什么是TranslateGemma?谷歌开源翻译模型详解

嘿,各位!我是Dora。那天,我在编辑一份双语通讯,不断在草稿、屏幕截图和Google翻译标签之间切换。没有什么特别糟糕的地方,只是……太杂乱了。你知道那种感觉。我想要一些安静的东西,能融入我的工作流程,而不是放在一旁。
所以在这周早些时候(2026年1月),我试用了TranslateGemma。起初我没有期望太高,又一个带着闪亮名字的”开源”模型。但经过在笔记本中的几次运行,然后又在一个小型内部工具中试用后,我注意到了一些微妙的东西:心理负担降低了。我不再纠缠于标签页。我不再像以前那样频繁地修改措辞。感觉就像一个能放在我桌子上的翻译,而不是远在房间的另一端。
TranslateGemma是什么
 TranslateGemma是一系列建立在Google的Gemma架构基础上的开源翻译模型。用简单的话说:它是一组专门为翻译任务调优的语言模型,有各种尺寸可以本地运行或在云端扩展。
TranslateGemma是一系列建立在Google的Gemma架构基础上的开源翻译模型。用简单的话说:它是一组专门为翻译任务调优的语言模型,有各种尺寸可以本地运行或在云端扩展。
在实际使用时,有几点特别突出:
- 它是为翻译而专门调优的。你不必费力让通用LLM听命。提示词保持精简。
- 它比简单的句子逐句API能更好地处理上下文。包含习语、产品名称和轻微语调线索的段落能更好地传达,没有那么多”平淡”的部分。
- 它很沉静。输出不浮夸,也不会过度转述。对于工作文档来说,这是一种解脱。
从理论上讲,TranslateGemma介于完全的生成助手和经典的短语翻译器之间。在实践中,它是一个既尊重源文含义又能使目标语言更流畅的翻译工具。当我给它输入一份混合了UI标签和会话语句的简短发布说明时,它保持了标签完整,同时还让文案读起来自然。这种平衡正是让我继续测试的原因。
许可证属于Gemma系列:对许多商业用途允许范围很广,但有负责任AI的限制。如果你想把它嵌入到产品中,请在官方repo或Model Garden条目中阅读许可证。这是无聊的部分,但很重要。
模型尺寸:4B、12B和27B
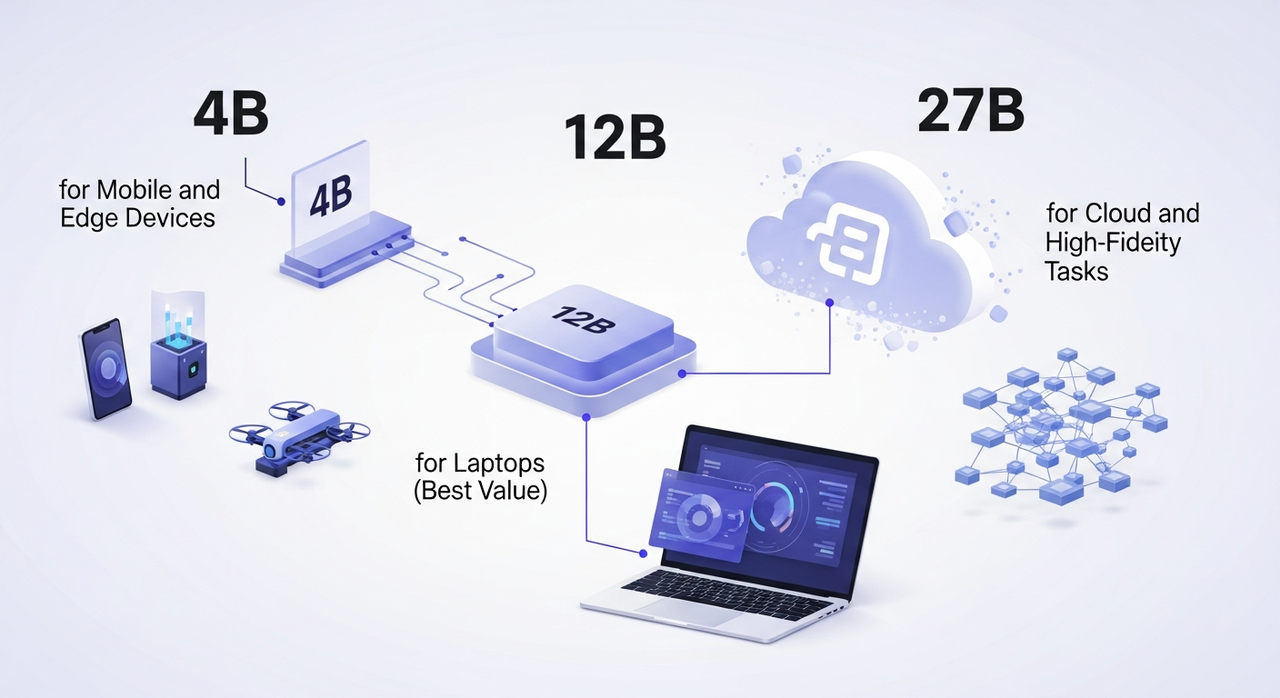 TranslateGemma有三种尺寸。同一系列,不同的权衡。我在两天内对每一种进行了小规模测试,用了几个产品页面、一个电子邮件序列,以及用西班牙语、法语和日语写的研究摘要。
TranslateGemma有三种尺寸。同一系列,不同的权衡。我在两天内对每一种进行了小规模测试,用了几个产品页面、一个电子邮件序列,以及用西班牙语、法语和日语写的研究摘要。
4B用于移动设备和边缘设备
我在最新的Android手机和树莓派5(只是为了看看)上试用了4位量化的4B版本。手机上短句的延迟是可接受的(每行不到一秒),对于直白的文案输出很干净:UI字符串、帮助文本、短标题。任何带有复杂语调或嵌套子句的东西都开始有问题。那是我停止推进的信号。
有效的地方:
- 在设备上翻译应用程序字符串,无需将数据发送到服务器。
- 快速创建第二语言的社交媒体文案草稿。
遇到的限制:
