WaveSpeedAI X DataCrunch: 在B200上进行FLUX实时图像推理

WaveSpeedAI X DataCrunch: B200上的FLUX实时图像推理
WaveSpeedAI 与欧洲GPU云服务提供商 DataCrunch 合作,在生成式图像和视频模型部署方面取得了突破。通过在DataCrunch的尖端NVIDIA B200 GPU上优化开源权重 FLUX-dev 模型,我们的协作实现了比行业标准基准快达 6 倍 的图像推理。
在本文中,我们提供了FLUX-dev模型和B200 GPU的技术概述,讨论了使用标准推理堆栈扩展FLUX-dev的挑战,并分享了基准测试结果,展示了WaveSpeedAI专有框架如何显著改进延迟和成本效率。企业ML团队将了解到这个 WaveSpeedAI + DataCrunch 解决方案如何转化为更快的API响应和显著降低的每张图像成本——为实际应用的AI赋能。(WaveSpeedAI由Zeyi Cheng创立,他领导我们加速生成式AI推理的使命。)
本博客同时发布在 DataCrunch博客。
FLUX-Dev:最先进的图像生成模型
FLUX-dev 是一个最先进(SOTA)的开源图像生成模型,能够进行文本转图像和图像转图像生成。其功能包括良好的世界理解和提示词遵循能力(得益于T5文本编码器)、风格多样性、复杂场景语义和构图理解。模型输出质量与Midjourney v6.0、DALL·E 3(HD)和SD3-Ultra等流行的闭源模型相当,甚至可以超越它们。FLUX-dev已迅速成为开源社区中最受欢迎的图像生成模型,为质量、多功能性和提示词对齐设立了新的基准。
FLUX-dev使用流匹配,其模型架构基于多模态和并行扩散变换器块的混合架构。该架构有 12B参数,约33 GB的fp16/bf16。因此,FLUX-dev在这个庞大的参数量和迭代扩散过程下计算量很大。在用户体验至关重要的大规模推理场景中,高效推理是必不可少的。
NVIDIA黑威尔GPU架构:B200
黑威尔架构包括新特性,如第5代张量核心(fp8、fp4)、张量存储(TMEM)和CTA对(2 CTA)。
-
TMEM:张量存储是一个新的片上存储层级,增强了寄存器、共享内存(L1/SMEM)和全局内存的传统层级。在Hopper(如H100)中,片上数据通过寄存器(每线程)和共享内存(每线程块或CTA)管理,通过张量存储加速器(TMA)进行高速传输到共享内存。黑威尔保留了这些,但为每个SM添加了 256 KB的TMEM SRAM 专用于张量核心操作。TMEM不会从根本上改变你编写CUDA内核的方式(逻辑算法相同),但添加了新工具来优化数据流(参见ThunderKittens现已为NVIDIA黑威尔GPU优化)。
