼需要額外的部件。以下是我在實踐中注意到的。
- 核心(ComfyUI基礎):你可以連接通用的文字到圖像/視頻流、安排採樣器並管理條件。基礎應用在數據路由、預覽幀和保持運行可重現性方面表現堅實。但默認情況下它不提供專門的LTX-Video節點。
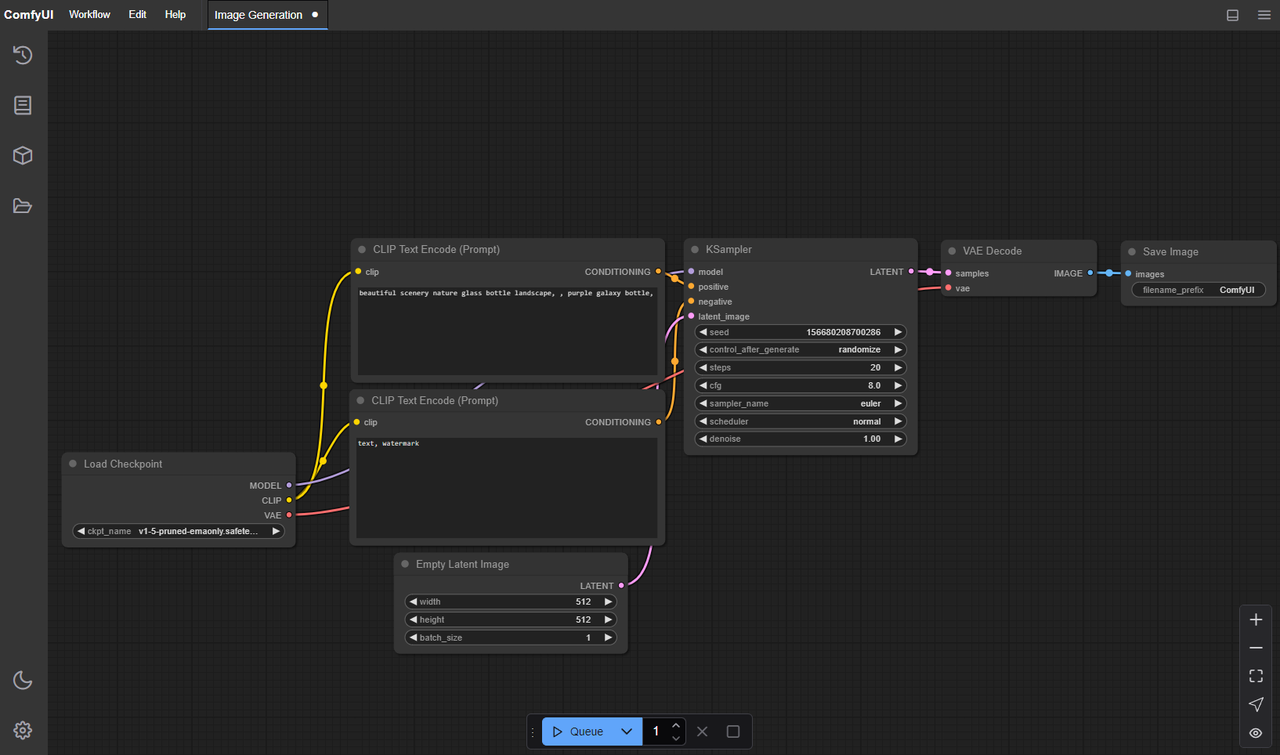
- 擴展(LTXVideo自定義節點):這增加了圍繞LTX-Video架構構建的模型感知節點(加載器、採樣器、條件塊)。該擴展理解模型的運動長度、上下文窗口以及不能清楚映射到通用節點的小約束。
當你試圖減少手動粘合代碼時,區別就顯現出來了。只有核心節點,我在處理張量形狀、猜測默認值並遇到形狀不匹配的問題。安裝擴展後,圖表變短了,錯誤減少了。我仍然需要思考,只是不是關於管道的。
一個小例子:我使用場景一致的照明構建了一個8–12秒的循環。僅核心花費了我約45分鐘來穩定:我得告訴你,擴展版本在第二次嘗試時運行得很順利(約15分鐘),因為預先設置的採樣器和視頻組裝器處理了幀對齊,無需我費力處理。
所以,如果你在評估:如果你喜歡完全控制並且不介意連接,核心是足夠的。當你更關心可重複的運行而不是手動調整的管道時,擴展是為你設計的。
擴展添加的內容(工作流程/節點/LoRA)
當我點擊示例圖表時,我沒有期望太多,我已經看過太多基本上是屏幕截圖的「入門」工作流程。這些比那要好。
對我有幫助的是:
- 專用節點:LTX-Video的模型加載器、一個避免奇數幀數的運動長度選擇器,以及尊重模型時序甜蜜點的採樣器。它們消除了通常只在失敗渲染後出現的幾個陷阱。
- 示例工作流程:三個我一直回到的,文字到視頻基礎、帶運動注入的圖像到視頻,以及使用LoRA的風格轉移。每個都清晰到足以開始,但不是那麼死板,以至於你無法交換部分。
- LoRA掛鉤:擴展清楚地展現LoRA強度和組合。我可以堆疊風格LoRA和輕身份LoRA,同時保持運動穩定。我得說,在早期視頻設置中這是罕見的。
一個小驚喜:默認色彩處理感覺比我嘗試過的大多數開源視頻模型都更平靜。藍色不會爆炸。皮膚保持在可信的範圍內。我仍然需要調整曝光,但我沒有在與飽和度作戰。
我遇到的限制:
- 長序列(超過約12–16秒)會漂移,除非我引入錨點關鍵幀或分割運行。在這個階段這很正常,但值得注意。