- 较长的段落会变得僵硬。它保留了意思,但失去了灵动感。
- 代码混合文本(英文+第二种语言)有时会过度标准化。
如果你需要边缘计算中的翻译、信息亭、离线应用、隐私敏感的工作流程,4B就是那把能放进口袋的小锤子。对于日常写作,我会把它视为初稿,而不是最终稿。
12B用于笔记本电脑(最佳价值)
这是我一直回到的那个。在我的笔记本电脑上(32GB RAM,消费级GPU),4-8位的12B模型在段落级提示下运行舒适。平均延迟:几句话1-2秒,可能是一个密集段落的5-8秒。这在”不打断思考”的范围内。
质量感觉平衡:比4B的字面意思要少,比那些喜欢转述的更大LLM要少修饰。当我将一个小案例研究从法语翻译成英语时,它保留了结构,反映了句子的重点,而没有把所有内容混为一谈。名称、产品术语和引用都保持原位。
它擅长的地方:
- 需要语调但不需要诗意的营销电子邮件。
- 文档、发布说明和UX文案,其中清晰度胜过华丽。
- 笔记本电脑上的批处理:一次50-200个段落,不用承担云账单。
我仍然会微调的地方:
- 接近诗歌的语句(标语、口号)有时读起来有点保守。快速修改可以解决。
- 高度技术性的论文可能会变得字面。在提示中添加”保持正式的学术语言风格”有帮助。
27B用于云和高保真任务
我在云中的单个A100上运行了27B模型。这是关心细致入微并能为基础设施开销辩护的团队的选择。延迟对于交互式使用来说是可以的,但显然不适合移动设备。
我注意到的:
- 它能保留更长段落中的文体线索。在日英法律文本中,它保持了正式性而没有听起来生硬。
- 它更好地处理了模棱两可的代词。段落间的指代错误更少。
- 对于低资源语言对,它虽然不能创造奇迹,但失败更得体,幻觉术语更少。
说实话,如果你在翻译长篇内容以供发表,或者你需要在数千个片段中保持一致性,27B值得投入。对于小团队,我只在语调保真度非常重要或你需要大规模标准化结果时才会用到它。
TranslateGemma与Google翻译
 我没有打算立即替换Google翻译。它快速、无处不在,对于快速查询,它仍然是从”这是什么意思?“到”明白了”的最快途径。但权衡是不同的。
我没有打算立即替换Google翻译。它快速、无处不在,对于快速查询,它仍然是从”这是什么意思?“到”明白了”的最快途径。但权衡是不同的。
在我的运行中,TranslateGemma感觉更好的地方:
- 上下文窗口:我可以输入整个段落或两个,并保留语调和参考。Google翻译通常抓住意思,但当上下文混乱时,它会将文体变平。
- 可定制性:诸如”保留产品名称、保留缩写”之类的单行指令能可靠地塑造输出。使用Google翻译,你得到的就是你看到的。
- 隐私/控制:本地运行(4B/12B)或在私有云中减少数据暴露。无需切换标签页,如果你不想的话,无需外部调用。
Google翻译仍然胜出的地方:
- 广度和便利性:100多种语言、即时网络访问、OCR、移动相机输入。这是瑞士军刀。
- 大规模快速用于非正式使用:如果我只需要快速翻译一句话,TranslateGemma是多余的,除非它已经内置在我的编辑器中。
- 低摩擦协作:很容易给某人链接一个Google翻译页面并说”这接近吗?”