-
2CTA(CTA对)和集群协作:黑威尔还引入了 CTA对 作为在同一SM上紧密耦合两个CTA的方式。CTA对本质上是大小为2的集群(两个线程块在一个SM上并发调度,具有特殊的同步能力)。虽然Hopper允许集群中有8到16个CTA通过DSM共享数据,但黑威尔的CTA对使它们能够在通用数据上共同使用张量核心。实际上,黑威尔PTX模型允许两个CTA执行访问彼此TMEM的张量核心指令。
-
第5代张量核心(fp8、fp4):B200中的张量核心明显更大,** 比H100中的张量核心快约2到2.5倍**。高张量核心利用率对于实现新一代硬件的重大加速至关重要(参见NVIDIA Hopper GPU架构基准测试和剖析)。
无稀疏性能数字
| 技术规格 | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| GPU内存 | 80 GB HBM3 | 180GB HBM3E |
| GPU内存带宽 | 3.35 TB/s | 7.7TB/s |
| 每个GPU的NVLink带宽 | 900GB/s | 1,800GB/s |
GEMM和注意力的操作级微基准测试显示以下结果:
- BF16和FP8 cuBLAS、CUTLASS GEMM 内核:比H100上的cuBLAS GEMM快达2倍;
- 注意力:cuDNN速度** 比H100上的FA3快2倍**。
基准测试结果表明B200特别适合大规模AI工作负载,尤其是需要高内存吞吐量和密集计算的生成模型。
标准推理堆栈的挑战
在典型的推理管道(例如PyTorch + Hugging Face Diffusers)上运行FLUX-dev,即使在H100等高端GPU上,也存在几个挑战:
- 高每张图像延迟,由于CPU-GPU开销和缺乏核融合;
- GPU利用率不优 和张量核心空闲;
- 迭代扩散步骤期间的内存和带宽瓶颈。
提供大规模和低成本推理的优化目标是更高的吞吐量和更低的延迟,降低图像生成成本。
WaveSpeedAI专有推理框架
WaveSpeedAI通过专有框架解决这些瓶颈,该框架是专为生成推理设计的。由创始人Zeyi Cheng开发,该框架是我们内部高性能推理引擎,专为FLUX-dev 和**Wan 2.1** 等最先进的扩散变换器模型优化。推理引擎的主要创新包括:
