Seedance 1.5 Pro:迈向原生音视频生成的重大步伐

随着生成式视频进入真实制作阶段,仅有视觉效果已经不再足够。现代工作流程越来越需要视频和音频能够一起生成——原生生成且同步。
Seedance 1.5 Pro 是字节跳动为原生音视频协同生成而开发的下一代模型,现已登陆WaveSpeedAI。该模型从零开始构建,旨在提供可靠、可控且生产就绪的同步效果,标志着朝向真正统一多模态生成的重要一步。
在即将推出的技术深度文章中,我们将深入探讨Seedance 1.5 Pro——包括其模型能力、实际应用场景、基准测试见解以及其背后的多模态架构。
核心模型能力(特性与实际应用)
1. 高保真同步的原生音视频生成
Seedance 1.5 Pro最根本的突破在于其音视频原生生成范式。在单次推理过程中,该模型同时生成视频帧和相应的音频轨道,保持语音节奏、唇部运动、角色动作和摄像机动态在同一时间参考内对齐。
经过多轮评估,Seedance 1.5 Pro始终优于主流的”视频+文本转语音”拼接管道——特别是在长对话、快速唇部运动和带声音的动作场景中,传统方法往往会出现不同步。
提示词:一个英俊的男人站在雾霭笼罩的山脊顶端。他穿着时尚实用的户外装备——深灰色防风夹克、专业登山裤和背在双肩上的背包。山风轻轻吹动他的头发;他的表情平静而坚定。他身后,涌动的云雾和烟雾在锯齿状的岩石间旋绕,偶尔散开露出远处白雪皑皑的山峰。摄像机缓缓从身后推进,他凝视着下方翻滚云雾的深渊。在寒冷的空气中,他的呼吸凝结成白色的水雾,增添了自然的大气细节。他微微转向摄像机,锐利的眼眸充满不屈的决心,用稳定有力的声音说:“我喜欢挑战。“
2. 多说话人、多语言和方言感知生成
Seedance 1.5 Pro支持跨主要全球语言和地区方言的音视频生成。它保留语言特定的时序、音素和表达,提供精确的唇形同步和自然的情感对齐——即使跨越多个说话人和快速的语言切换也不例外。
