WaveSpeedAI X DataCrunch: Реальная генерация изображений FLUX на B200

WaveSpeedAI X DataCrunch: Вывод изображений FLUX в реальном времени на B200
WaveSpeedAI объединилась с европейским поставщиком облачных GPU DataCrunch для достижения прорыва в развёртывании моделей генеративного изображения и видео. Благодаря оптимизации модели с открытым исходным кодом FLUX-dev на графических процессорах B200 компании NVIDIA от DataCrunch, наше сотрудничество обеспечивает вывод изображений на 6× быстрее по сравнению с отраслевыми стандартными показателями.
В этой статье мы предоставляем технический обзор модели FLUX-dev и графического процессора B200, обсуждаем сложности масштабирования FLUX-dev с использованием стандартных стеков вывода и делимся результатами тестирования, демонстрирующими, как собственная платформа WaveSpeedAI значительно улучшает задержку и эффективность затрат. Команды корпоративного машинного обучения узнают, как это решение WaveSpeedAI + DataCrunch преобразуется в более быстрые API-ответы и значительно сниженную стоимость на одно изображение — расширяя возможности приложений реального мира AI. (WaveSpeedAI была основана Зейи Чэнгом, который руководит нашей миссией по ускорению вывода генеративного AI.)
Эта статья перепубликована на блоге DataCrunch.
FLUX-Dev: современная модель генерации изображений
FLUX-dev — это передовая (SOTA) модель генерации изображений с открытым исходным кодом, способная выполнять генерацию текст-в-изображение и изображение-в-изображение. Её возможности включают хорошее понимание мира и соответствие запросам (благодаря кодировщику текста T5), разнообразие стилей, сложную семантику сцен и понимание композиции. Качество выходных данных модели сопоставимо или может превышать популярные закрытые модели, такие как Midjourney v6.0, DALL·E 3 (HD) и SD3-Ultra. FLUX-dev быстро стала самой популярной моделью генерации изображений в сообществе с открытым исходным кодом, установив новый стандарт качества, универсальности и соответствия запросам.
FLUX-dev использует согласование потока, а её архитектура основана на гибридной архитектуре из мультимодальных и параллельных блоков трансформера диффузии. Архитектура имеет 12 млрд параметров, примерно 33 ГБ fp16/bf16. Следовательно, FLUX-dev требует интенсивных вычислений из-за большого количества параметров и итеративного процесса диффузии. Эффективный вывод существен для крупномасштабных сценариев вывода, где пользовательский опыт имеет решающее значение.
Архитектура GPU Blackwell от NVIDIA: B200
Архитектура Blackwell включает новые возможности, такие как тензорные ядра 5-го поколения (fp8, fp4), Tensor Memory (TMEM) и пары CTA (2 CTA).
-
TMEM: Tensor Memory — это новый уровень внутренней памяти, дополняющий традиционную иерархию регистров, общей памяти (L1/SMEM) и глобальной памяти. В Hopper (например, H100) данные на кристалле управлялись через регистры (на поток) и общую память (на блок потоков или CTA) с высокоскоростными передачами через Tensor Memory Accelerator (TMA) в общую память. Blackwell сохраняет это, но добавляет TMEM как дополнительные 256 КБ SRAM на SM, выделённые для операций с тензорными ядрами. TMEM принципиально не меняет способ написания CUDA-ядер (логический алгоритм остаётся прежним), но добавляет новые инструменты для оптимизации потока данных (см. ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (пары CTA) и кооперация кластеров: Blackwell также представляет пары CTA как способ плотного связывания двух CTA на одном SM. Пара CTA — это, по сути, кластер размером 2 (два блока потоков, запланированные одновременно на одном SM со специальными возможностями синхронизации). В то время как Hopper позволяет до 8 или 16 CTA в кластере для обмена данными через DSM, пара CTA Blackwell позволяет им совместно использовать тензорные ядра на общих данных. Фактически, модель Blackwell PTX позволяет двум CTA выполнять инструкции тензорного ядра, которые получают доступ к TMEM друг друга.
