DeepSeek V4 1M token上下文:如何提示整个代码库

嘿,朋友们。我是 Dora。第一次把完整项目放入 DeepSeek V4 的 100 万 token 窗口时,我没有感到强大。我感到谨慎。一百万 token 听起来像无底的咖啡,但任何试过在咖啡因加持下思考数小时的人都知道边界会变得模糊。我想看看这个新的上下文大小是否真的会改变我的工作方式,或者只是鼓励我粘贴更多内容。
我花了几天时间(2026 年 1 月 27-30 日)使用 DeepSeek V4 100 万 token 来处理三项我经常遇到的任务:
- 阅读中等规模的 单体仓库,无需本地设置,
- 追踪跨越过多相互通信的服务的 bug,
- 以及请求不会破坏测试的重构建议。
我学到的是:你可以放入很多内容,但模型仍然需要你指点方向。收益不是来自塞入更多文件:它们来自我如何组织提示,以及我如何让模型在其中移动。
100 万 Token 的实际含义
 我不关心数字本身。我关心的是它能用清晰的头脑容纳什么。
我不关心数字本身。我关心的是它能用清晰的头脑容纳什么。
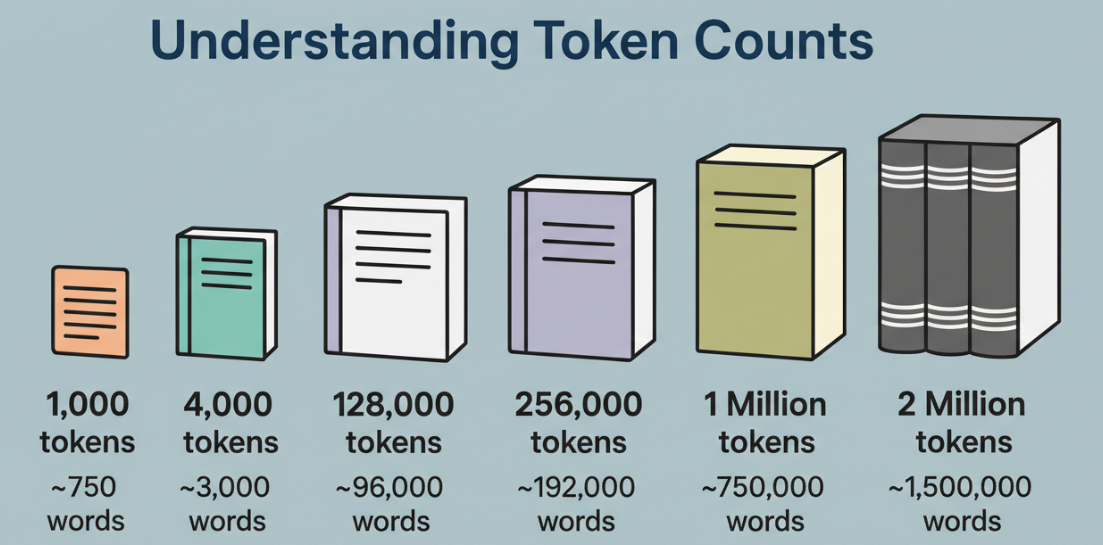
Token 不是单词。它是一个块,有时是完整的单词,有时是单词的一部分,有时是标点符号。对于英文文本,我通常将 1 个 token 视为约 0.75 个单词以便粗略规划。对于代码,token 来得很快:大括号、点、方法名称,全部被切割。100 万个 token 是很大的范围,但并非无限关注。
本周对我来说改变的是:我停止了激进的修剪。对于 128K 的上下文,我会激进地总结,只保留热路径。对于 1M,我可以保留热路径加上”冷”文件,这些文件往往会在稍后让我感到惊讶(配置、迁移、构建脚本、工作流粘合代码)。也就是说,如果我一次性转储所有内容,答案会变得模糊。当我分阶段向模型提供信息,并提供清晰的路标时,输出感觉更加扎实。
代码行数等价物
我工作时使用的粗略数学:
- 许多仓库混合代码和文档。在代码密集的文件夹中,我看到密集语言中每个字符约 2-3 个 token,但实用的快捷方式是:简单行大约每行 4 个 token,现实世界的行(带有缩进、名称和注释)为 8-12 个 token。
- 按照这个速度,100 万个 token 可以容纳约 80K-150K 行代码,具体取决于样式和语言。带有注释和 lint 友好命名的 TypeScript 服务处于较高端。缩小化的包会爆炸计数,不值得包括。
实际上,我的”安全容纳”是约 60K 行有意义的源代码 + 针对性文档和测试。我可以更高,但延迟会上升,答案会变软。你的里程数会因分词器规则和语言混合而异。
与当前模型(128K)的比较
从 128K 跳到 1M 的感觉不像是更大的背包,而是像带上了一个行李车。你可以携带更多,但你不会冲刺。
我注意到的:
- 延迟:全上下文提示花费的时间明显更长。当我分块会话(分阶段)时,延迟感觉可以管理。
- 回忆:对于 128K,模型经常”忘记”早期的文件,除非我重复关键部分。对于 1M,它没有忘记,但有时它会泛化而不是引用具体内容。当我要求它尽可能引用文件路径和行范围时,我得到了更好的结果。
- 精度:上下文越大,你在提示中就越需要索引行为。否则,你会得到能干的摘要,但会回避你实际关心的混乱边界情况。
如果你希望 100 万个 token 意味着”不再需要提示工程”,我不会指望这一点。它改变了你进行的指导类型。
大型代码库的提示结构
 我停止将提示视为一条消息,开始将其视为阅读计划。模型现在可以阅读很多内容,但它仍然受益于目录和轨迹。
我停止将提示视为一条消息,开始将其视为阅读计划。模型现在可以阅读很多内容,但它仍然受益于目录和轨迹。
对我来说最有效的看起来像这样:简短的系统框架、简洁的项目索引、声明的探索顺序,然后是一个具体的任务。然后我以轮次方式继续对话,而不是一个超级提示。
文件排序
当我告诉模型首先打开什么、其次打开什么、第三打开什么时,我得到了更可靠的答案。顶部的单个列表帮助它建立了精神堆栈:
- 从入口点开始(CLI、HTTP 处理程序、作业)。它锚定流。