提示词:一部高度电影感的日式动画短片,描绘夏日烟火节的宏大场景。重点放在高细节纹理(和服面料、头发、皮肤)、细微的微表情、自然流畅的动作和精致富有情感的叙事上。烟火类似柔和的电影光线,增强情感氛围。(提示词省略…)她用日语柔和地说:“我非常喜欢你”。那个男人轻轻鞠躬,决心要说:“其实,我也喜欢你”。(提示词省略…)
3. 富有表现力的动作与情感表演
Seedance 1.5 Pro超越了保守的低风险动作策略。角色动画展现出更大的幅度、更丰富的节奏变化和更清晰的情感意图——同时保持整体的稳定性。
面部表情从仅仅可识别进展到真正表演化:微表情、情感过渡和肢体语言自然地与对话配合。结果是动作感觉明显更生动。
提示词:一名年轻宇航员穿着破旧的宇航服坐在昏暗的航天器驾驶舱中。头盔面罩被雾气和划痕覆盖,控制面板闪烁着橙黄色的灯光,营造出紧张和孤独的氛围。视频以这个静态的开场画面开始。摄像机随后快速推进到宇航员的脸部,然后切到外部视角,揭示航天器在暴风雨般的宇宙碎片风暴中疾速飞行。科幻惊悚风格。背景音乐:低沉的电子合成器配合迅速膨胀的弦乐以营造悬念。音效:紧急的引擎嗡鸣和呼啸的空间风暴噪音。对白:“在太空的虚空中,一个错误的动作…”接着短暂的沉默,以”求救…系统故障。“结束。
4. 电影感、逼真导向的视觉美学
在视觉上,Seedance 1.5 Pro倾向于自然的实景效果,而非重度风格化或过度渲染的效果。
光线、构图、色彩和谐和景深保持一致,产生的输出接近商业级电影制作,而非合成图像。
提示词:从巨大钢制过山车前排座位的第一人称视角。过山车越过顶峰直冲进一条黑暗隧道。周围景物(夕阳下的游乐园)略微模糊,而风则以口哨声和空气粒子表现。
5. 自动视频时长自适应
通过将视频时长参数设置为**-1**,Seedance 1.5 Pro会自动在4-12秒 范围内(仅整数秒)选择最合适的时长。
