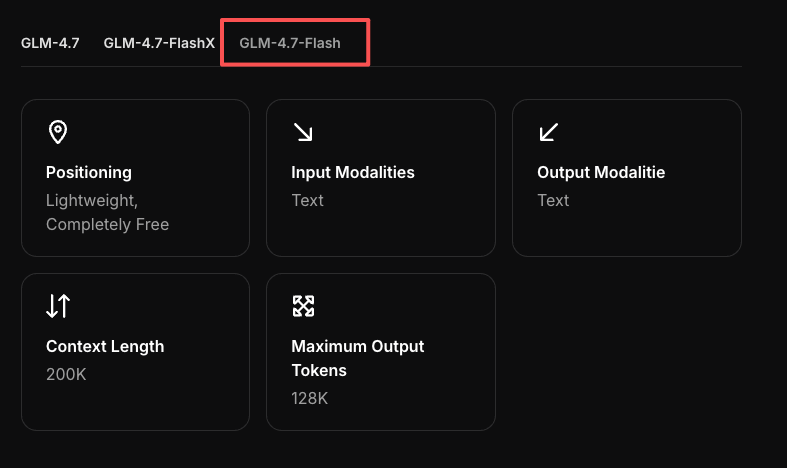
GLM-4.7-Flash API: быстрый старт с Chat Completions и потоковой передачей

Привет, я Дора. На прошлой неделе я столкнулась с небольшой проблемой: задачей по созданию черновика резюме, которая казалась тяжелее, чем должна была быть. Инструменты, которые я обычно использую, были либо слишком медленными, либо слишком умными для собственного блага. Я хотела что-то быстрое и предсказуемое, даже если это не было впечатляющим.
Поэтому я тщательно протестировала GLM-4.7-Flash API (январь 2026). Я не искала “вау-эффект”. Мне нужны были чистые запросы, быстрые ответы и параметры, которые ведут себя так, как они заявляют. Вот что я настроила, что помогло, где произошли сбои и почему я буду использовать это снова, когда мне нужна скорость без проблем.
Получите свой API-ключ
Я начала просто: получить ключ, сделать запрос, посмотреть, имеют ли смысл базовые вещи. Я ценю API, которые не скрывают рычаги управления. Для справки: GLM-4.7-Flash — это часть более широкого семейства моделей GLM от Zhipu AI, которое определяет многие дизайнерские решения вокруг скорости и предсказуемости.

Обзор панели управления WaveSpeed
Я использовала панель управления WaveSpeed, которая обеспечивает доступ к GLM-4.7-Flash API. Процесс был достаточно простым:
- Создать проект (я назвала свой “flash-notes”).
- Сгенерировать серверный ключ и легкий клиентский токен. В своих локальных скриптах я использовала только серверный ключ.
- Просмотреть панель использования, чтобы заметить ограничения частоты по умолчанию. На моей панели отображался скромный лимит всплеска и квота в минуту, достаточная для тестов, но не для скачка в production.
Небольшая вещь, которая мне понравилась: панель управления показывает недавние ошибки 4xx/5xx с временными метками. Когда я позже столкнулась с ограничениями, мне не пришлось гадать. Если вы работаете в команде, видимость ключей на основе ролей помогла: я хранила ключ с правом записи в файле .env и переключилась один раз на неделю, чтобы проверить, работает ли отзыв (работал, моментально).
Базовый запрос
Моя первая контрольная точка была той же, что я использую для любой новой модели: короткий запрос, короткий ответ и никаких неожиданностей в JSON.
Схема API следует тому же паттерну chat-completions, описанному в официальном руководстве GLM-4.7 API, что означало, что мне не нужно было переучивать семантику запросов.
Пример curl
Вот самый простой вызов, который работал для меня последовательно. Имя конечной точки может отличаться у разных провайдеров: это паттерн, который я использовала во время тестов.
