GLM-4.7-Flash vs GLM-4.7: Какой выбрать для вашего проекта?

Привет, друзья. Я Дора. Если это вам знакомо, вы не одиноки. Я была там: смотрела на очередь крошечных повторяющихся запросов, которым нужен быстрый, надежный ответ — а в то же время пара упрямых многошаговых задач рассуждения сидят в углу, тихо требуя гораздо больше вычислительной мощности.
И я наконец задала вопрос вслух: где именно светит легкий, молниеносно быстрый GLM-4.7-Flash, и где вам нужно подключить более тяжелый, более вдумчивый GLM-4.7? Вот честный, без лишней шумихи ответ, к которому я пришла — основанный на реальных запусках, бенчмарках, когда они имеют значение, и на тихой цели сделать вашу ежедневную работу заметно более легкой. Если вы когда-либо задавались вопросом «какую модель мне даже использовать здесь?», это для вас.
Ответ за 30 секунд
Если скорость и низкая стоимость — ваши главные приоритеты, GLM-4.7-Flash, вероятно, покажется правильным выбором. Если ваша работа полагается на глубину рассуждений, использование инструментов или более высокое качество выходных данных, GLM-4.7 — более надежный выбор. Остальное — это нюансы задержек, размер контекста и поведение ваших запросов под давлением.
Выбирайте Flash, если…
Flash не «слабее» — он просто честен о том, в чём он хорош.
- Вы отправляете много небольших задач: резюме, теги, черновики, быстрые преобразования.
- Задержка важнее, чем выжимание последних 10% качества.
- Вы экспериментируете, прототипируете или строите взаимодействия пользовательского интерфейса, которые должны быть мгновенными.
- Случайные сбои в длинных цепочках рассуждений не сломают вас.
- Вы хотите более дешевую модель по умолчанию и можете переключиться на GLM-4.7 только когда это необходимо.
Выбирайте GLM-4.7, если…
Это ваша модель «не испортить».
- Вам важна надежность кода, многошаговое рассуждение или точность использования инструментов.
- Запросы длинные, инструкции строгие или выходные данные должны быть последовательными.
- Вы запускаете оценки, тесты или рабочие процессы, где одна ошибка дорого стоит.
- Вам нужны более сильные результаты для задач кодирования и с большим контекстом.
- Вы можете допустить более высокую стоимость и немного большую задержку для лучших результатов.
Различия в архитектуре
 Я не охотясь за количеством параметров ради спорта, но архитектура многое объясняет о поведении: почему одна модель кажется быстрой, а другая кажется вдумчивой.
Я не охотясь за количеством параметров ради спорта, но архитектура многое объясняет о поведении: почему одна модель кажется быстрой, а другая кажется вдумчивой.
Количество параметров и активные эксперты
GLM-4.7 использует более крупный основной слой и (согласно открытым заметкам) использует маршрутизацию экспертов, которая приоритизирует рассуждения. Flash оптимизирован для пропускной способности, облегченной маршрутизации, меньшего количества активных экспертов на токен и агрессивных настроек эффективности. На практике это обычно проявляется как:
- Flash: меньше вычислений на токен, быстрое первое время токена, но может потерять цепочки рассуждений под нагрузкой.
- GLM-4.7: больше вычислений на токен, более стабильные пути рассуждений, лучший выбор функций.
Если вы просмотрите диаграммы поставщиков, вы увидите намеки на смесь экспертов (MoE) и разреженность активации. Точные цифры варьируются в разных версиях, поэтому я рассматриваю их как ориентировочные, а не абсолютные. Основная идея: Flash тратит меньше «размышлений» на токен, поэтому движется быстрее; GLM-4.7 думает дольше и реже спотыкается о граничные случаи.
Размер контекстного окна и лимит выхода
Два практических вопроса имеют больше значения, чем заголовочный номер контекста:
- На сколько далеко в длинные запросы сохраняется качество?
- Когда выходные данные становятся длинными, теряет ли модель нить?
Flash обычно рекламирует здоровое окно контекста, но качество имеет тенденцию падать быстрее с очень длинными запросами или плотными инструкциями. GLM-4.7 сохраняет связность глубже в длинные контексты и остается более послушным структуре в длинных выходах. Если вы упаковываете базу знаний, GLM-4.7 — более безопасный выбор по умолчанию. Если вы разбиваете входные данные или используете поиск для сохранения тонких запросов, Flash часто достаточно — и намного быстрее.
