5分钟创建AI主播:数字人类构建初学者指南

一个在WaveSpeedAI上构建数字人的分步教程。
前言
并非每个人生来就是天生的演讲者,也不是每个人都乐于在众人面前讲话。
站起来讲话可能令人紧张——但如果一个”虚拟的你”能代替你进行演讲、直播或录制你的宣传读白呢?你还会害怕吗?
在WaveSpeedAI上,这已经不再只是一个想法了!你可以从零开始构建自己的数字人,让它以逼真的声音和表情说出你的话语。
它不会怯场,从不感到疲倦,你可以随时随地完善和重复使用它。它是你工作和生活中的可靠伙伴。
在本教程中,我们将指导你从零到一,一步步构建一个简单的数字人。我们这里使用的模型仅仅是开始——请随意探索更多功能和风格,打造真正独一无二的数字人。
在WaveSpeedAI上,我们的模型生成清晰、稳定的视觉效果,边缘自然,随时可用于展示。它们适用于正式的谈话头部、随意对话和产品解说等多种场景。
图像生成
一个帅气、可爱且自然逼真的数字人能为观众提供更好的体验。它还会吸引更多关注和流量到你的频道。
你也可以直接从个人照片创建一个。如果你已经准备好了合适的照片,可以跳过这一部分。
我将以bytedance/seedream-v4 为例,帮助你创建一个独特的虚拟化身。
在WaveSpeedAI上,搜索bytedance/seedream-v4——这是一个文本到图像的模型。现在,让我们输入一个提示词来创建你自己的数字人:
Half-length portrait of a young female digital human (22–28),
natural makeup, white shirt and light gray blazer,
looking at camera, soft studio light,
plain light-gray background, ultra realistic, 4k, 85mm, f/2.8
你可以自定义性别、着装和背景 等元素以满足你的需求,创建各种风格和氛围,使你的数字人感觉更具吸引力和品牌化。
语音生成
现在你的数字人已经准备好了,下一步是起草一个清晰的旁白脚本,这样他们就可以自然地”讲话”。
在WaveSpeedAI中,进入分类 > 文本到音频 来探索各种模型。我们提供自然旁白、语音克隆甚至歌曲创作的模型。
在本部分中,我们将使用minimax/speech-02-hd 作为示例。请随意尝试其他模型来探索不同的声音风格和效果。
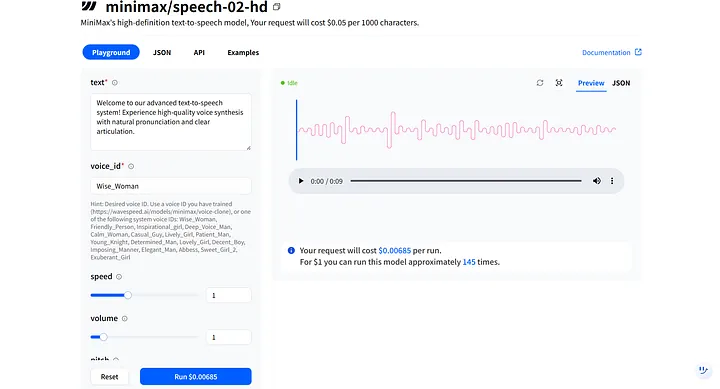
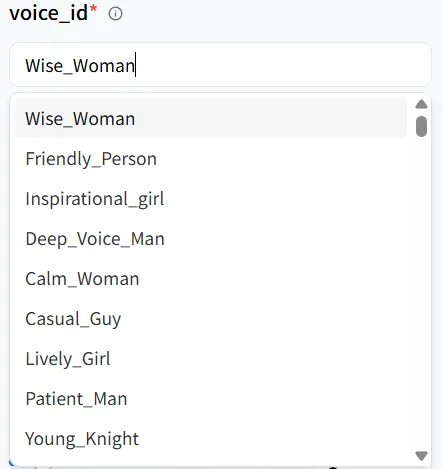
在模型Playground 中,你会看到文本 和voice_id 等关键参数。这些参数协同工作来塑造你的数字人的音调和音色,你可以调整它们以适应不同的场景。例如,我创建的数字人是女性,所以我可以选择第一个语音选项Wise_Woman。
关键参数
速度
speed 控制你的数字人的讲话速度。选择适合场景的节奏——例如,产品介绍时稍微放慢,随意对话时加快。1 表示正常速度。