-
Тензорные ядра 5-го поколения (fp8, fp4): Тензорные ядра в B200 заметно больше и в 2–2,5 раза быстрее, чем тензорные ядра в H100. Высокое использование тензорных ядер критично для достижения основных новых ускорений оборудования поколения (см. Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Характеристики производительности без спарсификации
| Технические характеристики | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0,989 PFLOPS | 2,25 PFLOPS |
| INT8 | 1,979 PFLOPS | 4,5 PFLOPS |
| FP8 | 1,979 PFLOPS | 4,5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| Память GPU | 80 ГБ HBM3 | 180 ГБ HBM3E |
| Пропускная способность памяти GPU | 3,35 ТБ/с | 7,7 ТБ/с |
| Пропускная способность NVLink на GPU | 900 ГБ/с | 1800 ГБ/с |
Микротестирование операторов GEMM и внимания показывает следующее:
- BF16 и FP8 cuBLAS, CUTLASS GEMM ядра: до 2× быстрее, чем cuBLAS GEMM на H100;
- Внимание: cuDNN быстрее в 2 раза быстрее, чем FA3 на H100.
Результаты тестирования показывают, что B200 исключительно хорошо подходит для крупномасштабных рабочих нагрузок AI, особенно для генеративных моделей, требующих высокой пропускной способности памяти и плотных вычислений.
Сложности со стандартными стеками вывода
Запуск FLUX-dev на типовых конвейерах вывода (например, PyTorch + Hugging Face Diffusers), даже на высокопроизводительных GPU, таких как H100, представляет несколько проблем:
- Высокая задержка на одно изображение из-за накладных расходов CPU-GPU и отсутствия слияния ядер;
- Неоптимальное использование GPU и простаивающие тензорные ядра;
- Узкие места памяти и пропускной способности во время итеративных шагов диффузии.
Целевые показатели оптимизации обслуживания крупномасштабного и дешёвого вывода — это более высокая пропускная способность и более низкая задержка, снижающие стоимость генерации изображения.
Собственная платформа вывода WaveSpeedAI
WaveSpeedAI решает эти узкие места с помощью собственной платформы, разработанной специально для генеративного вывода. Разработанная основателем Зейи Чэнгом, эта платформа — это наш внутренний высокопроизводительный механизм вывода, оптимизированный специально для передовых моделей трансформеров диффузии, таких как FLUX-dev и Wan 2.1. Ключевые инновации в механизме вывода включают:
- Выполнение конца в конец на GPU, устраняющее узкие места CPU;
- Пользовательские CUDA-ядра и слияние ядер для оптимизированного выполнения;
- Продвинутая квантизация и смешанная точность (BF16/FP8) с использованием Blackwell Transformer Engine при сохранении наивысшей точности;
- Оптимизированное планирование памяти и предварительное распределение;
- Механизмы планирования, ориентированные на задержку, которые приоритизируют скорость над глубиной пакетной обработки.
Наш механизм вывода следует совместному проектированию оборудование-программное обеспечение, полностью используя вычислительные и памятные возможности B200. Это представляет значительный скачок вперёд в обслуживании моделей AI, позволяя нам обеспечить ультранизкую задержку и эффективный вывод в производственном масштабе. Мы оцениваем влияние этих оптимизаций на качество результатов, отдавая приоритет потерь vs. слабым оптимизациям. То есть мы не применяем оптимизации, которые могли бы значительно снизить возможности модели или полностью разрушить видимое качество результатов, такие как рендеринг текста и семантика сцен.
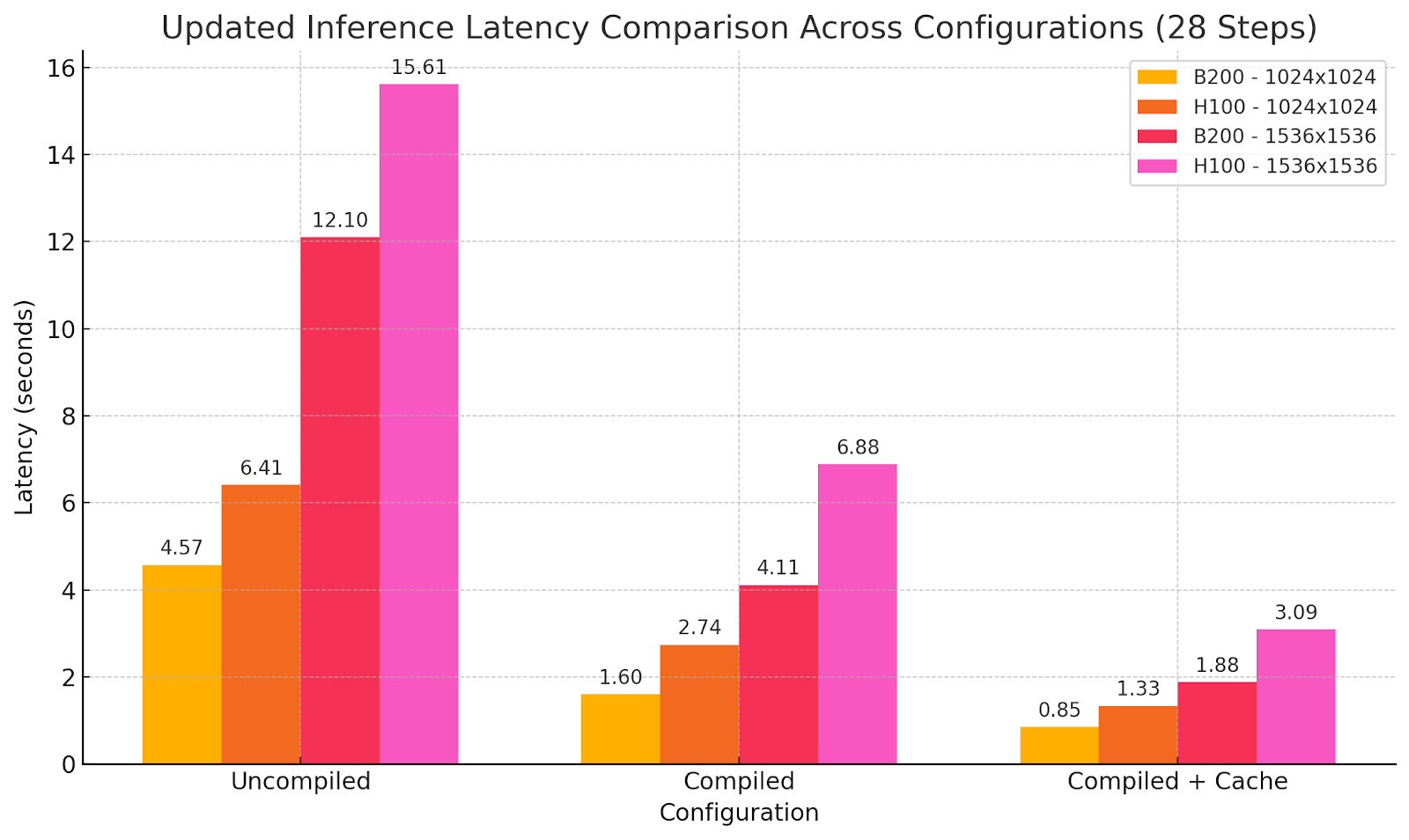
Тестирование: WaveSpeedAI на B200 vs. эталон H100
Выходные данные модели с использованием различных параметров оптимизации:

