HunyuanImage-3.0: Развитие открытого мультимодального визуального генерирования

Генераторы изображений на основе ИИ есть везде, но будем честны — результаты могут быть непредсказуемыми, особенно при сложных подсказках или большом количестве деталей.
На помощь приходит HunyuanImage-3.0! Это первая с открытым исходным кодом, промышленного класса мультимодальная модель, созданная для генерации изображений, отличающаяся выдающимся рассуждением, стилем и даже отрисовкой длинного текста.
Основные преимущества
Эстетическое совершенство
HunyuanImage-3.0 демонстрирует глубокое понимание восточной эстетики, включая традиционные праздники, оперу и культурные символы. Модель может генерировать аутентичные и визуально впечатляющие результаты. Она также хорошо адаптируется к различным художественным стилям, от классического западного искусства до современного дизайна и кросс-культурных проектов, всегда оставаясь верной предполагаемой эстетике.
Рассуждение на основе знания о мире
Представьте ИИ с мозгом, который понимает мировое знание. Благодаря огромной базе знаний, HunyuanImage-3.0 может интерпретировать даже простые подсказки, например создание комикс-руководства — и преобразовать их в ясные, творческие и содержательно богатые визуальные образы.
Мощное семантическое понимание
Большинство генераторов изображений на основе ИИ борются с длинными отрывками или мелким текстом, но HunyuanImage-3.0 исключительно хорошо справляется с этими сценариями. Она обладает сильным пониманием текста, позволяя ей точно отображать подробное текстовое содержимое внутри изображений и производить впечатляющие результаты.
Превосходное качество
Обученная на тщательно отобранных наборах данных и улучшенная с помощью RLHF, модель создает сильное контекстное осознание, позволяя ей генерировать результаты, которые не только логически согласованы, но и визуально потрясающи.
Посмотрите в действии
Чтобы продемонстрировать эти возможности. Теперь время для примеров!!
Рассуждение на основе знания о мире
Поскольку модель загружена всеми видами увлекательного знания, давайте посмотрим, сможет ли она помочь нам научиться делать мороженое.
Подсказка: Создайте комикс-руководство о том, как делать мороженое.

Насколько хорошо модель понимает математику? Давайте попробуем!
Подсказка: Нарисуйте следующую систему бинарных линейных уравнений и соответствующие этапы решения на доске: 5x+2y= 26; 2x-y= 5.

Модель явно демонстрирует сильное понимание математических уравнений, правильно решая каждый шаг. Чтобы добавить веселья, давайте попросим её генерировать какие-нибудь эмодзи!
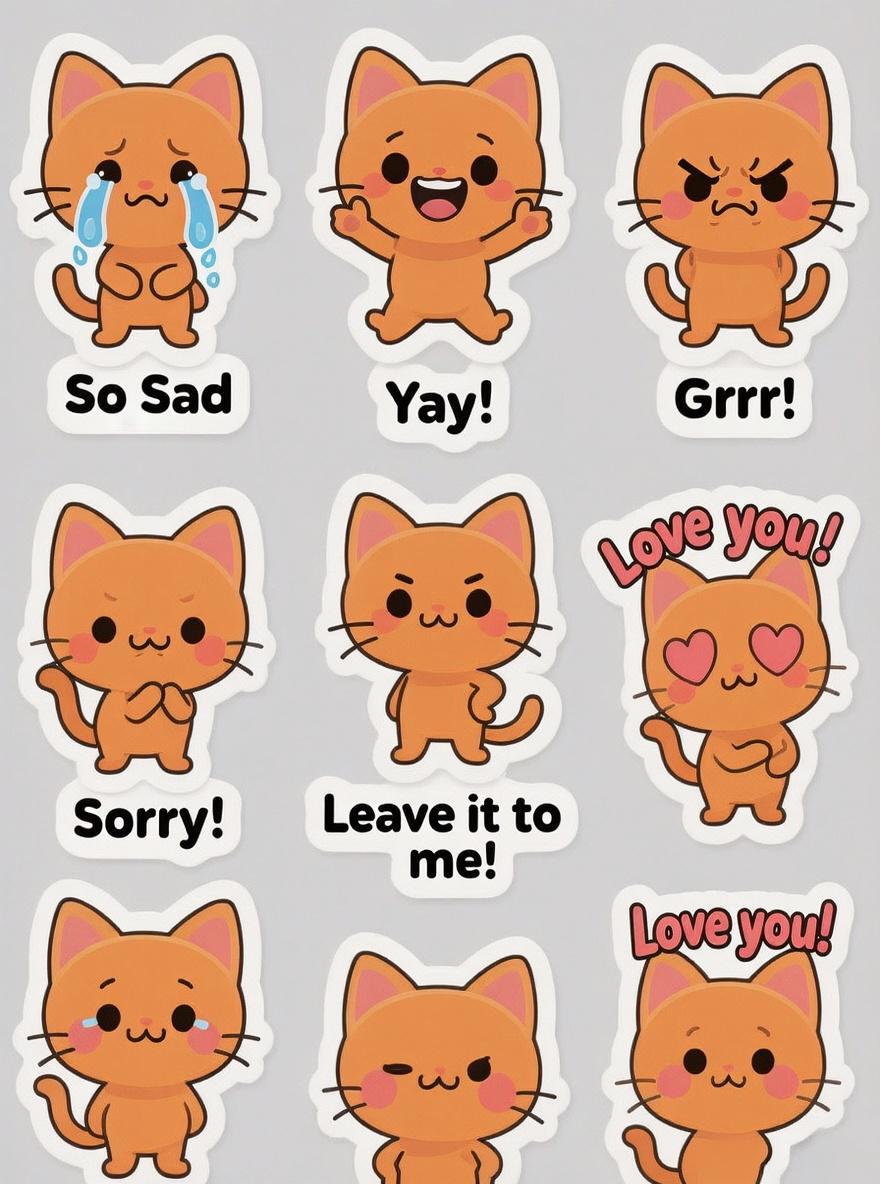
Подсказка: Лист наклеек с милой и выразительной рыжей чиби кошкой. Набор из 12 наклеек, каждая показывает разное чувство или действие, такие как плач, ликование, гнев, извинение и уверенность. Каждая наклейка имеет соответствующий текстовый ярлык (например, “Извини!”, “Люблю тебя!”, “Оставь на мне!”). Стиль чистый, минималистичный векторный рисунок с толстой белой границей, идеально подходящий для печати.
Супер сильное семантическое понимание
Чтобы оценить способность модели с текстом, мы пропустим простые задачи и сразу перейдем к сложной части: написание длинных отрывков на доске!
Подсказка: Широкое изображение, снятое со смартфона стеклянной доски с маркерами спереди, в комнате с видом на залив Шэньчжэнь. Поле зрения показывает женщину, указывающую на надписи на доске. Надпись выглядит естественно и немного беспорядочно. В верхней части заголовок гласит: “HunyuanImage 3.0”, за ним следуют два абзаца. Первый абзац гласит: “HunyuanImage 3.0 — это модель с открытым исходным кодом с 80 миллиардами параметров, которая генерирует изображения из сложного текста с превосходным качеством.”. Второй абзац гласит: “Она использует мировое знание и продвинутое рассуждение, чтобы помочь создателям эффективно создавать профессиональные визуальные образы.” Внизу есть подзаголовок: “Ключевые возможности”, за которым следуют четыре пункта. Первый: ”🧠 Нативная мультимодальная большая языковая модель”. Второй: ”🏆 Самая крупная модель Text-to-Image MoE”. Третий: ”🎨 Соблюдение подсказок и обобщение концепций”, и четвёртый: ”💭 Нативное мышление и переописание”.