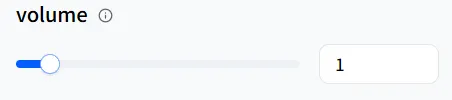
音量
volume 设置音量大小。如果你的数字人在讲述睡前故事,你可以降低speed 来放慢速度,并降低volume 以获得更柔和的音效。1 是默认音量。
音调
pitch 调整语音的音调。调整此参数使声音听起来更明亮尖锐或更深沉饱满。0 是默认音调。

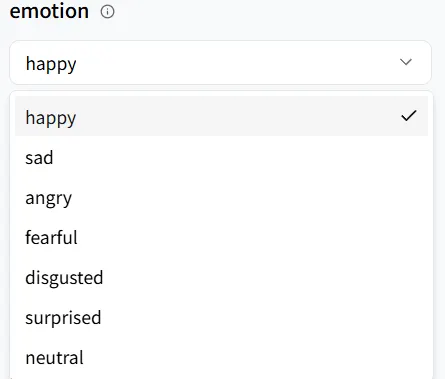
情感
emotion 控制你的数字人的讲话风格。选择与场景相符的语调——这里我们选择happy。
英文规范化
english_normalization 选项启用后,使英文中的数字和符号在语音中听起来自然。不启用的话,系统可能会逐个读出数字(例如”one two three”而不是”one hundred and twenty-three”来表示”123”)。