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{"role": "user", "content": "Summarize this in one sentence: GLM-4.7-Flash API quick test."}
],
"temperature": 0.2,
"max_tokens": 120
}'Заметки из проведённого тестирования
- Задержка: первый токен я видела примерно за 200–400 мс на небольшом запросе в середине утра (время США). Конец в конец завершался менее чем за секунду для коротких ответов.
- Стабильность: ответы были правильно сформированным JSON каждый раз, когда потоковая передача была отключена.
- Стоимость: я не могу говорить о вашем плане, но токены четко отображались в журналах использования. Это важно, когда вы проводите быстрые итерации.
Пример на Python
Для небольших скриптов я предпочитаю одну функцию с ключами, загруженными из переменных окружения.
import os
import requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{
"role": "user",
"content": "Give me 3 bullet points on maintaining a calm writing workflow."
}
],
"temperature": 0.3,
"max_tokens": 180
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
resp = requests.post(BASE_URL, json=payload, headers=headers, timeout=30)
resp.raise_for_status()
data = resp.json()
print(data["choices"][0]["message"]["content"]) # typical OpenAI-style schemaДва небольших впечатления:
- Облегчение: схема совпадала с обычным форматом chat-completions, что означало отсутствие слоя-адаптера. Я интегрировала это в существующий инструмент с минимальными изменениями.
- Ограничение: более длинные выходные данные при более высокой температуре иногда становились многословными. Это нормально для моделей типа “Flash”: я обрезала с помощью
max_tokensи настраивала тон через более строгий системный запрос.
Включите потоковую передачу
Я включаю потоковую передачу только когда формирую текст в реальном времени или когда задержка имеет большее значение, чем полнота. GLM-4.7-Flash казалась для этого идеальной: быстрые первые токены, стабильное разбиение на части после правильной установки параметров.
Настройка параметров потоковой передачи
Чтобы включить server-sent events (SSE), я установила stream: true. Это всё. Остальное — это организационные вопросы: убедитесь, что ваш клиент читает строки событий и останавливается на [DONE].
Версия curl, которую я использовала:
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-N \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "user", "content": "Draft a two-sentence intro about quiet tools."}
],
"stream": true,
"temperature": 0.2,
"max_tokens": 120
}'Две полевые заметки:
- Если забыть
-N(no-buffer) с curl, поток может выглядеть зависшим. - Если получить простой JSON blob вместо событий, дважды проверьте, что
stream— это булевоtrue, а не строка.
Обработка фрагментов в коде
На Python я читаю построчно, разбираю кадры data: и останавливаюсь на дозорной строке. Этот паттерн работал плавно.
import os, json, requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [{"role": "user", "content": "Write a calm closing paragraph."}],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
json=payload,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line or not line.startswith("data:"):
continue
data = line[len("data:"):].strip()
if data == "[DONE]":
break
try:
delta = json.loads(data)["choices"][0]["delta"].get("content", "")
print(delta, end="", flush=True)
except (KeyError, json.JSONDecodeError):
# Skip malformed or heartbeat frames gracefully
continue
print() # newlineЧто меня немного удивило: время между фрагментами было стабильным. Я попробовала несколько более длинных запросов и по-прежнему получала предсказуемый темп. Потоковая передача не экономила общее время для очень коротких ответов, но снижала мое ощущение ожидания, что имеет значение, когда я редактирую непосредственно в терминале.
Справочник по параметрам
Я только немного изменяю несколько параметров ежедневно. С GLM-4.7-Flash API они вели себя, как и ожидалось.
temperature / top_p / max_tokens
- temperature: я держала это между 0,1 и 0,4 для производственных задач. Более низкие числа давали более плотные, менее воображаемые фразы, что приемлемо для резюме и вспомогательного текста. Если вы поднимаетесь выше 0,7, ожидайте отклонений.
- top_p: я оставляла top_p примерно на 0,9. Когда я сделала его более тесным (0,6) при низкой температуре, выходные данные казались обрезанными, полезными для маркированных списков, но менее полезными для нюансированного письма.
