TranslateGemma 在线演示 + 快速入门指南

你好,我是Dora。你听说过”TranslateGemma”吗?
这个工具的推荐来自一个小需求:一个客户发来了混合英文和西班牙文的文案,还加上了一些隐藏的占位符,我不想逐行监督翻译模型。你懂的,那种情况:一步错误就会导致占位符崩溃。我看到”TranslateGemma”在各个线程里反复出现,所以我试了一下,不是因为它新,而是因为我想要一个更稳定的方式来获得忠实的翻译而不破坏格式。剧透:它基本上能做到。我在2026年1月期间在几个在线演示和本地设置中测试了它。以下是它真正帮助的地方、它失败的地方,以及我最终如何构建提示词来保持它的稳定性。
在线尝试TranslateGemma(无需设置)
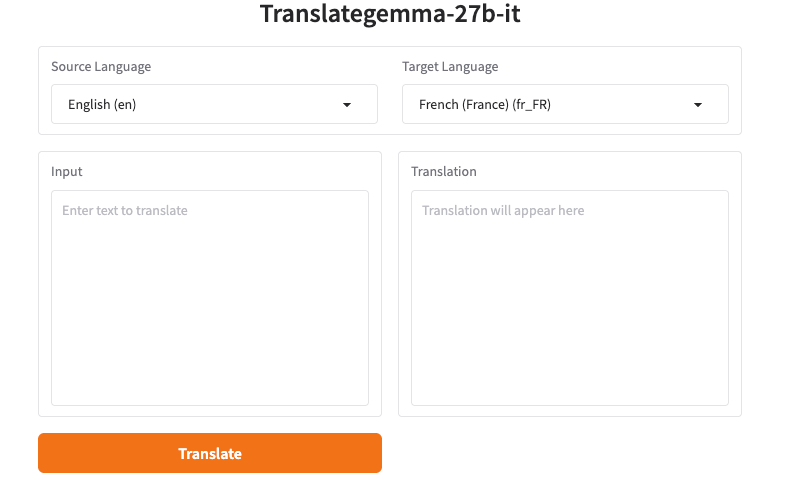
我不喜欢仅仅为了看看东西是否有用而安装它们。所以我从在线TranslateGemma开始。如果你搜索”TranslateGemma online”,你会找到一些托管的演示平台:Hugging Face Spaces、Replicate演示,以及一些轻量级的网页UI,它们封装了针对翻译调整的Gemma检查点。有些需要免费登录,有些不需要。无论如何,你通常可以粘贴文本并选择语言。
让我惊讶的是:即使在共享演示上,速度也很不错。短段落在一两秒内就返回了;更长的页面花费时间会更多,但不足以让我去喝咖啡。我还是盯着屏幕看。老习惯,我想。更大的区别不是速度,而是我如何表述提示词。
简单的”翻译成法文”可以工作,但当文本混合了语调、包含内联代码或使用{{first_name}}这样的变量时,输出就会偏离。修复方法是一套简短、明确的指令。当演示暴露了”系统提示词”字段时,我就使用它。当它没有时,我把指令放在用户消息的顶部。
以下是一个最小化的提示词,它为我持续减少了清理工作:
- 命名源语言和目标语言。
- 告诉模型什么保持不变(占位符、代码块、标签)。
- 围栏文本以便模型知道它从哪里开始和结束。
- 要求纯翻译,不要评论。
我在线使用的例子:
我在线使用的例子:
将以下内容从英文翻译成西班牙文。保持占位符如{{first_name}}、{{price}}和HTML标签不变。保留换行符和标点符号。仅返回翻译后的文本,不返回其他内容。
<
主题:欢迎,{{first_name}}。
你的总计是{{price}}。
点击<a href="/start">这里</a>开始。
>>>这第一次没有节省时间。两次运行之后,它做到了,主要是因为我停止了修复破损的占位符。如果你只是健全性检查TranslateGemma在线,尝试用有和没有该结构的短段落。差异显现得很快。
你必须遵循的聊天模板格式
Gemma风格的聊天模型在你尊重转换标记时响应最佳。一些UI为你添加它们。其他的期望原始文本。如果你直接发送提示词(API、Python或一个简陋的UI),一个清晰、可重复的模板会有帮助。
两种可靠的模式对我有效:
1. 纯文本模板(在大多数网页演示中有效)
你是一个精确的翻译助手。
- 源语言:英文
- 目标语言:西班牙文
- 保持占位符如{{...}}、markdown反引号和HTML标签不变。
- 保留标点符号和换行符。不要添加解释。
要翻译的文本:
<
[粘贴你的文本]
>>>2. Gemma聊天转换风格(在暴露聊天模板的库中有用)
<start_of_turn>user
你是一个精确的翻译助手。
源:英文
目标:西班牙文
规则:保持{{占位符}}、代码块和HTML完整;保留换行符;仅输出翻译。
文本:
<
[粘贴你的文本]
>>>
<end_of_turn>
<start_of_turn>model我没有期望转换标记会这么重要,但它们确实重要。没有它们,我看到了更多”有帮助的”改写(模型试图改进措辞)。有了它们,并用围栏输入,模型更接近任务。
微小的细节带来了很大的差异:
- 明确命名语言。“从英文翻译成西班牙文”的表现比”翻译成西班牙文”更好。
- 在文本之前放置规则。如果你在文本后跟踪规则,它们更容易被忽视。
- 用不同的开始/停止围栏文本(
<<<和>>>或三重反引号)。这减少了开始或结束时的意外修剪。
在本地运行TranslateGemma(Python)

