GLM-4.7-Flash: Дата выпуска, бесплатный уровень и ключевые функции (2026)

Привет, я Дора.
Недавно GLM-4.7-Flash постоянно всплывал в обсуждениях людей, которым я доверяю, обычно с небольшим пожатием плеч: «быстро достаточно, чтобы не мешать». Эта фраза запомнилась. Я не гонюсь за блестящими моделями прямо сейчас: я ищу инструменты, которые делают повседневную работу легче. Вы понимаете?
Поэтому я дал GLM-4.7-Flash несколько дней в моём стеке (20-21 января 2026). Короткие промпты, небольшие API-скрипты, пара пакетных задач. Ничего драматичного. Вопрос, который я держал в голове, был простым: это практичное дополнение или просто ещё одно имя модели, проходящее мимо?
Что такое GLM-4.7-Flash?
GLM-4.7-Flash — это вариант, ориентированный на скорость, из семейства GLM-4.7 компании Zhipu AI. Думайте о нём как о модели, к которой вы обращаетесь, когда хотите быстрый и низкозадержный результат без тяжёлого рассуждения. Она не пытается выиграть в длинных бенчмарках или философствовать: она нацелена на то, чтобы давать приличные ответы быстро и дёшево.
Кто это создал (Zhipu AI / Z.ai)
 Zhipu AI (также известная как Z.ai) — это команда, стоящая за серией GLM. Если вы использовали более ранние модели GLM, то номенклатура покажется знакомой: число отражает поколение, а суффикс (Flash, Standard и т. д.) намекает на компромиссы. Их документация понятна и регулярно обновляется: если вы интегрируете, добавьте в закладки официальную документацию API на портале разработчиков Zhipu.
Zhipu AI (также известная как Z.ai) — это команда, стоящая за серией GLM. Если вы использовали более ранние модели GLM, то номенклатура покажется знакомой: число отражает поколение, а суффикс (Flash, Standard и т. д.) намекает на компромиссы. Их документация понятна и регулярно обновляется: если вы интегрируете, добавьте в закладки официальную документацию API на портале разработчиков Zhipu.
Я использовал модели Zhipu то и дело в течение последнего года, когда мне требовалась многоязычная поддержка и стабильный, предсказуемый результат. GLM-4.7-Flash продолжает эту традицию, только с большим упором на скорость и пропускную способность.
Flash vs Standard, позиционирование
Вот как я почувствовал различия на практике:
- Flash: оптимизирована на скорость, более низкие вычисления на запрос, отлично подходит для высоконагруженных эндпоинтов, помощников пользовательского интерфейса и пакетной классификации или тегирования. Я заметил, что ей комфортнее с лаконичными промптами и чёткой структурой.
- Standard (без Flash): медленнее, но устойчивее на задачах, требующих рассуждения. Если я давал ей многошаговый анализ, она пыталась, но я видел, что она сокращает шаги, чтобы снизить задержку.
Если вы выбираете между ними, вот простое правило: если задержка и стоимость определяют ваш день, начните с Flash. Если точность при многошаговом рассуждении — ваше основное ограничение, то Standard (или более крупный брат, ориентированный на рассуждение) вероятно подойдёт лучше. Выбирайте своего бойца.
Официальный запуск: 19 января 2026
Zhipu AI объявила о GLM-4.7-Flash 19 января 2026 года. Я начал тестирование на следующий день. Версия имеет значение с этими моделями: ранние дни часто сопровождаются быстрой итерацией. Если вы читаете это позже, проверьте примечания к выпуску в официальной документации, чтобы подтвердить любые изменения в ограничениях или поведении.
Архитектура в двух словах
Мне не нужно знать внутреннее устройство модели, чтобы её использовать, но некоторые детали помогают мне оценить затраты и то, где она будет отличной.