- 重的LoRA堆疊可能會使運動不穩定。兩個可以,三個是冒險的,除非你減少強度。
安裝與更新步驟
準備
- 將ComfyUI更新至最近的構建。我在兩台機器上都使用了2026年1月的每夜構建。
- Python 3.10–3.11最合適。我為每台機器保持了一個新鮮的venv。
安裝LTXVideo擴展
- 如果你有的話,使用ComfyUI-Manager:搜索「LTXVideo」或「ComfyUI-LTXVideo」並安裝。
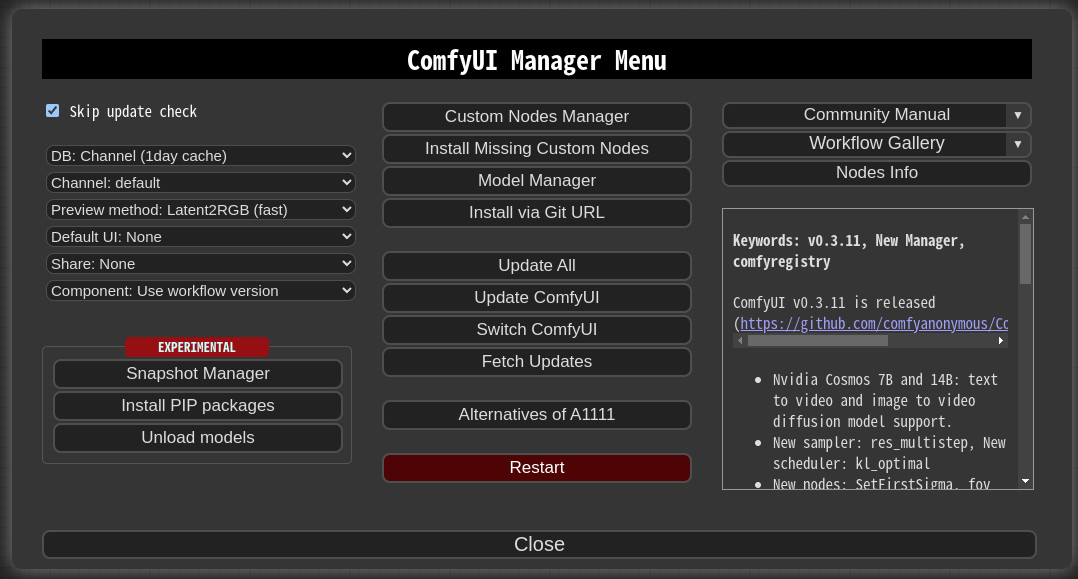
- 手動路由:將儲存庫克隆到ComfyUI/custom_nodes中。然後在你的環境中安裝要求(
pip install -r requirements.txt)。
模型
- 將LTX-Video檢查點放在擴展期望的位置。大多數版本在
models/ltxvideo或models/checkpoints下查找:節點通常在懸停時告訴你確切的路徑。 - 如果你使用LoRA,將它們放在
models/loras下(或節點列出的任何默認值)。
CUDA和運行時
- 使用CUDA 12.x和PyTorch 2.3+的Linux運行順利。在macOS上,Metal可工作,但我保持批量大小小。
- 如果你在首次運行時看到內存峰值,減少運動長度或設置較低的解碼精度,如果節點公開它。
更新
- 從擴展儲存庫拉取最新內容。當主要提交到達時重新安裝要求(我遇到了一個torch-vision不匹配和一個protobuf碰撞:兩者都通過乾淨重新安裝修復)。
- 如果更新後節點沒有出現,清除ComfyUI緩存。快速重啟通常解決陳舊的導入。
時間成本:在乾淨的Linux盒子上首次安裝耗時約20分鐘,在macOS上約30分鐘,因為我必須重新鏈接幾個metal構建。更新是分鐘級的,除非依賴項改變。
示例工作流程演練
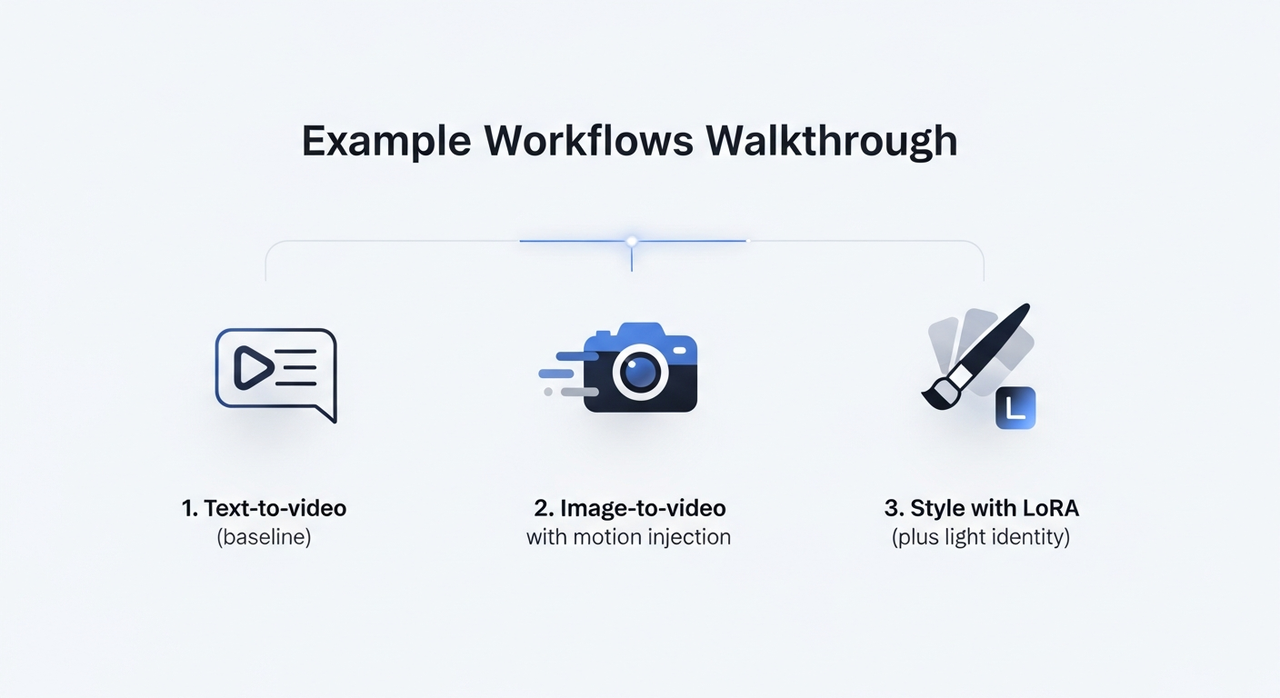 我多次運行三個工作流程,進行了足夠的調整以查看它們的穩定性如何。
我多次運行三個工作流程,進行了足夠的調整以查看它們的穩定性如何。
1. 文字到視頻(基準)
