WaveSpeedAI上的通义图像:锐利文本渲染和精准编辑

WaveSpeedAI 上的 Qwen-Image:锐利的文本渲染和精确编辑
我们很高兴地宣布,Qwen-Image 这一下一代文本到图像生成模型现已在 WaveSpeedAI 上线。Qwen-Image 是一款尖端的 20B MMDiT 图像基础模型,代表了 AI 驱动的图像生成和编辑领域的重大飞跃,特别是在复杂文本渲染和图像修改过程中保持一致性方面表现出色。

革命性的文本渲染能力
Qwen-Image 在生成图像中的文本渲染方面树立了新标准,解决了 AI 图像生成中最持久的挑战之一。该模型在渲染复杂文本元素方面表现出卓越的能力,包括多行布局、段落级内容以及细粒度细节的非凡精度。
Qwen-Image 之所以脱颖而出,是因为它采用了一种复杂的方法来处理英语等字母语言和中文等表意文字。这种双语优势是通过以下方式实现的:
- 一个综合数据管道,包括大规模收集、过滤、注释、合成和平衡
- 一个循序渐进的训练策略,从非文本到文本渲染演进,从简单到复杂的文本输入逐步推进
- 一种课程学习方法,逐步扩展到段落级描述
其结果是文本渲染精度前所未有,特别是在生成具有挑战性的中文文本方面,相比现有模型有显著提升。

精确的图像编辑与无与伦比的一致性
除了文本渲染,Qwen-Image 在图像编辑任务中也表现卓越,在修改过程中保持语义一致性和视觉真实感。这是通过包含以下内容的增强型多任务训练范式实现的:
- 传统的文本到图像 (T2I) 功能
- 文本到图像 (TI2I) 编辑功能
- 图像到图像 (I2I) 重建技术 该模型的创新双编码机制分别通过 Qwen2.5-VL 处理原始图像以获得语义表示,并通过 VAE 编码器处理以获得重建表示。这种方法使编辑模块能够在保留语义含义和维护视觉保真度之间达到最优平衡。
跨基准的最先进性能
Qwen-Image 在多个公共基准上展示了卓越的性能,使其成为图像生成和编辑领域的领先基础模型:
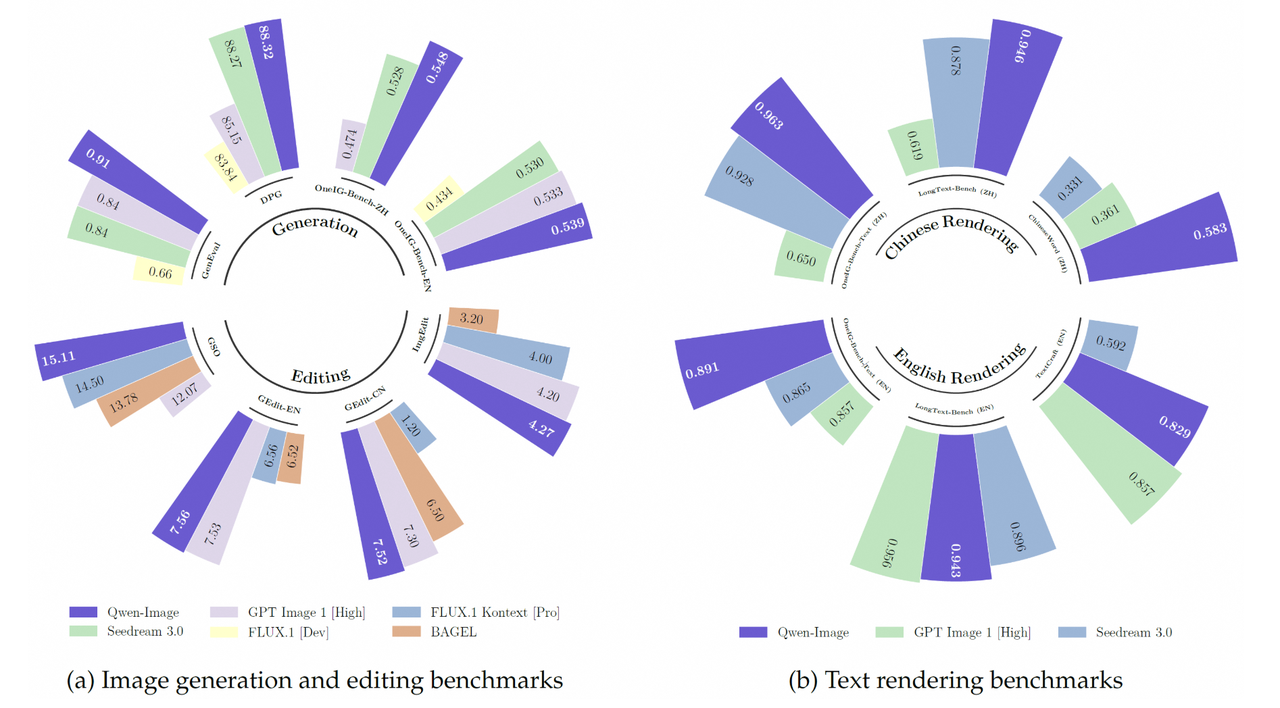
- 通用图像生成:在 GenEval、DPG 和 OneIG-Bench 上排名靠前
- 图像编辑:在 GEdit、ImgEdit 和 GSO 基准上表现突出
- 文本渲染:在 LongText-Bench、ChineseWord 和 TextCraft 上获得优异成绩
该模型的多功能性可跨越各种风格和使用场景,是创建需要精确文本集成和一致编辑功能的插图、海报、幻灯片和其他视觉内容的理想选择。
应用和使用案例
Qwen-Image 的独特功能对以下方面特别有价值:
- 多语言内容创建:生成英文和中文的营销材料、教育内容和产品文档
- 设计自动化:为海报、广告和演示文稿创建具有精确文本放置的布局
- 内容本地化:在保持设计完整性的同时,将视觉内容适配到不同语言
- 品牌一致性:确保在图像编辑工作流程中文本元素保持准确和格式正确
示例
- 讨论海报 —— AI 伦理峰会

- 招聘海报 —— 科技公司招聘

探索 Qwen-Image 的更多可能性
此外,如果你想在训练过程中实现角色一致性和风格一致性,Qwen-Image 也是一个不错的选择。Qwen 开源大模型支持 LORA 技术,可以通过少量数据实现对角色一致性和风格稳定性的轻量级精确调整。
今日开始使用 Qwen-Image
通过 WaveSpeedAI 上的 Qwen-Image,体验下一代图像生成和编辑。无论你是构建下一个创意应用的开发者、寻求自动化视觉内容生成的企业,还是探索 AI 能力前沿的研究人员,Qwen-Image 都能提供你所需的性能和灵活性。
你现在可以直接在 WaveSpeedAI 上探索 Qwen-Image 生成功能。立即尝试!
🔗 推理:https://wavespeed.ai/models/wavespeed-ai/qwen-image/text-to-image
🔗 训练:https://wavespeed.ai/models/wavespeed-ai/qwen-image-lora-trainer