30B MoE, 3B активных параметров
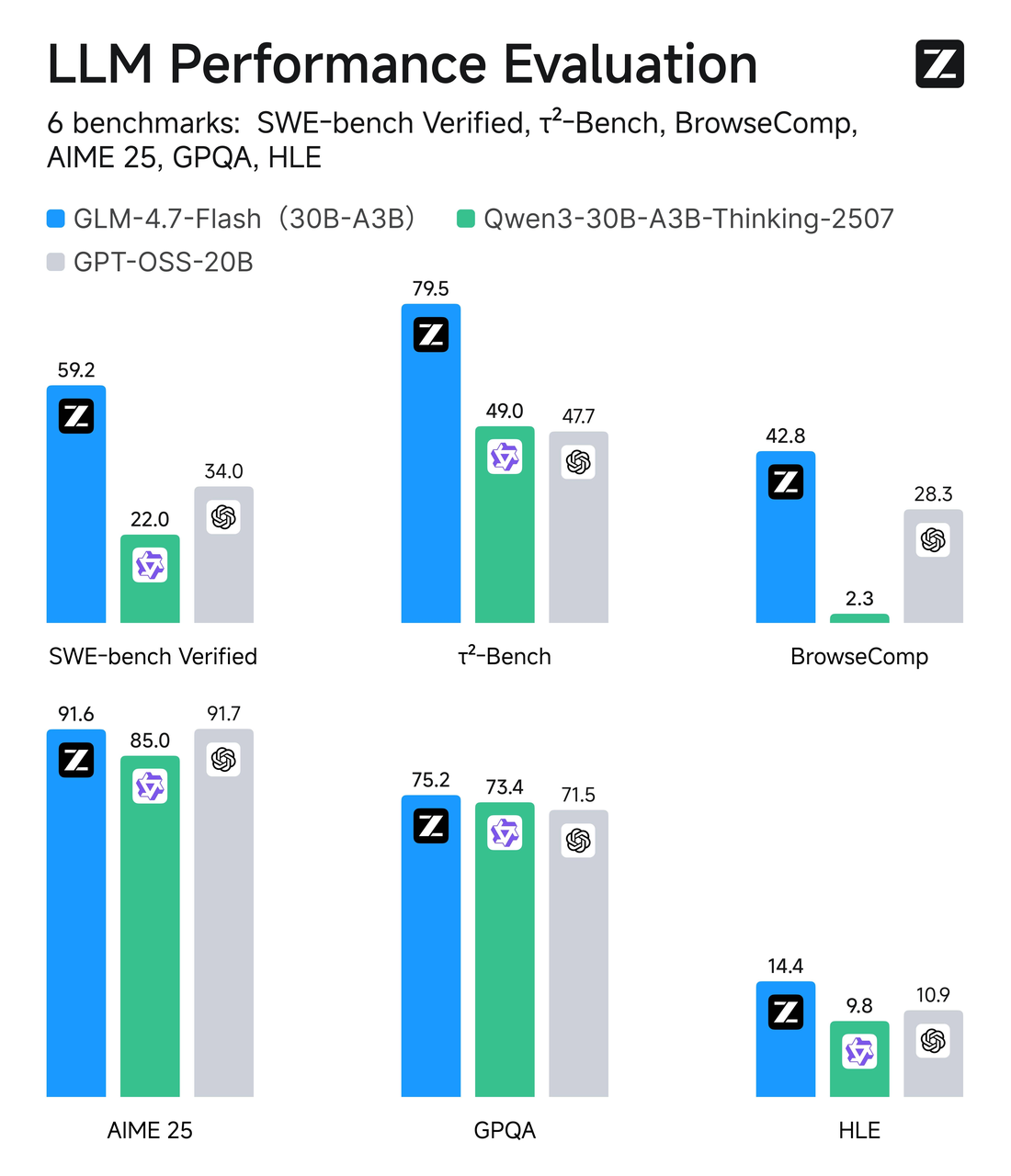 GLM-4.7-Flash использует архитектуру Mixture-of-Experts (MoE) с общим количеством параметров около 30B, но только ~3B экспертов активны на токен. Проще говоря: это широкая модель с выборочной маршрутизацией. Большую часть времени только небольшая часть сети работает над вашим токеном, что снижает нагрузку на вычисления.
