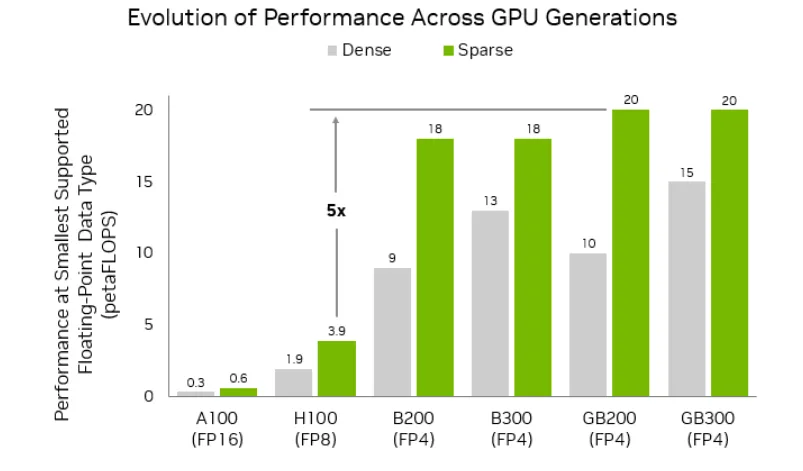
LTX-2 中的 NVFP4 vs NVFP8:速度、质量和显存对比(RTX 指南)

我没有主动寻找精度设置。我遇到它们是因为 LTX-2 在批量渲染期间不断让我的 16 GB GPU 接近极限。预览冻结了,风扇呼呼作响,那个小下拉菜单NVFP4 或 NVFP8,突然感觉不再是一个利基选项,而是度过一天的方式。
在过去一周(2026年1月),我在几个稳定、平凡的场景中测试了 LTX-2 的 NVFP4 和 NVFP8:1080p 和 2K 的短片概念预览,以及一些 4K 静帧和平移用于客户的情绪板。没什么特别的,你知道。只是堆积起来的那种工作。以下是我注意到的、什么有效,以及每个设置在哪里悄悄帮助或阻碍了我。
NVFP4 与 NVFP8 解释(一句话总结)
 NVFP4 以一点质量和稳定性换取更低的 VRAM 和更快的吞吐量:NVFP8 保留细节效果更好,但对你的 GPU 要求更高。
NVFP4 以一点质量和稳定性换取更低的 VRAM 和更快的吞吐量:NVFP8 保留细节效果更好,但对你的 GPU 要求更高。
速度 / VRAM / 质量权衡矩阵
我会让这个简单,因为现实就是简单的。
- 速度: NVFP4 在我的运行中通常快 15–30%,取决于分辨率和批处理大小:NVFP8 慢一点但保持一致。
- VRAM: NVFP4 为我削减了大约 25–40% 的内存占用:NVFP8 使用更多但减少了伪影。
- 质量: NVFP8 保持精细边缘(头发、标牌、微纹理),减少运动中的闪烁:NVFP4 软化细节,有时增加小的时间抖动。
这就是它的样子。其余的是情境性的。
来自 RTX 4090(24 GB)和 4080(16 GB)上可重复测试的一些现场记录:
- 1080p,短片(4–6 秒):NVFP4 保持预览流畅,让我提高批处理大小:NVFP8 保持面部和文本帧间清晰。
- 2K,中等片段(8–12 秒):NVFP4 适合初始预览:NVFP8 避免了平移时纹理上的微小”爬行”。
- 4K,静帧:NVFP8 值得。我宁愿等一会儿也不愿花时间修饰边缘。
这些都不是戏剧性的。但我感受到了。使用 NVFP4 的 VRAM 压力减少意味着中断减少。使用 NVFP8 的输出更清洁意味着重做减少。
何时使用 NVFP4(批量生产 / 低 VRAM)
 当我更关心流程而不是完成度时,我会使用 NVFP4。
当我更关心流程而不是完成度时,我会使用 NVFP4。
NVFP4 帮助的地方
- 批量概念预览:我可以在 16 GB 上并行运行 3–6 个提示在 1080p,无需管理内存。这意味着我保持在流程中并更快地比较选项。
- 粗剪和分镜:对于带有占位符镜头的快速板,略微的柔和度无关紧要。它实际上隐藏了奇怪之处。
- 长时间会话:VRAM 余量意味着更少的重启。减少摩擦会在一天内累加。
我实际注意到的权衡
- 微细节损失:精细图案(网格、发型线、小反射)略微减弱。没有破损,只是不那么清晰。
- 时间稳定性:在缓慢的平移上,NVFP4 有时在高频区域引入微小闪烁。它在时间线上并不总是明显,但在暂停时出现。
对我感觉安全的实用范围
- 1080p,短片:NVFP4 加上适度的批处理大小(2–4)远低于 16 GB。
- 2K,短片:NVFP4 在 16 GB 上保持平稳,如果我不过度推送上下文长度的话。
为什么使用它:NVFP4 是一个好的”思考精度”。它削减了探索想法的成本。如果输出只是供你或团队检查,NVFP4 使 LTX-2 感觉轻便。
何时使用 NVFP8(质量 / 精细细节)
当我关闭循环时,我切换到 NVFP8。
NVFP8 值得的地方
- 甲板的最终帧:如果一个帧可能被传播、客户分享、作品集或社交,NVFP8 减少了清理工作。
- 面部和手:边缘保持得更好,睫毛毛线周围的小抖动消散了。
- 文本和标牌:不完美,但更常清晰。更少的重新渲染只是为了修复抖动的字母。
需要接受的成本
- 更重的 VRAM:在 16 GB 上,我在 2K 时保持批处理大小低,避免在同一图中堆积额外的节点。
- 慢一点:我不介意等待,因为我只在喜欢镜头后才运行 NVFP8。
如果你触及 4K,即使是静帧,NVFP8 是更安全的默认值。我曾经在 4K 尝试用 NVFP4 节省时间:我花了那时间来清理边缘。