Сравнение бенчмарков
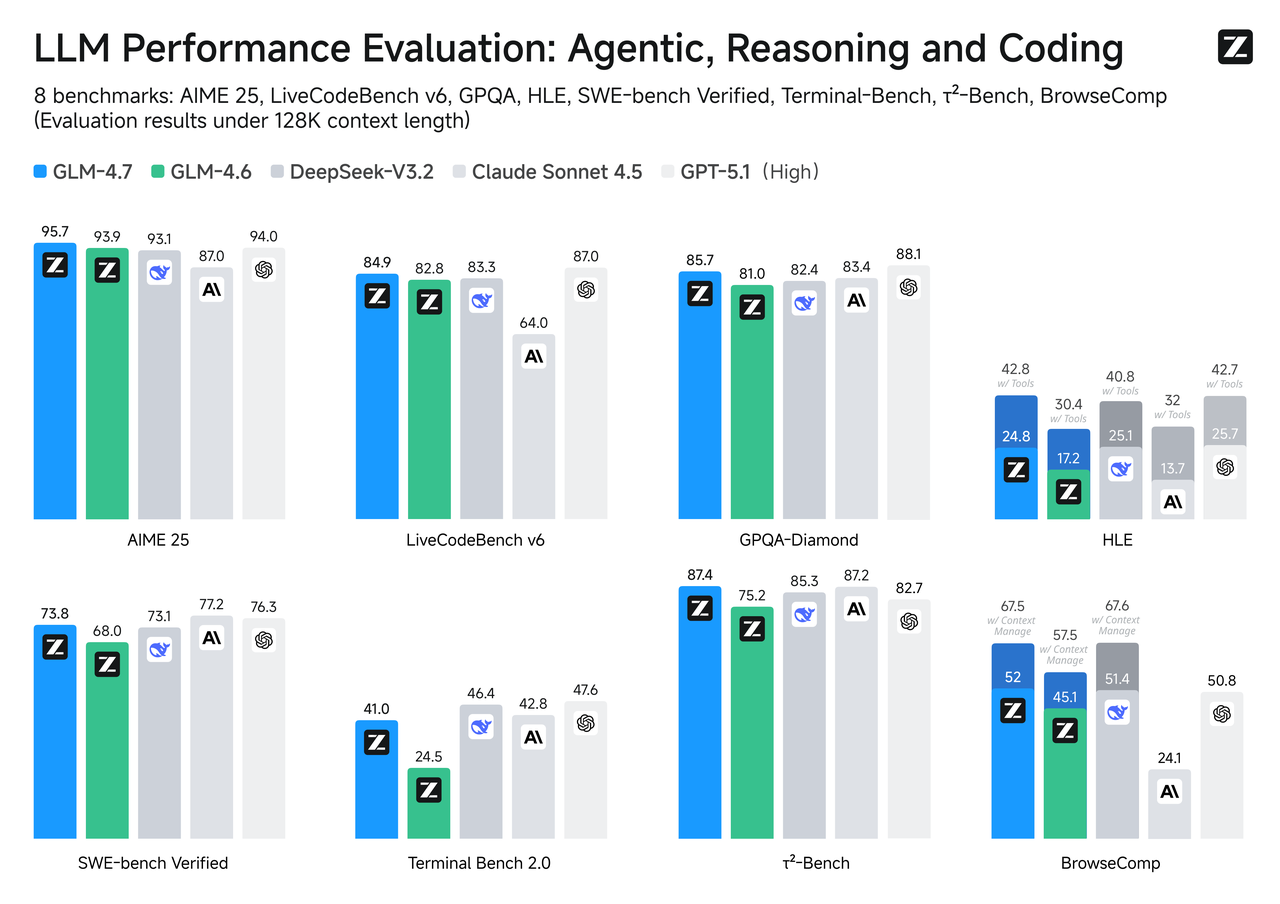 Бенчмарки — это не вся история, но они полезный компас, особенно когда ваш случай использования совпадает с задачей.
Бенчмарки — это не вся история, но они полезный компас, особенно когда ваш случай использования совпадает с задачей.
SWE-bench Verified
Для изменений кода, которые должны фактически компилироваться и проходить тесты, GLM-4.7 обычно ранжируется выше своего Flash коллеги. Это совпадает с тем, чего вы ожидаете от модели, настроенной на глубину рассуждений и использование инструментов. Flash может составить исправления и хорошо объяснить код, но когда патч требует нескольких скоординированных правок по файлам, GLM-4.7 с большей вероятностью будет следовать цепочке без потери шагов.
Если ваш конвейер включает авто-PR или циклы восстановления, стоит сначала проверить с небольшой выборкой. Разница проявляется больше на многошаговых проблемах, чем на одно-файловых правках.