GLM-4.7-Flash использует архитектуру Mixture-of-Experts (MoE) с общим количеством параметров около 30B, но только ~3B экспертов активны на токен. Проще говоря: это широкая модель с выборочной маршрутизацией. Большую часть времени только небольшая часть сети работает над вашим токеном, что снижает нагрузку на вычисления.
На практике MoE часто создаёт ощущение «большего мозга, когда нужно» без того, чтобы всегда платить полную цену вычислений. Во время моих тестов это привело к отзывчивому выводу даже под нагрузкой и более стабильной задержке, чем плотные модели аналогичного заявленного масштаба. Это не магия, просто умный способ сбалансировать возможности и скорость.
MLA (Multi-Headed Latent Attention)
В документах упоминается MLA (Multi-Headed Latent Attention). Мой вывод как пользователя: это стратегия внимания, нацеленная на большую эффективность, чем классическое полное самовнимание, особенно с более длинными контекстами. Я не давил на границы длинного контекста здесь: мои запуски были в основном под несколько тысяч токенов. Тем не менее, объём памяти оставался приемлемым, и я не видел обычного медленного снижения задержки, когда промпты росли от «коротких» к «средним».
Если вы планируете рабочие процессы, богатые извлечением информации, или циклы агентов, то MLA плюс MoE — это полезный сигнал: эта модель разработана, чтобы поддерживать пропускную способность, а не гнаться за максимальной глубиной рассуждения в одном ходу.
Бесплатный API — что включено
Бесплатный доступ выделялся. Я здесь осторожен, потому что бесплатные уровни меняются, иногда еженедельно. То, что я делюсь, — это то, что я наблюдал 20-21 января 2026, и то, что предполагала документация Zhipu при запуске. Всегда проверяйте ограничения дважды, прежде чем внедрять это в продакшене.
 Вкратце: бесплатный API позволил мне делать реальные запросы с разумными настройками по умолчанию. Я запускал небольшие задачи без попадания на платную стену посередине теста. Это снизило трение при попытке использовать это в живом скрипте вместо площадки.
Вкратце: бесплатный API позволил мне делать реальные запросы с разумными настройками по умолчанию. Я запускал небольшие задачи без попадания на платную стену посередине теста. Это снизило трение при попытке использовать это в живом скрипте вместо площадки.
Ограничения скорости и одновременность
Что я видел:
- Одновременность: я мог комфортно запускать несколько параллельных запросов от небольшого рабочего процесса без ошибок. В моих тестах 5–10 одновременных вызовов были стабильны. Когда я превышал этот уровень, я начинал видеть дроссельирование, что ожидаемо на бесплатном уровне.
- Пропускная способность: короткие промпты (классификация, малые преобразования) возвращались в диапазоне от менее секунды до нескольких секунд. В среднем я видел 300–900 мс для очень коротких ответов и 1,5–3 с для скромных выводов. Сетевые колебания применимы.
- Безопасность: API ответил ясными кодами ошибок, когда я превысил ограничения. Это само по себе сэкономило мне время, мне не пришлось угадывать, что пошло не так.
Я не гнался за точными потолками TPS: моя цель была посмотреть, смогут ли небольшие конвейеры работать без опеки. Смогли. Чувствует себя как свобода, честно говоря. Если вы планируете волнообразные рабочие нагрузки, тестируйте с реалистичной одновременностью и создавайте простые повторы/откаты. Бесплатные уровни щедрые, пока они щедрые.