对于较长的工作或敏感的草稿,我喜欢有一个本地备用。叫我偏执,但有时云感觉太……多话了。在我的机器上(32 GB RAM,消费者GPU),一个较小的Gemma基础翻译检查点运行得很舒适:较大的需要更多VRAM或量化。如果你仅有CPU,这很慢但可以用谨慎的设置做到。
以下是Hugging Face Transformers的一个简单模式。我故意保持model_id通用,从Hub中选择一个你信任的Gemma或Gemma衍生翻译模型,理想情况下是一个记录了翻译的模型。下面的模板镜像了在线提示词。
# 使用transformers >= 4.40在2026年1月测试
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
import torch
model_id = "<your-gemma-translation-checkpoint>" # 例如,一个Gemma聊天或翻译调整的模型
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# 加载
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto" if device == "cuda" else None
)
# 提示词模板(纯文本)。如果你的模型需要,可以换成聊天转换。
prompt = (
"你是一个精确的翻译助手。\n"
"源语言:英文\n"
"目标语言:西班牙文\n"
"规则:保持占位符如{{...}}、代码块和HTML标签不变;"
"保留标点符号和换行符;仅输出翻译。\n\n"
"文本:\n<<<\n"
"主题:欢迎,{{first_name}}。\n你的总计是{{price}}。\n"
"<p>点击<a href=\"/start\">这里</a>开始。</p>\n"
">>>\n"
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3,
top_p=0.9,
repetition_penalty=1.02,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(gen[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)测试中的一些注意事项
- 如果你的检查点包含聊天模板,使用库的
apply_chat_template()工具而不是手动字符串。它减少了一半的奇怪行为。 - 对于长输入,设置足够高的
max_new_tokens并保持temperature低(0.2–0.4)。更温暖的采样邀请了”改进”。有些有帮助,有些……不太有帮助。 - 量化有助于较小的GPU。4位(bitsandbytes)对直接翻译表现良好。
- 如果你需要批量翻译,把提示词包装在一个小函数中并流式传输行。我发现按段落分块比巨大的blob更安全,结构丢失的可能性更小。
需要运行翻译工作负载而不管理GPU基础设施或本地设置?
我们构建了WaveSpeed,以便我们的团队可以通过统一的API调用模型并处理批量任务,而不需要启动服务器或与驱动程序搏斗 → 试试吧!
常见错误和修复

这些是我在在线和本地尝试TranslateGemma时遇到的最常见的模式,以及真正为我减少摩擦的东西。
输出不在目标语言中
我主要在没有声明源语言时看到这个。混合语言输入让它感到困惑,足以保留英文短语。坚持下来的修复:
- 命名两种语言:“从英文翻译成西班牙文。“当准确性很重要时,不要依赖检测。
- 将温度降低(0.2–0.4)并使用轻
repetition_penalty(约1.02)。它推动了模型远离创意改写。 - 添加最后的保护行:“如果文本已经是西班牙文,原样返回它。“这在双语片段上减少了过度翻译。
丢失格式或占位符
这是营销电子邮件和产品字符串的大问题。早期的运行破坏了{{variables}}或重新排序了HTML。什么有帮助:
- 明确说明:“保持占位符如
{{...}}和HTML标签不变。不要在代码围栏内翻译。” - 围栏输入并保留换行符。
<<<和>>>模式比依赖空行效果更好。 - 对于易损内容,在提示词中用标记包围占位符:“占位符用双大括号保护,如
{{this}}。不要改变它们。“如果演示一直掉落大括号,我临时将{{替换为[[[,}}替换为]]]在翻译前,然后交换回去。这不优雅,但对于批量工作更安全。
模型改写而不是翻译
有时输出读起来像编辑的改写,而不是翻译。在某些情况下有帮助,在大多数情况下令人烦恼。我的实际修复:
- 在顶部说出角色和约束:“你是一个翻译助手。仅输出忠实的翻译。没有总结,没有解释。”
- 降低温度并避免短输入上的长
max_new_tokens:额外的空间在某些检查点上鼓励了评论。 - 如果模型仍然润色,尝试清晰停止的聊天转换模板。在本地代码中,将停止序列设置为你的转换标记(例如,
<end_of_turn>)。在没有停止支持的托管演示中,添加”仅返回翻译的文本”在大约80%的时间减少了无用信息。
再有一个安静的注意:一些社区检查点标记为翻译实际上是指令调整的通用模型。他们会翻译,但他们更多话。如果你同时遇到了所有三个问题,尝试不同的检查点或一个较小、更严格的。在这个领域,不那么聪明通常意味着更忠实。老实说,那就是我所需要的。
你试过TranslateGemma吗?你保持占位符完整的最佳提示词是什么,或者让它绊倒的最困难文本是什么?分享你的成功、失败或最喜欢的技巧吧!