- 設置:提示、負面提示、LTX-Video加載器、模型的採樣器和一個短邊512–768的視頻寫入器。我將運動長度保持在8–12秒。
- 觀察:第一遍很少能夠精確掌握精確的步調,但它給了我一個穩定的「基礎拍攝」。第二遍進行細微的提示編輯修復了大多數問題。每個渲染在A6000上是2–4分鐘,在M3 Max上是約6–8分鐘。
- 小提示:如果運動看起來飄浮,收緊時間指導或減少一點CFG。對我來說,4.5–6.5是可用範圍。
2. 圖像到視頻,帶運動注入
- 設置:單個參考圖像,加上低強度風格LoRA以保持紋理一致。我使用擴展的運動節點來輕推相機漂移,而不是讓它發明運動。
- 觀察:這在首次嘗試時沒有節省時間,我過度調整了。在第三次運行中,我意識到它降低了心理負擔:更少的偽影要分類,更少的「那角落裡是什麼?」驚喜。
- 實用注意:如果主體在第3–5幀周圍扭曲,添加中序提示圖像或錨點幀。我為10秒的片段使用了兩個錨點,感覺它被鎖定了。
3. 風格與LoRA(加上輕身份)
- 設置:基礎提示、一個0.6–0.8的風格LoRA、0.2–0.3的身份LoRA和保守的運動。
- 觀察:組合比我預期的保持得更好。強度超過0.8的風格開始對紋理進行「閃耀」,對海報很好,對運動很奇怪。保持身份低避免了不自然的轉變。
- 輸出:我寫入ProRes以進行分級。H.264非常適合快速檢查,但當我在Resolve中進行輕微傳遞時,顏色看起來更好。
在整個運行中,與拼接通用節點相比,我為每個片段節省了約15–20分鐘。更大的優勢是更少的重新啟動。更少的調整,更多的決定。
LoRA與IC-LoRA基礎
 我傾向於只在需要時才使用LoRA。使用LTXVideo,它們值得額外的步驟,特別是為了一致性。
我傾向於只在需要時才使用LoRA。使用LTXVideo,它們值得額外的步驟,特別是為了一致性。
- LoRA:把它看作一個輕微的風格指紋。在視頻中,輕輕推動。強度超過約0.8,隨著運動積累看起來很脆。
- 身份LoRA:有助於在幀之間保持角色或產品穩定。我喜歡0.15–0.35範圍內的值。
- IC-LoRA(圖像條件LoRA):這是我發現最實用價值的地方。將乾淨的參考圖像饋入IC-LoRA穩定了細節(標誌、臉部),而不凍結場景。我使用了一個清晰的正面圖像,有時還使用側角作為次要提示。
