本地运行 GLM-4.7-Flash:Ollama、Mac 和 Windows 设置指南

你好,我是Dora。几天前,一个小摩擦把我推向了这个方向:我一直在等待远程完成小型起草任务。不是几分钟,只是足够的延迟让我飘向电子邮件并失去思路。上周(2026年1月),我尝试在本地运行GLM-4.7-Flash,看看剃掉那几秒钟是否真的能帮我思考更清楚。
简短版本:确实如此,但不是因为吸引人的原因。GLM-4.7-Flash感觉更像一个稳定的助手而不是头条新闻模型。它的速度足够快,能让我保持专注,而且足够轻,可以在笔记本电脑上运行而不会让它过热。我会分享什么有效,哪里卡住了,以及保持事情枯燥、以好的方式的设置。
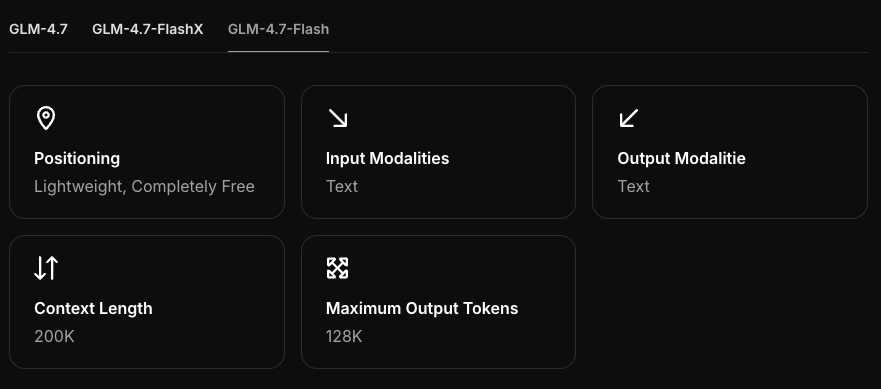
硬件要求
最低GPU / RAM
我在三台机器上运行了GLM-4.7-Flash:
- MacBook Pro M3 Pro(12核CPU / 18核GPU,36 GB RAM)
- Mac mini M2(24GB统一内存)
- 配备RTX 4090的Windows台式机(24GB VRAM)
从这些测试中,实际的最低配置:
- 仅CPU(Mac/Windows/Linux):16 GB系统内存可行,32 GB更舒适。预期首个token较慢。
- Apple Silicon(Metal):16 GB统一内存可用4-bit/5-bit量化和适度上下文(2–4K)。8 GB感觉很紧张。
- NVIDIA:对于4-bit量化,我会尝试的最低配置是8–12 GB VRAM。16 GB+更舒适。
GLM-4.7-Flash感觉像一个中等规模的模型(想象一下少于10–12B参数)。在4-bit时,通常需要~5–6 GB的设备内存加上KV缓存。如果你推送长上下文或许多并行提示,内存会增加。
推荐规格
如果你想要”始终响应”的感觉:
- Apple Silicon:M3或更新版本,配备24–36 GB统一内存:保持上下文4–8K。
- NVIDIA:24 GB VRAM(例如3090/4090)为更高的上下文和并发提供余地。
- 存储:快速SSD:模型加载更快,交换更少。
我注意到当内存压力开始时,模型停止感觉”闪亮”,分页或VRAM溢出会增加细微的卡顿,破坏流畅感。一点额外的余地会有很大帮助。
Ollama设置
我使用Ollama是因为它使本地运行简单且在机器间保持一致。版本上下文在这里很重要。
安装Ollama 0.14.3+
- macOS:brew install ollama(或用brew upgrade ollama更新)。
- Windows:使用Ollama网站的官方安装程序。

- Linux:按照文档中的curl脚本进行操作。
根据此测试(2026年1月),我在0.14.3版本。较新的版本有时会改变默认后端或量化行为,所以我坚持对我稳定的版本,直到我有理由更新。
拉取并运行GLM-4.7-Flash
两条路径对我有效:
-
如果你的Ollama库包括官方GLM-4.7-Flash构建:
- ollama pull glm-4.7-flash
- ollama run glm-4.7-flash
-
如果它没有显示(这在一台机器上发生过):
- 创建一个Modelfile,指向GLM-4.7-Flash的已知GGUF或兼容工件。
- 示例Modelfile(简化):
- FROM ./glm-4.7-flash-q4.gguf
- 仅在你知道需要时添加提示模板:我保持它最小。
- 然后:ollama create glm-4.7-flash-local -f Modelfile
- 运行:ollama run glm-4.7-flash-local
使用中的注意事项:
- 首次加载较慢,因为它在预热缓存。
- 除非我在总结书籍草稿,否则我保持num_ctx保守(4K或8K)。更大的上下文感觉不错,但它们内存饥渴,对日常起草的质量帮助并不总是存在。
- 如果生成感觉犹豫,尝试将温度降低到0.6–0.7并稍微提高top_p:它为我收紧了输出,而不失速度。
参考资源:Ollama文档在平台特定标志和当前后端上很扎实。