- max_tokens: это была моя защита. Для задач короткой формы 150–250 сохраняли расходы аккуратными и предотвращали многословность. Для очертаний 600–800 было достаточно. Если модель останавливается рано, это обычно это, а не ошибка.
Небольшая настройка, которая хорошо сработала для меня, когда мне нужны были четкие, фактические ответы:
{
"model": "GLM-4.7-Flash",
"temperature": 0.2,
"top_p": 0.9,
"max_tokens": 200
}Почему это имеет значение на практике: когда вам нужна скорость, вы не хотите переписывать. Консервативная температура с щедрым, но не неограниченным max_tokens сэкономила мне необходимость запускать один и тот же вызов дважды только для обрезания фраз.
Частые ошибки
 Я держала маленький блокнот рядом со мной во время тестирования. Две ошибки произошли достаточно часто, чтобы стоило их упомянуть прямо.
Я держала маленький блокнот рядом со мной во время тестирования. Две ошибки произошли достаточно часто, чтобы стоило их упомянуть прямо.
429 Rate Limit
Что я видела:
- Всплески параллельных запросов (5–10 одновременно) иногда срабатывали 429. Это происходило чаще в первую минуту работы нового ключа.
Что помогло:
- Backoff: дрожащая экспоненциальная задержка (например, 200 мс, 400 мс, 800 мс, до ~3 с) устранила скачки без моего надзора.
- Очереди: объединение почти идентичных запросов в короткое временное окно (100–200 мс) снизило мой пиковый показатель примерно на 30% без изменения UX.
- Проверки панели управления: панель использования подтвердила, когда проблема была во мне. Никакой тайны там, что я оценила.
Кто в это попадает: команды, интегрирующие GLM-4.7-Flash в предпросмотры UI и серверные перехватчики одновременно. Если это важно, спросите своего провайдера о более высоких пределах в минуту или используйте легкую очередь в памяти.
Invalid JSON Response
Что я видела:
- Когда потоковая передача включена, некоторые клиенты пытаются разобрать каждый кадр
data:как полный JSON. Так не работает SSE. Кадры частичные. - Однажды при шумном соединении я получила усечённую строку события, которая сломала строгие парсеры.
Что помогло:
- Защитите свой парсер: разбирайте только JSON после
data:и ожидайте, что он будет содержать небольшую дельту, а не полное сообщение. Останавливайтесь на[DONE]. - Таймауты: держите разумный таймаут чтения, но избегайте прерывания потока из-за одного неправильного кадра.
- Если вам нужен не потоковый JSON: отключите поток и вы обычно получите чистый, единственный JSON объект. В моих запусках режим без потока никогда не давал неправильно сформированный JSON.
Ещё одна небольшая проблема: если ваш прокси или сервер вводят логи в stdout, это может загрязнить поток. Держите логи отдельно от каналов ответов.
После всего этого тестирования причина, по которой я остановилась на WaveSpeed, довольно простая: я не хотела думать о сантехнике.
 Мы создали WaveSpeed, чтобы быть скучным, надежным слоем между вашим кодом и быстрыми моделями, такими как GLM-4.7-Flash. Чистые конечные точки, предсказуемое поведение и панель управления, которая говорит вам, что на самом деле произошло, когда что-то пошло не так — ограничения частоты, ошибки, использование — без угадывания.
Мы создали WaveSpeed, чтобы быть скучным, надежным слоем между вашим кодом и быстрыми моделями, такими как GLM-4.7-Flash. Чистые конечные точки, предсказуемое поведение и панель управления, которая говорит вам, что на самом деле произошло, когда что-то пошло не так — ограничения частоты, ошибки, использование — без угадывания.
Если вы интегрируете Flash в резюме, черновики, предпросмотры UI или фоновые задачи и просто хотите, чтобы это оставалось вне дороги, это именно то, что мы пытаемся заполнить. → Нажмите здесь!
Похожие статьи

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