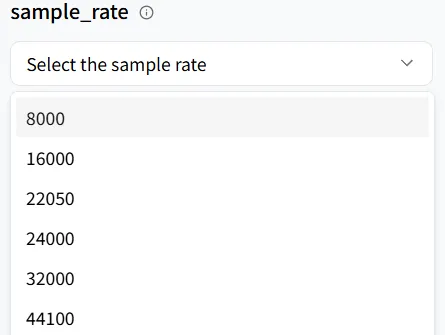
采样率
sample_rate 决定音频质量(分辨率)。如果你在制作ASMR风格的内容,请选择更高的采样率以获得更丰富的细节。对于本教程示例,这不是关键的——保留默认值就完全可以了。
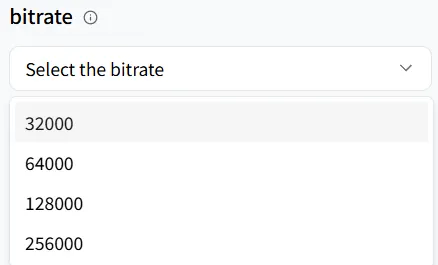
比特率
bitrate 决定音频文件的质量和大小。它表示每秒处理的比特数。较低的比特率会生成较小的文件但可能丧失细节;较高的比特率会产生较大的文件但声音更清晰。
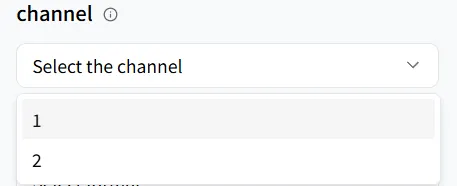
通道
channel 参数决定生成的音频通道数。
- channel = 1(单声道): 所有声音混合为单个通道——适合电话语音、通话录音或不需要空间宽度的以对话为中心的内容。
- channel = 2(立体声): 声音分为左右通道,营造宽度感和空间感,提供更沉浸式、分层的体验——非常适合需要更高听觉质量的音乐、电影、游戏和视频旁白。
格式
format 允许你选择输出音频文件类型(我们这里跳过具体细节)。
语言提升
language_boost 提高模型对你所选语言的理解。对于本教程,选择English。
生成音频
接下来,粘贴你的脚本并点击Run 来生成音频!
Welcome to WaveSpeedAI’s Digital Human Tutorial. We’ll spark fresh ideas in AIGC and show you practical steps. Let’s unleash your creativity together!
下载音频文件——这是让你的数字人稍后能够讲话的关键部分!
让数字人讲话
最后,激动人心的时刻到了:我们要让你的数字人真正讲话!
在WaveSpeedAI上,搜索wavespeed-ai/infinitetalk——我们专门为数字人旁白设计的高质量模型。
在模型的Playground 中,你会看到两个必需的输入:audio 和image。
- audio: 上传你刚刚下载的旁白文件。
- image: 上传你之前生成的数字人图像。
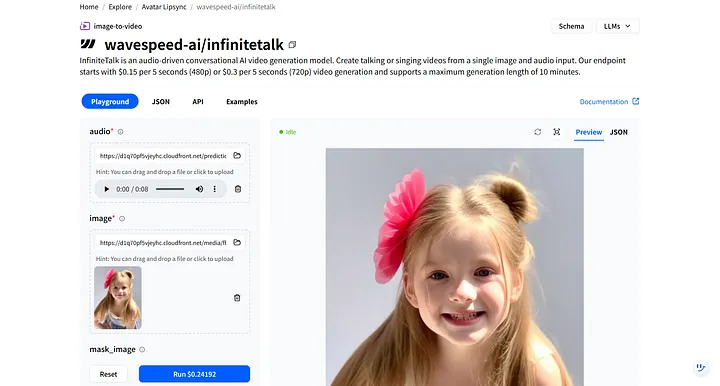
点击Run 后,数字人会对音频做出反应,并自动同步唇部动作和面部表情。
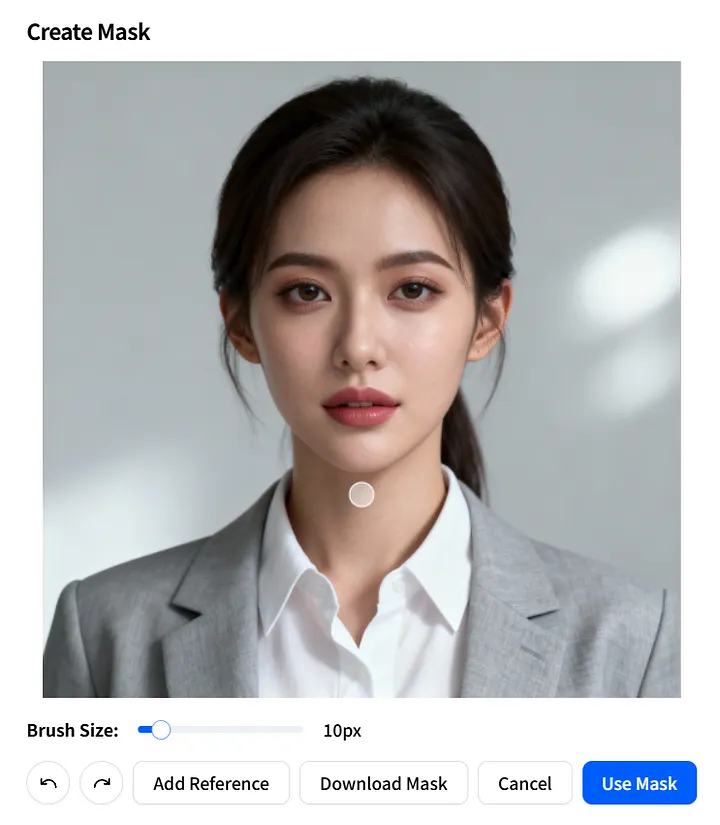
遮罩图像参数
接下来,让我们看看mask_image 参数。它允许你精确指定图像的哪些部分应该被动画化。
在Create Mask 页面上,准确定义可移动区域:调整Brush Size,在你想要动画化的区域上绘制,然后点击Use Mask 应用。
你也可以点击Download Mask 将mask_image 保存为模板,以便在未来的项目中快速重复使用。
其他自定义
如果你有其他需求——例如指定姿势、手势或凝视方向——在prompt 中添加更多具体指示。
为了便于复制,设置一个固定的seed 值。这确保随机性保持一致,这样你以后就可以重现相同的结果。
