下载LTX-2模型:Hugging Face文件、大小和文件夹结构

Let me provide the translation directly:
我第一次寻找**LTX-2下载**时,这没有什么宏伟的计划。我只是想通过ComfyUI运行一个小批次,却一直被同样两个问题绊倒:下载速度缓慢,在92%处停滞,最后我终于获得文件后又收到神秘的”找不到模型”消息。没什么戏剧性的。只是那种反复出现的问题,促使你停下来整理工作流程。
我在2026年1月初花了几个晚上测试不同的源、格式(NVFP4 vs NVFP8)和文件夹布局,使用24GB GPU机器。没什么华丽的,只是足够多的运行来看清什么是坚实的,什么是脆弱的。以下是减少混乱的方法,附带你可以快速浏览和借鉴的笔记。
官方LTX-2下载源(Hugging Face模型卡)
 我不追求镜像。如果一个模型对我的工作流很重要,我希望过程乏味且可靠。对于LTX-2,这意味着从官方**Hugging Face模型卡**开始。
我不追求镜像。如果一个模型对我的工作流很重要,我希望过程乏味且可靠。对于LTX-2,这意味着从官方**Hugging Face模型卡**开始。
点击下载前我会寻找什么:
- 发布者: 这是与LTX-2相关的已验证组织或作者吗?我检查组织徽章,以及命名空间中的其他存储库是否看起来活跃且一致。
- 许可证和条款: 某些LTX-2变体受门禁保护或有使用限制。如果接受条款需要令牌,我宁愿一次性完成,也不愿稍后调试身份验证错误。
- 工件列表: 我浏览主模型、任何编码器以及蒸馏或量化变体。清晰的文件名优于巧妙的文件名。
- 说明: 如果卡片链接到ComfyUI或特定节点的文档,我首先遵循这些。关于预期文件夹的一行文字可以节省半小时的猜测时间。
实用提示: 使用带有凭据设置的Hugging Face CLI。受门禁的存储库不会在没有令牌的原始**git-lfs**上拉取,这是导致部分文件和没有错误直到你尝试加载它们的最快方式。
pip install huggingface_hub git-lfs
huggingface-cli login # 粘贴你的令牌我知道,显而易见。但我看到无声403变成下游”找不到模型”的次数是……非零的。
文件列表和大小(主模型/编码器/蒸馏版本)
我不记住文件大小。我只需要一个粗略的范围来规划磁盘并决定先抓取哪个变体。以下是我在最近LTX-2版本中实际看到的内容。你的存储库可能不同,始终信任模型卡而不是我的笔记。
你会看到的典型工件:
- 主模型检查点(通常是
.safetensors或特定于运行时的格式):约2.5–6.0 GB。如果包含额外的头部或多精度则更大;如果量化则更小。 - 文本/图像编码器(CLIP或类似):约400 MB–1.5 GB。某些构建捆绑这个;其他则作为单独的文件提供。
- VAE或潜在适配器(如果适用):约100–500 MB。
- 蒸馏变体:约1–3 GB。更快更轻,有时输出稍柔和。适合原型设计。
- 量化变体(NVFP8/NVFP4):大小各异,但预计比完整精度少30–60%的磁盘。
我注意的命名模式:
ltx-2.safetensors(主模型)ltx-2-encoder.safetensors或open_clip-vit-…(编码器)ltx-2-vae.safetensors(如果分离)ltx-2-distilled-…(更小、更快)ltx-2-nvfp8/ltx-2-nvfp4(特定于格式)
如果磁盘紧张,我先抓取蒸馏版本,验证我的管道,然后拉取完整模型。这不仅仅是关于速度:减少第一次运行的认知负荷可以帮助我测试提示和节点,而不会立即与VRAM搏斗。