Отлично! Эффект просто фантастический!
Эстетическое совершенство
Последнее достоинство — замечательное понимание восточной эстетики моделью.
Подсказка: Китайская красавица в красочном костюме Пекинской оперы, с китайским трендовым образом Huadan, поясной портрет в фокусе на её очаровательных глазах. Изображение выполнено в стиле макрофотографии, высокое разрешение, воображаемое, фотосъёмка реального человека, с акцентом на детали и реализм. Композиция использует крупный план, с красавицей в центре кадра, её глаза доминируют в положении, а фон размыт, чтобы выделить глубокое очарование её глаз. Таинственный холодный свет сверху создаёт холодную и суровую голубую атмосферу, мягкий и сосредоточенный свет усиливает очарование и тайну её глаз. Диафрагма f/2.8, макрообъектив 100 мм, неглубокая глубина резкости, разрешение 8K.

Подсказка: Милый домашний кот, выставленный в сетке 3x3 на чистом, ярком кремовом однотонном фоне, демонстрирующий девять тематических поз для фестиваля Середины осени: 1. Носит маленький заколку в виде кленового листа, высунув язык, чтобы лизать крошки луны на носу, с озорным выражением.2. Носит карамельно-коричневый маленький свитер (с изысканной вышивкой нефритового кролика), сидит прямо, держит миниатюрный китайский фонарик передними лапами.

Заключительные мысли
HunyuanImage-3.0 превращает генерацию текста в изображение из просто функциональной в истинно интеллектуальную и промышленного класса. С ускорением WaveSpeedAI, её достижения также практичны — они быстрые, развертываемые и экономичные.
Вместе HunyuanImage-3.0 и WaveSpeedAI трансформируют будущее мультимодального создания: умнее, быстрее и доступнее!
Кроме того, вы можете связаться с нами в социальных сетях ниже.
Похожие статьи

Лучшие AI редакторы изображений в 2026 году: Профессиональное редактирование фото с помощью ИИ
Лучшая альтернатива Tencent Hunyuan Image 3.0 в 2026 году: WaveSpeedAI для генерации изображений с помощью ИИ
Полное руководство Hunyuan Image 3.0: AI-модель Tencent с 80B параметрами
Hunyuan Image 3.0 vs Seedream 4.5: Битва азиатских гигантов ИИ
WaveSpeedAI vs Tencent Hunyuan Image 3.0: Какая платформа AI дает лучшие результаты?