从成本来看,TranslateGemma将支出从按请求API费用转移到计算。如果你已经有一个不错的GPU或一个适度的云设置,对于持续使用可能更便宜。如果你没有,Google翻译的免费层很难争辩。
质量比我预期的要接近。TranslateGemma以好的方式更少字面意思,谦逊,不浮夸。Google翻译改进了语调处理,但它仍然读起来像一个去了高等学校的词典。如果你为人们写作,这个差距很重要。
一周后我的经验法则是:我仍然用Google翻译来检查我几乎不懂的语言中的一行。我在关心它听起来如何而不仅仅是说什么时使用TranslateGemma。
一旦我决定TranslateGemma是合适的选择,下一个问题就是在哪里实际运行它,而不会让设置成为一个自成一体的项目。
这正是我们构建WaveSpeed的原因。我们的团队用它来启动干净的GPU环境、运行批量翻译工作,然后继续——无需照看驱动程序、队列或临时脚本。
获取TranslateGemma的地方
我从常见的地方获取模型:
- Hugging Face:对于使用Transformers或Text Generation Inference的快速测试最简单。搜索”TranslateGemma”并检查卡片中的许可证和量化变体。
- Google的Model Garden(Vertex AI):托管部署、自动缩放、私有端点。如果你的团队已经在GCP中运营,这是最平稳的路径。
- Kaggle Models:如果你还不想连接基础设施,便于一键笔记本和快速基准测试。
- GitHub + Colab:社区脚手架很快出现,有加载器、提示模板和基本评估脚本。
来自我运行的设置说明:
- 量化有帮助。4-8位使12B模型在消费级GPU上舒适运行,不会破坏输出。我没有错过额外的位。
- 提示词保持简短。“翻译成英文。保留产品名称。保留缩写。” 大多数时候这就足够了。
- 谨慎批处理。按段落或项目符号组分块。逐句处理有效,但你会失去语调的粘合剂。
如果你需要护栏或词汇表控制,添加一个轻量级的前/后处理步骤:
- 预标记产品名称(例如)并要求模型保留它们。
- 使用词汇表匹配器进行后检查,以捕捉术语漂移,如”Sign in”与”Log in”。
我认为会喜欢TranslateGemma的人
- 想要本地、体面质量草稿而不需要切换工具的作家和营销人员。
- 在应用程序中悄悄添加翻译的产品团队,而不是外包给另一个服务。
- 关心长段落和参考保持完整的研究人员。
可能不会喜欢的人
- 任何需要度假时即时相机翻译的人,使用Google翻译。
- 不想管理任何计算的团队。带有SLA的付费API可能更安定。
我没有期望保留它。但整个星期它都在我的工作流程中,因为它对我的要求更少:更少的标签页、更少的提醒、更少的小决定。这通常是我的信号。还有一个小惊喜?我信任它处理段落的语调,不仅仅是词语。你的体验可能不同——但如果你感到太多工具的噪音,这个保持安静。这就是它留在我身边的原因。