ComfyUI LTX-2的文件夹结构(精确路径)
这是我第一天绊倒的地方:我的文件没问题,但ComfyUI不知道在哪里查看。不同的自定义节点期望略微不同的位置,但下面的默认设置对我来说一直很安全。
在标准**ComfyUI安装**上(没有自定义节点覆盖):
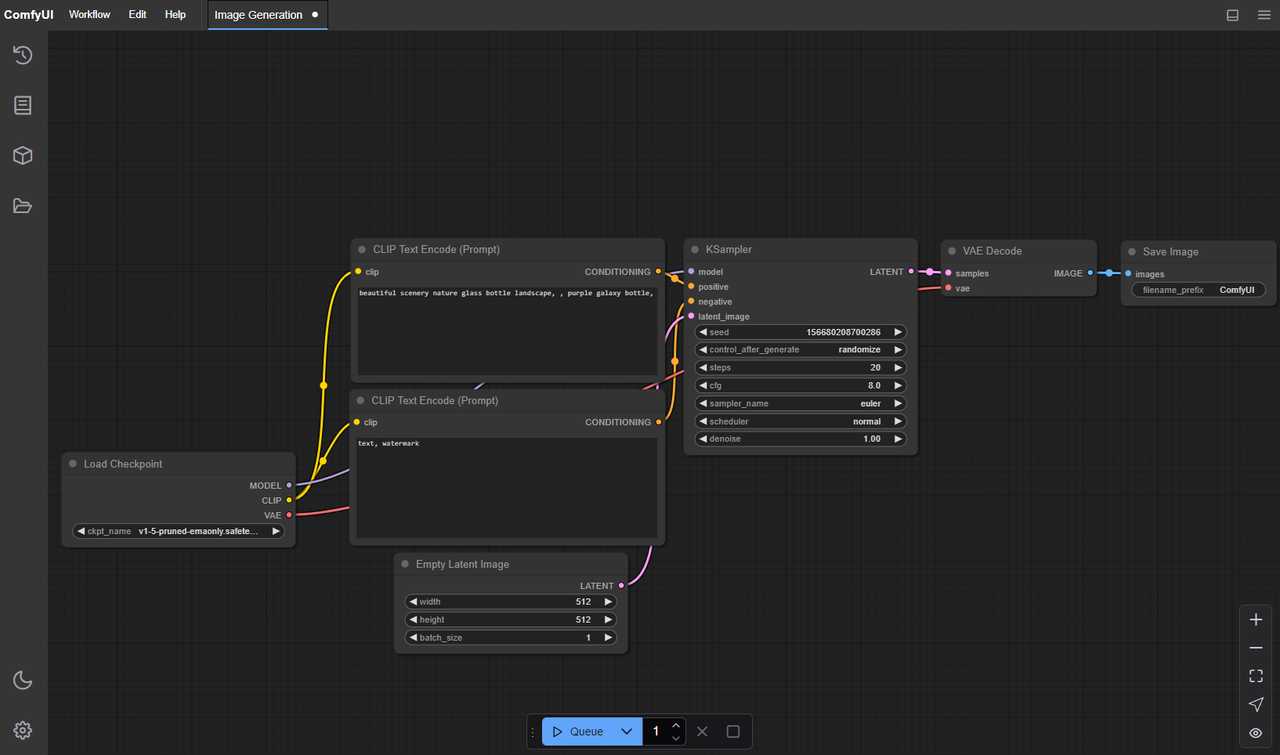
- 主模型检查点:
ComfyUI/models/checkpoints/LTX-2.safetensors - 文本/图像编码器(CLIP或类似):
ComfyUI/models/clip/LTX-2-encoder.safetensors- 某些构建使用open_clip命名:也将这些放在
models/clip/中。
- 某些构建使用open_clip命名:也将这些放在
- VAE(如果分离):
ComfyUI/models/vae/LTX-2-vae.safetensors - LoRA/补丁(如果你使用它们):
ComfyUI/models/loras/
如果你使用依赖TensorRT或引擎文件的节点:
ComfyUI/models/trt/ltx-2/*.engineComfyUI/models/unet/ltx-2/*.engine
两个乏味但有用的习惯:
- 将文件名与节点期望的内容完全匹配。我保持名称短并移除空格。
- 移动文件后,使用ComfyUI的模型刷新或重启。热重加载有时有效:完整重启更一致。
如果你使用外部磁盘或共享模型文件夹,设置ComfyUI的额外模型路径,这样它就不会悄悄扫描错误的驱动器。Linux上的大小写敏感性咬了我不止一次。
NVFP4 vs NVFP8权重:下载哪个
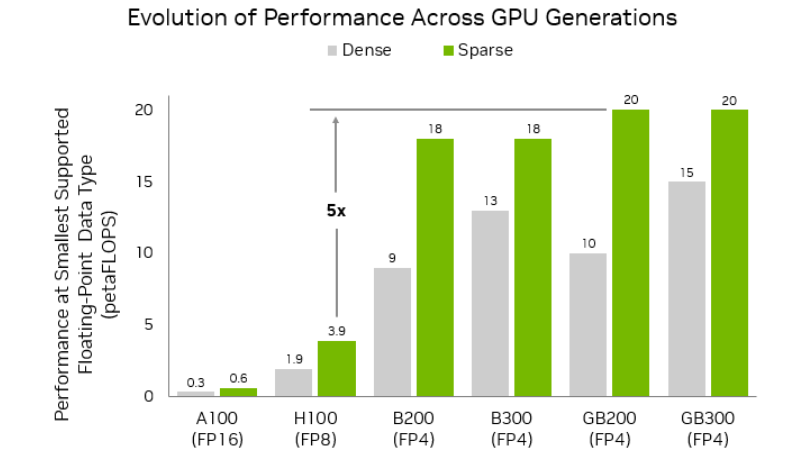 我很好奇**NVFP4**是否值得额外压缩。简短回答:可能,如果你在VRAM上捉襟见肘并且你的节点实际支持它。
我很好奇**NVFP4**是否值得额外压缩。简短回答:可能,如果你在VRAM上捉襟见肘并且你的节点实际支持它。
以下是它在我的机器上的实际感受(Hopper级GPU,2026年1月构建):
NVFP8
- 平衡:很好的中间地带。显著低于完整精度的内存,输出漂移最小。
- 兼容性:更好。目前更多节点和运行时接受FP8而不是FP4。
- 我何时选择它:日常运行,我想要稳定性而不是最小的占用空间。
NVFP4
- 占用空间:更小。它让我在FP8不会的地方提高了分辨率或上下文。
- 漂移:在边缘情况下略微更多的工件或柔和度。不总是这样,但足够让我注意到。
- 兼容性:更挑剔。如果某些加载器没有检测到正确的内核,会退回或失败。
- 我何时选择它:快速草稿、网格搜索,或者当工作流被节点的FP4路径严格支持时。
还有一件事:这些格式通常假设你在可以正确加速它们的NVIDIA堆栈上。如果你的节点没有明确说”支持NVFP4/NVFP8”,我默认使用完整精度或蒸馏.safetensors构建。追求边际收益不值得神秘的中途崩溃。
LTX-2下载加速和校验和验证技巧
我像对待任何其他大文件任务一样对待大模型拉取:加快它,然后验证。
实际帮助的加速:
- Hugging Face传输加速:在使用
huggingface_hub之前设置环境变量HF_HUB_ENABLE_HF_TRANSFER=1。这在可用的地方启用了他们加速的后端。
aria2c用于并行块:
aria2c -x 16 -s 16 -k 1M -c-c标志在我的连接在97%处打嗝时干净地恢复部分下载。