按分辨率的配置表(1080p / 2K / 4K)
这些不是规则。它们是让我不断动的方式,无需不断调整。硬件重要。这是在:
- RTX 4080 16 GB(台式机)
- RTX 4090 24 GB(工作室机器)
定义:
- 这里的”批量” = 一个图运行中的并行提示或片段。
- “上下文/长度” = 你的序列运行多长或你打包了多少条件。
1080p(1920×1080)
- 16 GB:NVFP4,批量 3–4,短片(≤6 秒)感觉安全:NVFP8,批量 2,稳定。
- 24 GB:NVFP4,批量 6–8 容易:NVFP8,批量 3–4 有额外空间。
2K(2048×1152 或 2048×1536)
- 16 GB:NVFP4,批量 2–3:NVFP8,批量 1–2:保持上下文适中。
- 24 GB:NVFP4,批量 4:NVFP8,批量 2–3,观察节点堆积。
4K(3840×2160)
- 16 GB:NVFP4,仅单个,短上下文:NVFP8,单个,有耐心。
- 24 GB:NVFP4,在精益图中批量 2:NVFP8,单个或批量 2(如果其他节点很轻)。
你在推动它的迹象:
- 刮擦或中途改变种子时 VRAM 激增。
- 输出开始良好但在后面的帧中退化。
- ComfyUI 预览在帧之间暂停比平时更长。
如果你遇到任何这些,首先降低批处理大小。然后缩短序列。精度通常是我拉的最后一个杠杆。
如何在 ComfyUI 中切换精度
这取决于你使用的节点包,但以下是我看到的(2026 年 1 月):
- 模型加载器或 LTX-2 节点:通常有一个精度或数据类型下拉菜单。我看到过 NVFP4、NVFP8 和 float16 之类的选项。我在那里切换它,保持图的其余部分不变。
- 如果没有下拉菜单:检查 节点的文档 或仓库 readme。一些构建从全局配置或环境标志继承设置。
- 混合图:如果你将 LTX-2 与上采样器或后处理节点链接,注意数据类型不匹配。大多数节点自动转换,但有时你支付隐藏的内存税。
什么对我有效
- 保存同一图的两个版本:一个命名为
_fp4用于探索,一个_fp8用于最终版。这样我就不是在寻找切换。 - 在 NVFP4 预览上保持预览启用。如果预览卡顿,通常表示我的批处理或上下文对于 fp4 来说太高了。
如果你想要具体细节,官方文档或节点仓库经常说明精度标志如何被传递。当感觉不对劲时,我交叉检查这些。
在 WaveSpeed 上测试两者
我不只依靠我的眼睛,所以我依靠了一个简单的循环:相同的提示、相同的种子、两次运行,一个在 NVFP4,一个在 NVFP8,用小的 WaveSpeed 工作流和旁边的秒表计时。我更关心差异的形状而不是确切的数字。
我测量的内容(大致)
- 吞吐量:NVFP4 在我的 16 GB 机器上始终快 15–30%:在 24 GB 机器上接近 20%。
- VRAM 余量:NVFP4 在 1080p 时为我留下 2–4 GB 额外,这让我保持一个轻的降噪节点活跃。NVFP8 吃掉了那个边界。
- 视觉效果:在砖块和树叶上的缓慢平移上,NVFP8 保持纹理。NVFP4 略微模糊并增加了微小闪烁。在运动密集的片段上,我几乎没有注意到。
WaveSpeed(或任何你使用的基准钻机)帮助我保持诚实。我运行三对并扔掉第一个作为预热。然后我问一个无聊的问题:这个设置为我节省了步骤吗?如果答案是肯定的,它就坚持。
如果你想比较 NVFP4 和 NVFP8 而无需处理本地 VRAM 限制,WaveSpeed 让你在更大的云 GPU 上运行相同的 LTX-2 提示和种子。在锁定设置之前,这是一个检查速度、内存余量和视觉权衡的直接方式。
 谁可能更喜欢哪一个:
谁可能更喜欢哪一个:
- 如果你在分镜、原型化功能或大量生成社交优先概念,NVFP4 与截止日期配合良好。
- 如果你提交的帧会被暂停、缩放或打印就绪,NVFP8 发挥其作用。
我不会声称一个更好。它们是不同的齿轮。现在我命名了每一个何时帮助时,我切换得少得多。
我在笔记本角落保留的小笔记:当渲染感觉”嘈杂”难以判断时,通常不是精度问题,而是设置蔓延问题。我首先削减变量,然后切换 NVFP4/NVFP8。
这是我留下的地方。昨天,NVFP8 为我节省了一个小时,我本来会花在清理 4K 静帧的边缘上。今天早上,NVFP4 让我一次预览四种外观,而不需要风扇听起来像起飞。我不需要超过那个。