Mac性能
M4 / M3 / M2基准
这些不是实验室级别的,只是在写作和轻代码提示、温度0.7、4K上下文、4-bit量化上的稳定运行:
- M4(借用的机器,48 GB):预热后60–85 tok/s。首个token在~350–500 ms。
- M3 Pro(36 GB):35–55 tok/s。首个token在~500–800 ms。
- M2(24 GB):20–30 tok/s。首个token在~900–1200 ms。
将范围作为一种氛围检查。我在M3 Pro上推送了几个8K上下文:速度下降~20–30%但对起草仍然可用。在M2上,长上下文越过了我的”感觉粘稠”线。我在那里保持了2–4K。
内存优化
在macOS上最有帮助的:
- 保持更少的终端标签页运行模型。显而易见,是的,但我经常忘记。
- 正确调整上下文大小。4K对我来说是一个最佳点。
- 尽可能使用4-bit量化。5-bit对我的使用感觉相似的质量,但更慢。
- 关闭抓取GPU时间的应用(视频编辑器,一些带WebGL的浏览器标签页)。
我还注意到使用稳定的系统提示减少了返工。在纸面上不会更快,但更少的重试意味着更好的”感受速度”。一个小提示像:“保持简洁,使用纯英语,没有营销语气。“它符合模型的优势。
Windows + NVIDIA
RTX 3090 / 4090配置
在4090(24 GB)上,GLM-4.7-Flash感觉一致地快:
- 4-bit量化,4–8K上下文:预热后120–220 tok/s。
- 首个token:~250–400 ms。
- 并行提示:2–3个流才能看到卡顿。
一个朋友在3090(24 GB)上运行它,使用相似设置看到~15–25%较低的吞吐量。如果你超过8K上下文或保持许多响应同时进行,你将触及VRAM余地。我通常退回到4–6K并保持批次较小。
CUDA设置
在实践中重要的是:
- 最近的NVIDIA驱动(干净安装在一台卡顿的机器上有帮助)。
- CUDA 12.x和匹配的运行时(如果你在步出Ollama之外(vLLM/SGLang))。对于Ollama本身,你不总是需要完整的工具包,但最新的驱动是不可协商的。
- 电源设置:将你的GPU设置为”偏好最大性能”。它听起来像游戏建议,但它在长时间运行中停止了时钟节流。
如果你遇到加载错误或硬回退到CPU,我会仔细检查:
- 驱动版本与CUDA运行时的对齐。
- 反病毒是否在扫描你的模型目录(它发生过:很傻:它很慢)。
参考资源:NVIDIA的驱动–CUDA兼容性表在你花费一小时调试之前值得快速检查。
vLLM / SGLang
当我想要更多对批处理和服务器风格端点的控制时,我尝试了GLM-4.7-Flash与vLLM和SGLang。
vLLM
- 安装:最近的Python、CUDA兼容的PyTorch,然后pip install vllm。
- 运行:
python -m vllm.entrypoints.openai.api_server --model <your_glm_flash_id> --dtype auto --max-model-len 4096 - 我为什么使用它:稳定的OpenAI兼容API,多用户或多标签页工作流的稳定吞吐量。
SGLang
- 安装:pip install sglang
- 运行:
python -m sglang.launch_server --model <your_glm_flash_id> --context-length 4096 - 我为什么使用它:低延迟流感觉灵敏,它与小路由任务配合得很好。
两者都需要适当的模型路径或HF repo ID。如果GLM-4.7-Flash不在你的默认索引中,你需要将它们指向本地GGUF或兼容的权重格式。同样:匹配CUDA和驱动版本,否则你会追逐模糊的内核错误。我保持dtype自动,仅当我知道我有VRAM备用时才强制fp16。
对于我的单用户写作会话,Ollama保持更简单。vLLM/SGLang在我测试需要OpenAI风格端点的工具时有意义。
故障排除
模型加载失败
我看到的:
- 加载时”内存不足”。修复:切换到较小的量化(例如4-bit),降低num_ctx,或关闭GPU繁重的应用。
- Windows上”没有兼容的后端”。修复:更新GPU驱动:确保你没有安装CPU专用PyTorch(如果你使用vLLM/SGLang):驱动升级后重新启动。
- Ollama中未找到模型。修复:创建Modelfile并ollama create:或从精确repo标签拉取(如果存在)。
如果模型静默回退到CPU,迹象是风扇噪声(或缺乏它)加上速度慢得多的token/sec。我已经学会在假设模型变”差”之前检查设备利用率。
缓慢推理修复
小改变比我预期的更重要:
- 正确调整上下文大小。将上下文减半通常比调整采样快得多。
- 预热缓存。一个快速的短运行改进下一个。
- 减少并行流。并发看起来高效,直到KV缓存绊倒你。
- 对于NVIDIA:设置高性能电源模式,关闭覆盖应用,并停止后台编码器。
- 在macOS上:保持充电器插入:一些笔记本在电池上时会降速。
还有一个:我停止追逐最大token/sec。对我来说,更好的指标是”首个可用想法”。当我保持提示专注和上下文合理时,GLM-4.7-Flash快速给了我那个。
 如果你喜欢GLM-4.7-Flash的速度,但不想照看驱动、CUDA版本或后端怪癖,尝试WaveSpeed - 我们自己的平台,专注于稳定、快速的推理,无需低级调整。你得到可预测的延迟,无需担心模型文件、量化格式或GPU兼容性。
如果你喜欢GLM-4.7-Flash的速度,但不想照看驱动、CUDA版本或后端怪癖,尝试WaveSpeed - 我们自己的平台,专注于稳定、快速的推理,无需低级调整。你得到可预测的延迟,无需担心模型文件、量化格式或GPU兼容性。