實踐中重要的是:
- 乾淨的參考勝過聰明的提示。垃圾進,垃圾出,在運動中表現得更明顯。
- 混合更少,輕調。兩個LoRA輕輕應用比三個彼此戰鬥要好得多。
- 如果出現微抖動,重新播種。一個新的種子加相同的錨點通常解決了微小的面部閃爍。
「缺少節點」修復
在測試時我遇到了三種「缺少節點」。沒有一個是戲劇性的,但它們確實破壞了流程。
- 擴展未加載:確保LTXVideo文件夾位於
ComfyUI/custom_nodes下,並且它有一個__init__.py。重啟ComfyUI。如果日誌顯示導入錯誤,為該節點重新安裝要求。 - 依賴漂移:Torch/CUDA不匹配出現為導入錯誤。對齐擴展自述文件中列出的PyTorch和CUDA版本。新鮮的venv比調試纏繞的venv更快。
- 舊工作流程,新節點:某些圖表引用已重命名的節點。打開JSON,搜索節點類,並將其映射到新名稱。擴展CHANGELOG通常注意到這些。
快速健全檢查:
- 更新ComfyUI-Manager,然後「掃描更新」。
- 清除ComfyUI的緩存並重啟。
- 確認加載節點中的模型路徑,缺少檢查點看起來就像從UI的角度看缺少的節點。
在WaveSpeed上應用這些工作流程
我嘗試了一個雲運行,看看這如何轉換到遠離我的桌子。在WaveSpeed上,我用RTX級GPU啟動了ComfyUI工作區,並以相同的方式放入LTXVideo擴展。
 如果你走這條路的兩個注意事項:
如果你走這條路的兩個注意事項:
- 保持你的模型有序:我首先將LTX-Video檢查點和LoRA同步到預期的文件夾(
models/ltxvideo、models/loras),然後打開示例圖表。相信我,一旦路徑匹配,就沒有驚喜。 - 運行長度:雲GPU讓我在沒有出汗VRAM的情況下測試12–16秒的片段,分辨率更高。它本身不能解決漂移,但它加速了迭代,我可以並行渲染三個拍攝並挑選保留者。
如果你在筆記本電腦上工作,這是一個低壓力的方式來測試想法,然後再提交到本地安裝。你的里程數可能會有所不同,但它讓我避免了幾個深夜的編譯循環。
小小的,揮之不去的想法:ComfyUI中的LTXVideo不試圖立即打動你。它只是縮小你必須一次保留在頭腦中的事物數量。在繁忙的日子裡,這就足夠了。