- 然后是组合层(DI 容器、main.ts、app.py),依赖关系在这里连接。
- 接下来,核心领域模块及其接口。
- 只有那么:助手、工具和跨领域部分(日志、遥测、配置)。
- 测试最后,除非我在调试特定故障,在这种情况下,从失败的规范开始来设置预期。
我还为看起来很重要但实际上不是的文件夹包含了”不读”注释:生成的代码、编译的资产、快照。它节省了 token 并保持了模型对活跃代码的关注。
一个小技巧:我要求模型维护一个”活跃文件”的滚动列表(路径和简短摘要),并在我们移动时更新它。当它漂移时,我可以指向该列表说,“暂时留在这个集合内。“这让答案保持具体。
依赖关系映射
最有用的一次是早期要求提供依赖关系映射,不是作为图表而是作为简单的边表:模块 A 导入 B,B 使用 C,C 访问环境变量,等等。我保持它是文本的和简洁的。
这在实践中所做的:
- 它暴露了流浪依赖(那种在文件夹之间泄露关注点的)。
- 它给了我一个”压力点”的快捷列表,以在任何重构之前审查。
- 它帮助模型在我要求更改时引用正确的位置。
我还让模型陈述假设,它从命名、注释或测试推断出什么。当假设有误时,我更正一次,后来的步骤保持更清洁。
一个警告:在单个镜头中在大型仓库上要求完整的依赖关系映射导致超时和模糊图表。我通过按层范围(例如,仅数据访问,仅 HTTP 处理程序)取得了更好的结果,然后自己合并注释。这花了额外的 10 分钟,但以准确性的形式支付回报。
需要时的分块策略
 即使有 1M token 的窗口,我仍然分块。不是因为它无法容纳,而是因为我的思考在阶段中更好,当我缩小模型的视野时,模型回答更精确。
即使有 1M token 的窗口,我仍然分块。不是因为它无法容纳,而是因为我的思考在阶段中更好,当我缩小模型的视野时,模型回答更精确。
本周坚持的几个模式:
- 分阶段简报:我从小上下文、项目索引、任务、已知约束开始,然后要求提出阅读和验证计划。只有在那之后我才按照我们同意的顺序提供代码。
- 限制活跃集合:对于重构,我只保留 5-12 个文件在进行中,并要求使用显式路径进行更改。如果编辑涉及共享工具,我在下一轮中添加该文件。模型保持更紧凑。
- 在边缘总结:在移动到新文件夹之前,我要求简短总结我们学到的内容和任何不确定性。这些总结在转弯中充当面包屑,无需重新粘贴每个文件。
- 有目的地使用检索:对于不能舒适容纳的仓库,我使用嵌入来按查询调用文件(“payment id 规范化”、“retry backoff”)。我保持检索集合较小,每轮通常在 40K token 以下,所以回复不会模糊。
- 向前验证,不向后:与其问”你使用了我粘贴的所有内容吗?“我问”指出你的建议依赖的具体函数和行。“这强制了具体的引用,使错误明显。
我遇到的摩擦:
- 当你每轮发送全上下文消息时,延迟会增加。分阶段将我在相同任务上的平均响应时间从 70-90 秒减少到 20-40 秒。
- 成本很重要。大型提示加起来。我通过删除重述明显内容的注释、删除编译的工件和跳过供应商包来节省 token。
- 位置效应是真实的。巨大提示的最开始或最后的内容往往更”可用”。我通过在每轮末尾重复微小的关键约束来对抗这一点。
谁从 1M 窗口中受益?

- 如果你住在 单体仓库、处理审计或进行跨领域重构,它为你节省了更少的设置步骤和更少的本地索引开销。这是一个更平静的起点。
- 如果你的工作主要是小服务中专注的 bug 修复,额外的容量不会有太大帮助。更小的上下文加上紧密的检索管道会感觉更快。
关于信任的说明:我要求模型为有风险的更改(迁移、身份验证)引用确切的代码行。当它犹豫或改述时,我将其视为缩小范围或重新粘贴特定文件的标志。那个小习惯预防了几次近距离未命中。
如果你想要模型限制或分词器行为的正式描述,请查看提供者的文档。当我需要具体情况时,我返回官方模型卡和上下文窗口注释。它让我对我要求模型做什么保持诚实。
这不是魔法。这只是一个更大的桌子。有用,如果你安排好椅子。
我一直在想起周二的一个小事情:我要求修复,模型建议更改一个乍一看看起来是对的函数。它不是。bug 存在于两层下的一个助手中。一百万个 token 没有改变那一点。我的笔记确实改变了。