LiveCodeBench / τ²-Bench
На живых или ротирующих по времени бенчмарках кодирования GLM-4.7 в целом отслеживает топ-уровень, учитывая его более тяжелый бюджет рассуждений. Flash, оптимизированный для скорости, сидит на уровень ниже, но быстро реагирует. Если ваш продукт больше полагается на качество синтеза кода, чем на скорость взаимодействия, GLM-4.7 — консервативный выбор. Если код рекомендательный (вы все равно его рассмотрите) и скорость отклика важна, Flash может быть правильным компромиссом.
Скорость и задержка
Здесь разделение ощущается наиболее четко. Flash часто возвращает первый токен заметно быстрее, и общее время до последнего токена остается низким для коротких и средних выходов. Это добавляется, если вы запускаете много небольших вызовов или потоковую передачу в пользовательский интерфейс.
GLM-4.7 начинается медленнее и работает тяжелее, но более стабилен при длинных генерациях и сложных последовательностях вызовов функций. Вы увидите меньше зависаний, меньше странных отклонений и лучшее соответствие схемам функций.
Если вы строите систему:
- Используйте Flash для высокотрафичных моментов пользовательского интерфейса: автодополнение, быстрые резюме, встроенная справка.
- Используйте GLM-4.7 для медленной полосы: оценки, действия кода, проверки политики, финальные проходы.
Простое правило маршрутизации часто окупается: начните с Flash, переключитесь на GLM-4.7, когда уверенность падает или пороги пересекаются. Позвольте правилам решать, чтобы вам не пришлось.
Разбор ценообразования
Цены варьируются по регионам и поставщикам, поэтому я рассматриваю цифры как движущиеся цели и держу структуру стабильной.
Flash бесплатный уровень vs GLM-4.7 плата за токен
-
Flash: многие платформы предоставляют бесплатный или низкостоимостной уровень для Flash-подобных моделей с щедрыми ограничениями скорости по сравнению с флагманскими моделями. Отлично для прототипирования, фоновых задач и отделки пользовательского интерфейса.
-
GLM-4.7: обычно начисляется за токен по более высокой ставке. Лучшее соотношение стоимости и качества для серьезных задач, но легко переварить, если оставить его как выбор по умолчанию.
 Практические советы:
Практические советы: -
Ограничьте выходные токены по умолчанию. Поднимайте крышку только в маршрутах, которым она нужна.
-
Используйте поиск для сохранения коротких запросов: не выливайте весь корпус в окно.
-
Кешируйте детерминированные подрезультаты (карты regex, фрагменты схемы, блоки few-shot), чтобы вы не платили за них снова.
-
Логируйте стоимость токенов за маршрут. Отчет, который вы на самом деле читаете, — это тот, что находится в вашем еженедельном рабочем процессе, а не тот, у которого больше всего графиков.
Когда сомневаетесь, начните дешево, измеряйте, затем повышайте. Эскалация бьет оптимизм.
Выбирайте по варианту использования
Вот как я бы их расставил, когда цель — меньше головной боли:
- Высокооборотные операции с контентом (фрагменты, строки темы, метаданные): Flash. Выигрыш — это пропускная способность и последовательность при низкой стоимости.
- Макросы поддержки и быстрая сортировка: Flash сначала, затем эскалация на GLM-4.7, если обнаружение флагов сложность или риск политики.
- Исследовательские записки, синтез, структурированные резюме: Flash для беглого просмотра; GLM-4.7 для прохода, который должен быть верным источнику и хорошо структурирован.
- Помощь с кодом: Flash для объяснений и «что это делает?»; GLM-4.7 для многофайловых правок, миграций и изменений с учетом тестов.
- Очистка и преобразование данных: Flash подходит для простого отображения; GLM-4.7 для строгих схем, валидации и многошаговых объединений.
- Агенты и использование инструментов: GLM-4.7. Вы получите более надежные аргументы функций и меньше повторных попыток.
- Чтение с большим контекстом или вопросы ответа на основе документов: GLM-4.7, если вы расширяете окно; Flash, если вы сохраняете блоки стройными.
Несколько заметок из полевых наблюдений, которые я держу близко:
- Короткие запросы скрывают различия. Разница проявляется, когда инструкции плотные или выходные данные должны следовать структуре.
- Маршрутизация помогает. Даже простое правило, «Flash, если не нужен GLM-4.7, в иных случаях используй GLM-4.7», экономит деньги без драмы.
- Guardrails важнее выбора модели для повторяющихся задач. Валидация, повторные попытки и небольшие проверки предотвращают беспорядок в цепочке.