该模型评估叙事节奏、动作完整性和音视频闭合性来选择自然的结束点。这减少了因选择固定时长不当而造成的浪费生成和手动调整。
提示词:8位像素艺术风格,一个英雄在夕阳下奔跑跳跃,带有扫描线效果和复古电子游戏音乐。
6. 通过提示词控制的内置效果
Seedance 1.5 Pro在基础模型中包含一系列内置效果。这些可以通过提示词指令触发,而不是完全依赖后期制作合成。
这对于动画密集或风格化内容特别有价值——比如动态漫画——其中效果密度和时序至关重要。
视频生成性能
Seedance 1.5 Pro展现出对涉及摄像机编舞、动作序列和叙事节奏的复杂提示词的强大理解能力。面部特写显得自然,而长镜头和复合摄像机运动保持相对平顺和连贯。
也就是说,在极其高强度的动作场景下,仍有进一步提高稳定性的空间。
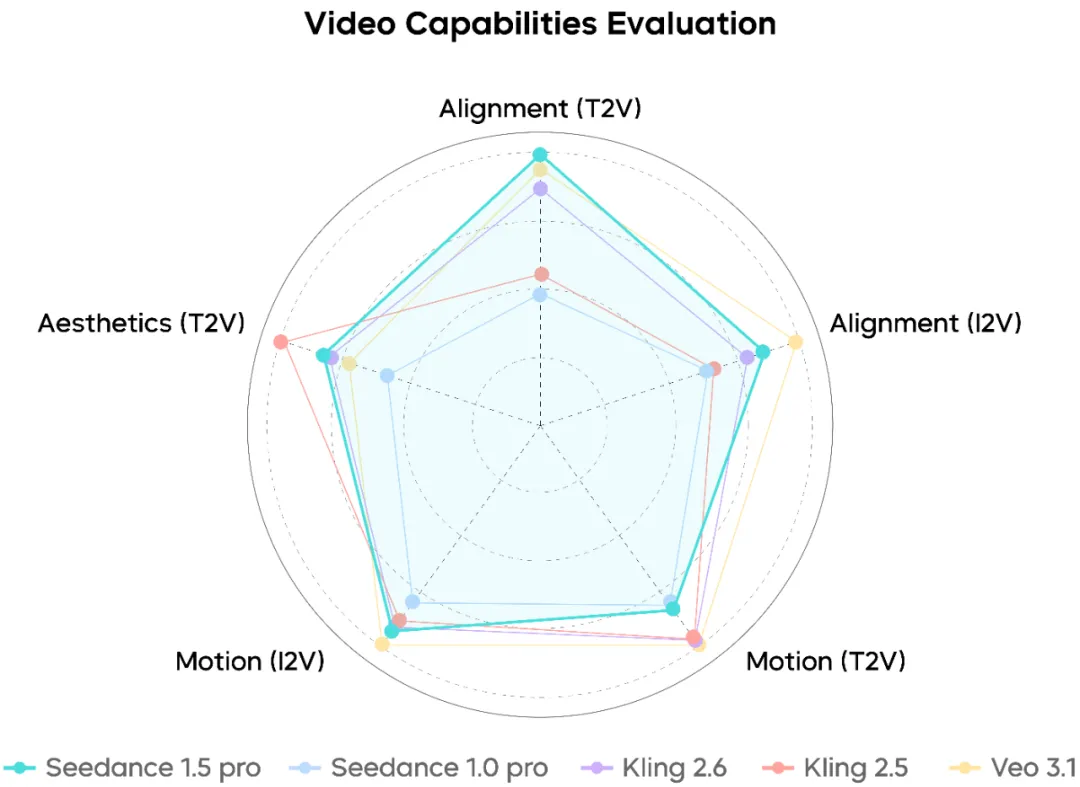
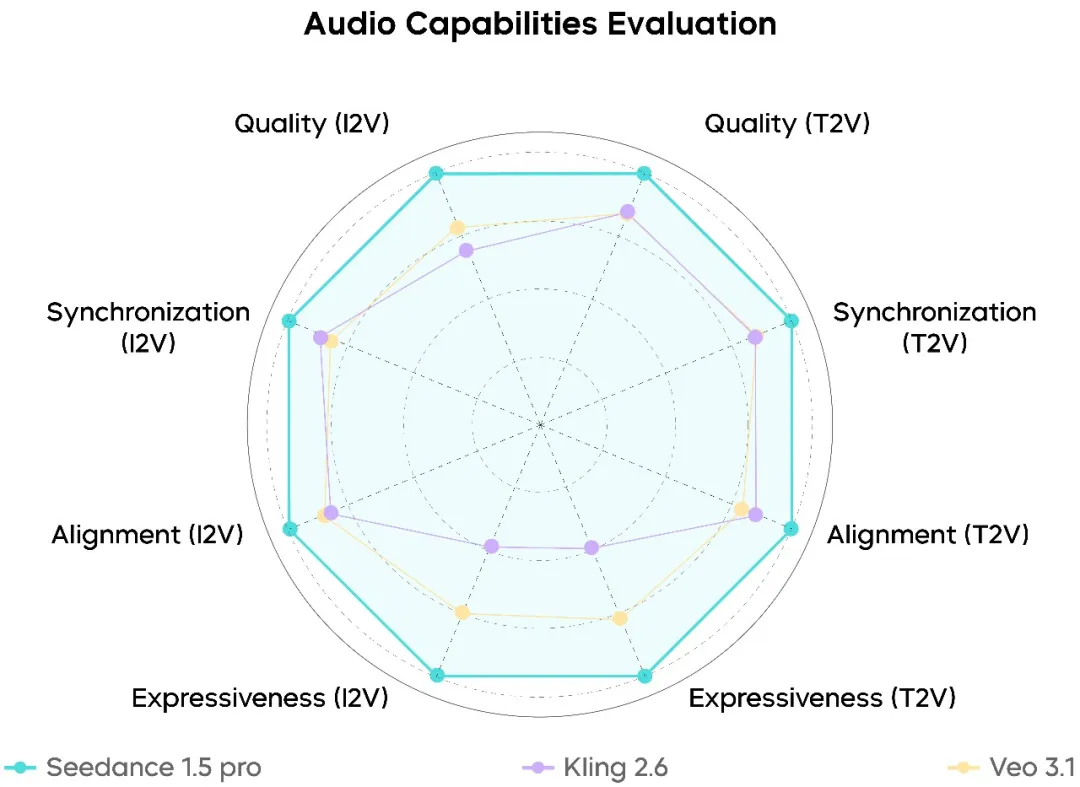
音频生成性能
在音频方面,Seedance 1.5 Pro稳稳位于当前模型的顶级阵列:
- 高度自然的人类语音,机械感明显降低
- 更逼真的空间音频和混响特性
- 显著减少的音视频对齐错误
该模型在中文和方言密集的对话中表现特别强劲,其中发音完整性和清晰度已经满足真实制作的需求。
多模态协同生成架构:视觉与音频如何保持同步
Seedance 1.5 Pro不是独立模块的拼凑——其训练和推理管道经过端到端的重新设计。
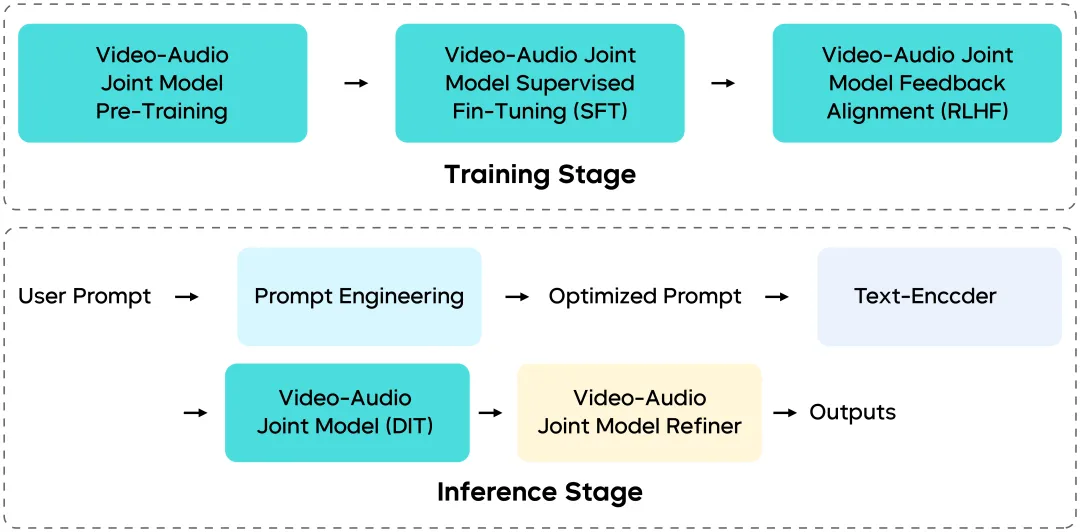
统一多模态架构(基于MMDiT)
建立在增强的MMDiT风格架构 基础上,该模型在同一时间空间内实现视觉和音频流之间的深度交互,确保:
- 时间同步
- 语义一致性
- 协调的情感和节奏
大规模混合模态、多任务训练进一步改进了下游任务的泛化能力。