Запрос: портретная фотография альтернативной девушки с оранжевым платком, светлокоричневыми длинными волосами, прозрачными оправами очков, пирсингом в перегородке, бежевым комбинезоном, спадающим с одного плеча, белым топом без рукавов, она сидит в своей квартире на богемном коврике, в стиле снимка для журнала Vogue
Последствия
Улучшения производительности переводятся в:
- Проектирование AI-алгоритмов (например, кэширование активаций DiT) и оптимизация системы, используя ядра, настроенные под архитектуру GPU, для лучшего использования оборудования;
- Сниженная задержка вывода, открывающая новые возможности (например, Test-Time Compute in diffusion models);
- Сниженная стоимость на одно изображение благодаря улучшенной эффективности и сниженному использованию оборудования.
Мы достигли соотношения эффективности затрат B200 к H100, но с половинной задержкой генерации. Таким образом, стоимость на одну генерацию не увеличивается, при этом включая новые возможности реального времени без ущерба для возможностей модели. Иногда больше не означает лучше, но отличается, и здесь мы достигли нового этапа производительности, обеспечивая новый уровень пользовательского опыта в генерации изображений с использованием современных моделей.
Это обеспечивает отзывчивые творческие инструменты, масштабируемые платформы контента и устойчивые структуры затрат для генеративного AI в большом масштабе.
Заключение и следующие шаги
Развёртывание FLUX-dev с использованием B200 демонстрирует, что возможно, когда лучшее оборудование в мире встречается с лучшим в своём классе программным обеспечением. Мы продвигаем границы скорости и эффективности вывода в WaveSpeedAI, основанной Зейи Чэнгом — создателем stable-fast, ParaAttention и нашего внутреннего механизма вывода. В следующих выпусках мы сосредоточимся на эффективном выводе генерации видео и на том, как достичь вывода, близкого к реальному времени. Наше партнёрство с DataCrunch представляет возможность получить доступ к передовым GPU, таким как B200, и предстоящим NVIDIA GB200 NVL72 (Предзаказ кластеров NVL72 GB200 от DataCrunch), одновременно совместно разрабатывая критическую платформу инфраструктуры вывода.”
Начните работу уже сегодня:
- Веб-сайт WaveSpeedAI
- Все модели WaveSpeedAI
- Документация API WaveSpeedAI
- Экземпляры DataCrunch B200 по требованию/spot
Присоединяйтесь к нам, пока мы создаём самую быструю в мире инфраструктуру вывода генеративного AI.
Похожие статьи

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение

Apple SHARP: Превратите любое фото в 3D менее чем за секунду

Seedream 4.5 vs Nano Banana Pro: какая модель генерации изображений на ИИ лучше?
Лучшая альтернатива Adobe Firefly в 2026: WaveSpeedAI для генерации изображений с помощью ИИ