- Не фетишизируйте скорость. Под секунду ощущается «мгновенной» для большинства пользователей. После этого стабильное поведение побеждает срезание 100 мс.
Почему это имеет значение: инструменты хорошо стареют, когда они снижают умственную нагрузку. Flash держит мелкие вещи легкими. GLM-4.7 несет тяжелые коробки без их падения. Большинству стеков нужны оба.
Если вы не уверены, начните с Flash как вашего выбора по умолчанию и создайте четкую полосу для GLM-4.7. Позвольте маршрутам, а не настроениям, решать. Ваш опыт может отличаться, и это нормально.
Я все еще замечаю, в тихие дни, как это разделение снижает усталость от принятия решений. Ничего блестящего — просто меньше головной боли.
Как я на самом деле запускаю это разделение на практике
 Когда мне нужно маршрутизировать быстрые задачи на Flash и эскалировать более тяжелые на GLM-4.7 без присмотра к скриптам, я использую WaveSpeed — нашу собственную платформу.
Когда мне нужно маршрутизировать быстрые задачи на Flash и эскалировать более тяжелые на GLM-4.7 без присмотра к скриптам, я использую WaveSpeed — нашу собственную платформу.
Мы построили его для обработки переключения моделей, параллелизма и пакетных вызовов чисто, чтобы паттерн «Flash сначала, эскалировать при необходимости» оставался простым вместо хрупкого.
Если вы запускаете много небольших вызовов и не хотите, чтобы логика маршрутизации стала еще одной вещью для обслуживания, попробуйте Wavespeed!
ЧЗВ: GLM-4.7-Flash vs GLM-4.7
1. Каковы основные различия между GLM-4.7-Flash и GLM-4.7?
GLM-4.7-Flash — это легкий оптимизированный вариант GLM-4.7. Он достигает более быстрого вывода и более низкой стоимости путем уменьшения количества активных экспертов, упрощения маршрутизации и применения настроек эффективности. GLM-4.7 сохраняет более крупный основной слой и более сильные способности рассуждений, превосходя в сложном многошаговом рассуждении, когерентности с большим контекстом и точном вызове инструментов.
Коротко: Flash обменивает некоторый интеллект на скорость; GLM-4.7 приоритизирует глубину и надежность.
2. Какая модель быстрее, и в каких сценариях разница в скорости наиболее заметна?
GLM-4.7-Flash имеет значительно более низкое время до первого токена (TTFT) и задержку на токен. Он светит в сценариях высокой пропускной способности и низкой задержки, таких как взаимодействие пользовательского интерфейса в реальном времени, обобщение контента, генерация метаданных и быстрое прототипирование.
GLM-4.7 имеет более высокие начальные расходы и более тяжелые вычисления, но остается более стабильным для длинных выходов или сложных последовательностей вызовов функций. На практике Flash заметно быстрее для коротких и средних выходов (менее 500 токенов).
3. Какая модель сильнее в интеллекте и рассуждении?
GLM-4.7 превосходит Flash в многошаговом рассуждении, надежности кода, использовании инструментов и задачах с большим контекстом. Примеры:
- SWE-bench Verified: GLM-4.7 лидирует в редактировании кода на несколько файлов и скоординированных патчах.
- LiveCodeBench / τ²-Bench: GLM-4.7 обеспечивает код более высокого качества, особенно для сценариев глубокого рассуждения.
Flash подходит для однофайловых правок или вспомогательных задач, которые допускают проверку человеком, но деградирует быстрее при длинных цепочках рассуждений или плотных запросах.
4. Как сравниваются длина контекста и лимиты выхода?
Обе модели имеют схожие окна контекста, но GLM-4.7 сохраняет лучшую когерентность и следование инструкциям на очень длинные контексты (>32k токенов) или плотные запросы. Flash деградирует быстрее при экстремальной длине или плотности запроса — используйте его с разбиением или RAG для лучших результатов.
5. Как мне выбрать на основе ценообразования и контроля стоимости?
GLM-4.7-Flash обычно предлагает более высокие бесплатные квоты и более низкие (или даже нулевые) цены за токен, что делает его идеальным для прототипирования, фоновых задач и высокообъемных низкорисковых вызовов. GLM-4.7 имеет более высокие стоимости за токен, но лучшую ценность для критических задач.
Рекомендация: используйте Flash по умолчанию, эскалируйте на GLM-4.7 для сложной работы и всегда устанавливайте лимиты токенов и кеширование, чтобы предотвратить переборщение.
Похожие статьи

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