多阶段数据管道
数据管道设计用于平衡:
- 音视频对齐
- 动作表现力
- 基于课程的训练计划
除了传统的视频-标题数据外,结构化音频描述被系统性地引入,使模型能够内化更丰富的联合音视频语义空间。
细粒度后训练与RLHF
高质量的音视频数据集用于监督微调,同时配合专门为音视频输出设计的RLHF模型,强化:
- 动作质量
- 视觉美学
- 音频保真度
高效推理与部署就绪
通过多阶段蒸馏、量化和并行推理优化:
- 函数评估次数(NFE)显著减少
- 端到端推理实现10倍以上的加速,同时保持质量
这种高效性是Seedance 1.5 Pro能够在WaveSpeedAI上可靠部署的关键原因。
生产就绪的应用场景
Seedance 1.5 Pro特别适合用于:
- 跨境电商和本地化广告
- 短视频叙事和连续剧内容
- 动态漫画和表现力动画
- 品牌故事讲述和电影级营销
- 电影前期可视化和概念验证
最后的思考
Seedance 1.5 Pro的价值不在于证明模型可以生成声音——而在于为音视频协调成为可靠的默认选择奠定基础。
对于追求可扩展内容制作的团队,这种统一的、从零开始构建的方法承诺 更少的后期制作修复、更大的创意自由和一个旨在在真实制作环境中经得起考验的生成式视频工作流。
相关文章

Seedance 2.0现已登陆WaveSpeedAI:字节跳动下一代视频模型,原生音频生成

Seedance 2.0完整指南:多模态视频创建

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:终极视频生成对比

Seedream 5.0-Preview 完整指南:智能图像生成

Vidu Q3 评测:与 Sora 2、Wan 2.6、Seedance 1.5、Veo 3.1 和 Grok Imagine Video 的对比