- 端到端GPU执行 消除CPU瓶颈;
- 自定义CUDA内核 和核融合 实现优化执行;
- 高级量化和混合精度(BF16/FP8) 使用黑威尔变换器引擎同时保持最高精度;
- 优化的内存规划和预分配;
- 延迟优先调度机制 优先考虑速度而非批处理深度。
我们的推理引擎遵循HW-SW协设计,充分利用B200的计算和内存容量。它代表了AI模型服务的重大飞跃,使我们能够在生产规模下提供超低延迟和高效率推理。 我们评估这些优化如何影响输出质量,优先考虑无损与松散优化。也就是说,我们不应用可能显著降低模型能力或完全破坏可见输出质量的优化,如文本渲染和场景语义。
基准:WaveSpeedAI在B200 vs H100基线上的表现
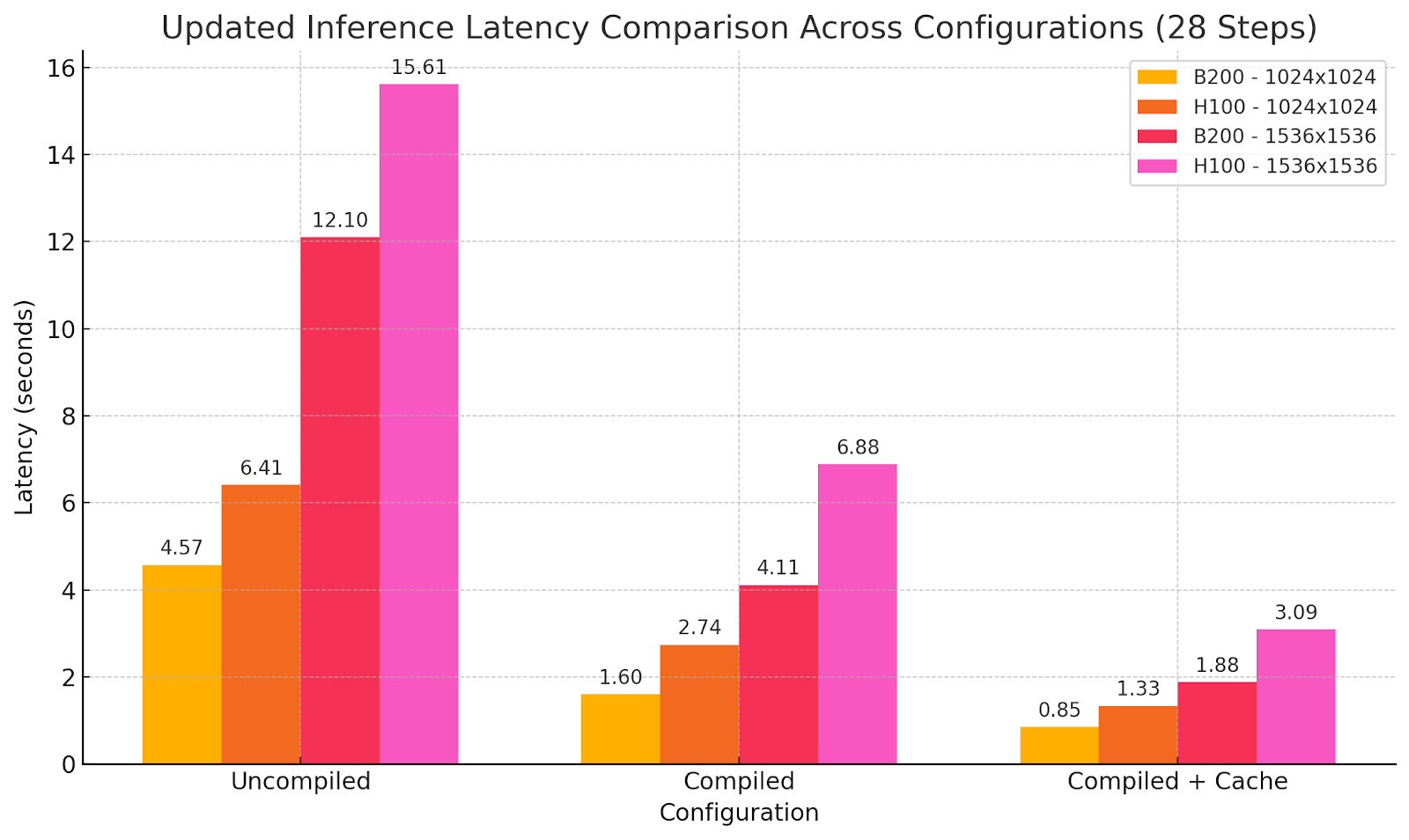
使用不同优化设置的模型输出:

提示词:一位戴着橙色头巾的另类女性的照片,浅棕色长发,清晰镜框眼镜,中隔穿孔,米色背带裤从一肩滑落,下面穿着白色露肩上衣,她坐在她公寓的波西米亚风地毯上,风格为时尚杂志拍摄
意义
这些性能改进转化为:
- AI算法设计(例如DiT激活缓存)和** 系统优化**,使用GPU架构调优内核,以获得更好的硬件利用率;
- 降低推理延迟 带来新的可能性(例如扩散模型中的测试时计算);
- 更低的每张图像成本 由于改进的效率和降低的硬件利用率。
我们实现了 B200等同H100成本性能比但一半的生成延迟。因此,每次生成的成本不会增加,同时现在能够实现新的实时可能性而不牺牲模型能力。有时更多并不代表更好,但不同,这里我们实现了性能的新阶段,为使用SOTA模型的图像生成提供了新的用户体验水平。
这使得响应式创意工具、可扩展内容平台和可持续的成本结构成为现实,使生成式AI能够大规模运行。
结论和下一步
使用B200部署的FLUX-dev展示了当世界级硬件遇见最佳级软件时的可能性。我们在WaveSpeedAI推进推理速度和效率的前沿,WaveSpeedAI由Zeyi Cheng创立——stable-fast、ParaAttention和我们内部推理引擎的创造者。在接下来的版本中,我们将专注于高效视频生成推理以及如何实现接近实时的推理。我们与DataCrunch的合作代表了一个获得B200等尖端GPU和即将推出的NVIDIA GB200 NVL72(从DataCrunch预购NVL72 GB200集群)的机会,同时共同开发关键推理基础设施堆栈。
立即开始:
加入我们,打造世界上最快的生成式推理基础设施。