Платный уровень FlashX
Zhipu упоминает опцию FlashX, ориентированную на более высокую пропускную способность и более предсказуемую производительность. Я не перемещал свои тесты на FlashX во время этого запуска, но вот что обычно меняется при обновлении уровней у поставщиков, подобных этому:
- Более высокие и гарантированные ограничения скорости с меньшей дроссельной способностью.
- Больше одновременных запросов на ключ, полезно для пакетных заданий и помощников, ориентированных на пользователя.
- Приоритетная маршрутизация (более низкая задержка хвоста). Это имеет значение, когда вас волнует худшие 5% запросов, а не только медиана.
Если вы выпускаете функцию, ориентированную на клиента, FlashX — более безопасный маршрут. Если вы экспериментируете, бесплатный уровень достаточно хорош, чтобы получить представление о стабильности и интеграционной работе. Ваш опыт будет зависеть от вашего бюджета задержки и того, как часто вы пакетируете.
Лучшие варианты использования
Я попробовал несколько реальных задач. Ничего праздничного, просто то, что появляется в моей неделе.
- Помощники интерфейса, где задержка убивает настроение. Думайте: встроенные переписи, небольшие уточнения, короткие отсутствия. GLM-4.7-Flash сохранял пользовательский интерфейс немедленным.
- Пакетные текстовые преобразования. Я запускал небольшой CSV (пара тысяч строк) для корректировки тона и тегов категорий. Модель оставалась стабильной и не дрейфовала на полпути.
- Черновики лесов. Контуры, расширения точка за точкой, простые брифы. Она хорошо справлялась со структурой, когда я давал ей чёткие инструкции. Как иметь мини-помощника, которого не нужно подкупать.
- Сводки извлечения с короткими окнами контекста. Когда я вводил 2–4 фрагмента, она отвечала чисто, не галлюцинируя странные мосты. С длинным, беспорядочным контекстом она старалась помочь, но иногда сжимала слишком агрессивно.
- Комментарии кода или строки документации «первого прохода». Не глубокие рефакторинги. Просто уточнение намерения и наименования, быстро и полезно.
Где я бы это не использовал:
- Многошаговый анализ с граничными случаями, где точность важнее скорости. Я бы выбрал модель тяжелого рассуждения.
- Долгоформатная генерация, где нужна стабильная тональность и глубокое фактическое связывание на тысячи токенов. Flash может это сделать, но это кажется не характерным для неё.
Почему это важно: быстрые модели, которые не разоряют ваш бюджет, открывают функции, которые вы иначе вырезали бы. Если ваше приложение требует десятков крошечных вызовов моделей за сеанс, сокращение задержки и более низкие вычисления на вызов складываются. Маленькие победы, большой выигрыш.
💡 Чтобы облегчить и сделать более надёжным запуск моделей, подобных GLM-4.7-Flash, в реальных рабочих процессах, я использую WaveSpeed — нашу собственную платформу, которая гладко обрабатывает запросы API, одновременность и пакетные задачи, поэтому вы можете сосредоточиться на результатах вместо опеки над скриптами.
Попробуйте WaveSpeed →
 Одна маленькая заметка с передней линии: мой первый час не был быстрее. Я возился со структурой промпта, температурой и максимальным числом токенов. После нескольких запусков я нашёл закономерность, короткий системный промпт, явный формат вывода, чёткие ограничения. Это снизило как время, так и умственные усилия. Это была не магия: это была подготовка.
Одна маленькая заметка с передней линии: мой первый час не был быстрее. Я возился со структурой промпта, температурой и максимальным числом токенов. После нескольких запусков я нашёл закономерность, короткий системный промпт, явный формат вывода, чёткие ограничения. Это снизило как время, так и умственные усилия. Это была не магия: это была подготовка.
Кто ещё начинал «быстрый 10-минутный тест» GLM-4.7-Flash (или любой Flash модели) и моргал, чтобы обнаружить, что часы показывают полночь? Поделитесь своим личным рекордом — и одним твиком промпта, который наконец заставил её вести себя — в комментариях.
Похожие статьи

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