git-lfs调整的拉取
git lfs install然后git clone。- 遵循**Git LFS安装指南**,如果是一个巨大的存储库,我有时使用稀疏检出来避免拉取我不会使用的示例。
我实际做的验证(不再跳过)
比较模型卡(或存储库的.sha256文件)中的SHA256与你的本地文件。
- macOS/Linux:
shasum -a 256 - Windows:
certutil -hashfile SHA256
文件大小理智检查
- 如果预期大小是4.2 GB,我看到3.3 GB,我停在那里。部分文件有时”加载”,然后稍后抛出垃圾错误。
小习惯可以节省时间:我在模型文件旁保留一个小README.txt,包含源URL、日期和哈希值。三个月后当我重新访问时,我不必逆向工程我过去的选择。
“找不到模型”的修复
这个错误吃掉了一小时我不会再得到的时间。以下是实际帮助我的修复:
- 错误的文件夹: ComfyUI期望检查点在
models/checkpoints/、编码器在models/clip/、VAE在models/vae/。把它们放在任何其他地方,扫描器可能会忽略它们。 - 文件名不匹配: 某些节点寻找特定的基名。如果节点说
ltx-2.safetensors,不要叫它LTX-2 (final).safetensors。我积极地重命名。 - 大小写敏感性:
ltx-2.safetensors≠LTX-2.safetensors在Linux上。问我怎么知道的。 - 缓存索引: 移动文件后刷新模型或重启ComfyUI。索引不总是实时的。
- 缺少依赖: 如果节点期望外部编码器而你只下载了主模型,你会得到一个模糊的错误。拉取模型卡上列出的编码器并重试。
- 受门禁的模型没有令牌: 如果你在没有登录的情况下克隆(或你的令牌过期),本地文件可能是存根。用
huggingface-cli login重新登录并重新拉取。 - 自定义节点和替代路径: 某些节点覆盖默认文件夹。检查他们的README了解预期路径或环境变量。有疑问时,从你的共享模型目录放一个符号链接到预期的本地路径。
当我卡住时,我暂时将节点指向已知良好的小模型,只是为了确认加载器有效。如果小的加载,bug就在LTX-2文件中,而不是我的环境中。
使用WaveSpeed跳过LTX-2下载
我在旅行笔记本上尝试了不同的路线:完全跳过本地下载,通过**WaveSpeed**运行LTX-2。它远程流式传输或托管权重,所以你可以连接ComfyUI类似的图形,而无需在磁盘上停放10+ GB。
 对我有效的:
对我有效的:
- 入职很轻松。我将图形指向他们的LTX-2端点,没有触及本地文件夹。
- 冷启动速度更慢(第一次运行启动一个会话),但对于小批次的温启动感觉正常。
- 它让我的笔记本电扇不再呼啸。仅凭这一点就在旅途中很有用。
我注意到的权衡:
- 延迟: 有一个小开销,更多的短运行明显。对于长时间渲染,我停止注意。
- 控制: 你放弃了一些版本固定。他们保持模型修补,这很好,直到你想重现一个较旧的结果。
- 成本/配额: 这不是”像下载一样免费”。如果你的预算紧张或需要繁重的批量工作,本地仍然胜出。
- 隐私: 我保持敏感提示和资产本地。对于公开或测试工作,我很好。
谁可能喜欢这个: 在性能不足的机器上测试LTX-2的人,或任何想在提交到完整本地设置之前先勾勒工作流的人。如果你VRAM充足并关心精确的可重现性,本地安装仍然感觉更好。
我没有预料到喜欢它,但对于快速实验,跳过下载是一个小的解脱。