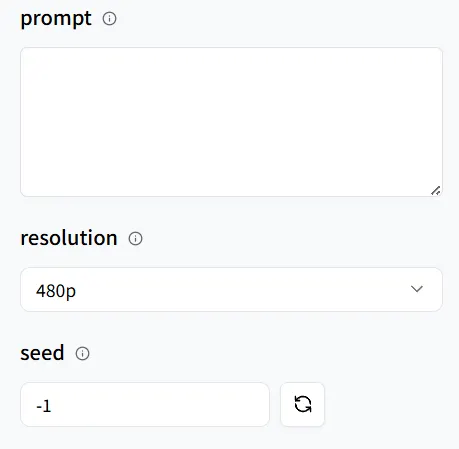
最后,点击Run,让我们期待最终结果!
恭喜!你已经拥有了自己的数字人!
准备好进阶到多人场景 了吗?WaveSpeedAI也为此提供了专门的模型。让我们一起来探索它们!
多人讲话生成
在WaveSpeedAI上,搜索wavespeed-ai/infinitetalk/multi。其步骤基本上与单人模型相同。
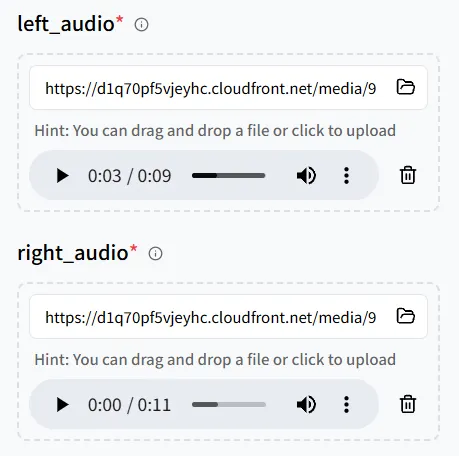
这次,添加两个音频文件,然后上传一个** 包含两个数字人的图像**,这样两个角色都可以说出他们的台词。
仔细注意音频和图像上位置的配对:
- left_audio → 图像中** 左边**的人
- right_audio → 图像中** 右边**的人
仔细检查映射;否则,声音可能会被链接到错误的角色。
讲话模式
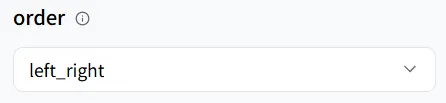
在wavespeed-ai/infinitetalk/multi 模型中,它支持三种讲话模式:
- left_right(从左到右)
- right_left(从右到左)
- meanwhile(同时讲话)
同样,使用此模型,你可以通过prompt 添加想要的细节,并设置seed 以便轻松重现。
就这样,你就拥有了一个两人旁白秀!
其他模型
在WaveSpeedAI上,我们还为你提供了许多其他模型:
- wavespeed-ai/multitalk: 非常适合”歌曲风格的数字人”,可实现多部分人声和更富表现力的表演。
- wavespeed-ai/infinitetalk/video-to-video: 为现有视频添加旁白或叙述,使视觉和音频保持自然同步。
- wavespeed-ai/song-generation: 从零开始创建音乐,为你的内容设计自定义配乐和氛围。
这些模型也提供独特的体验,在其他平台上很难复制。大胆尝试——试试它们并分享你的作品!你可以在Inspiration 部分发布以与其他创作者联系和互动!

最后的想法
我们的世界在快速变化,人工智能日益影响着我们的日常生活。坚持老办法只会增加成本、减缓进度并冒着失去新机遇的风险。
现在是采用新技术并享受其便利和效率的完美时机。WaveSpeedAI为你的内容创作提供长期支持,拥有可靠的技术和不断增长的生态系统。
无论你的创意将你引向何处,WaveSpeedAI都将作为你可靠的基础和值得信赖的伙伴与你同在。
相关文章

Seedance 2.0现已登陆WaveSpeedAI:字节跳动下一代视频模型,原生音频生成

Seedance 2.0完整指南:多模态视频创建

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完整对比

Seedream 5.0-Preview 完整指南:智能图像生成

Vidu Q3 评测:与 Sora 2、Wan 2.6、Seedance 1.5、Veo 3.1 和 Grok Imagine Video 的对比
