Что такое Z-Image-Turbo? Объяснение ультра-быстрой модели Text-to-Image с 6B параметрами

Привет, ребята. Я Дора. На днях я столкнулась с Z-Image-Turbo после небольшой заминки: мне нужен был чистый, разборчивый текст внутри изображения, а моя обычная установка постоянно выдавала корявые буквы. Не совсем непригодные, но всегда немного не так, как вывеска, написанная в спешке. Я постоянно читала заметки о модели, которая нативно работает с текстом и запускается на 16 ГБ видеопамяти без проблем. Так что на прошлой неделе (февраль 2026) я попробовала Z-Image-Turbo как на собственной машине, так и через API. Вкратце: она быстрая, практичная и не пытается быть чем-то потрясающим. Такое сочетание привлекло моё внимание.
Что такое Z-Image-Turbo?
 Z-Image-Turbo — это открытая модель генерации изображений с 6 млрд параметров, разработанная для быстрой итерации и надёжного рендеринга текста. Она нацелена на золотую середину, в которой нуждается большинство из нас: достаточно хорошая визуализация, надёжная типография и установка, которая не требует полной рабочей станции. Она поддерживает двуязычные подсказки (английский и китайский) и настроена на короткие графики сэмплирования, что позволяет ей держать низкую задержку.
Z-Image-Turbo — это открытая модель генерации изображений с 6 млрд параметров, разработанная для быстрой итерации и надёжного рендеринга текста. Она нацелена на золотую середину, в которой нуждается большинство из нас: достаточно хорошая визуализация, надёжная типография и установка, которая не требует полной рабочей станции. Она поддерживает двуязычные подсказки (английский и китайский) и настроена на короткие графики сэмплирования, что позволяет ей держать низкую задержку.
Я тестировала её как локально, так и через размещённую конечную точку. Локально она запускалась на 16 ГБ видеопамяти без перемещения между устройствами. Через API я могла генерировать отдельные изображения с постоянной скоростью за изображение, не беспокоясь о настройке пакетной обработки. Она не пытается переплюнуть самые кинематографичные модели: она пытается дать вам качественное изображение с разборчивыми словами, быстро.
Архитектура с 6 млрд параметрами
Я не выбираю модели по количеству параметров, но это объясняет некоторые особенности поведения. При 6 млрд Z-Image-Turbo кажется намеренно ограниченной: легче, чем гигантские варианты диффузии, но тяжелее, чем самые маленькие мобильные модели. На практике это означало для меня два вещи. Во-первых, память оставалась предсказуемой, никакого неожиданного исчерпания памяти, когда я увеличивал разрешение. Во-вторых, подсказки реагировали последовательно. Мне не пришлось чрезмерно инженерить руководство, чтобы сохранить типографию нетронутой.
Деталь архитектуры, которая имела наибольшее значение: модель обучена рассматривать текст в изображении как первоклассную цель, а не счастливую случайность. Вы можете это увидеть, когда просите вывески, макеты пользовательского интерфейса или снимки продуктов с метками. Буквы не расплываются, как только вы добавляете стиль. Они не идеальны, но достаточно стабильны, чтобы я перестала присматривать за подсказкой.
8-шаговое сэмплирование, почему это так быстро
 Большинство моих генераций укладывались в 6–10 шагов, при 8 шагах по умолчанию. Вот где проявляется скорость. Графики с низким количеством шагов часто разваливаются на деталях, но здесь выходы сохраняли форму, и текст оставался разборчивым чаще, чем нет. На моей ноутбучной видеопамяти 16 ГБ изображения размером 512×512 обычно завершались за пару секунд: на размещённом API задержка оставалась быстрой даже при слабой параллельной обработке.
Большинство моих генераций укладывались в 6–10 шагов, при 8 шагах по умолчанию. Вот где проявляется скорость. Графики с низким количеством шагов часто разваливаются на деталях, но здесь выходы сохраняли форму, и текст оставался разборчивым чаще, чем нет. На моей ноутбучной видеопамяти 16 ГБ изображения размером 512×512 обычно завершались за пару секунд: на размещённом API задержка оставалась быстрой даже при слабой параллельной обработке.
Это не сэкономило мне время с самого начала, я всё ещё возилась с формулировкой подсказок. Но после нескольких запусков я заметила, что умственная нагрузка снизилась. Меньше повторов. Меньше импульсов «ещё один сид». Если вы работаете в коротких циклах (набросок → корректировка → отправка), короткое количество шагов быстро складывается.
Ключевые функции, которые имеют значение
Я стараюсь избегать списков функций, но несколько выборов здесь сформировали, как я использовала модель.
Поддержка двуязычных подсказок (EN/ZH)
Я тестировала английские и простые китайские подсказки рядом: надписи, вывески, короткие подписи. Модель обрабатывала обе без каких-либо переключений в настройках. Что выделялось, так это то, что намерение подсказки переносилось между языками. Когда я просила «чистую доску меню с тремя секциями» на китайском, я получала ту же структуру, что и при английской подсказке, а не свободную переинтерпретацию. Если вы работаете в разных командах или на разных рынках, это снижает трение, без дополнительной настройки, без языковых хаков.
Ограничения: смешанные языковые подсказки внутри одного изображения иногда смещались в сторону одного языка для рендеринга текста. Я могла управлять этим явными инструкциями (например, «заголовок на EN, подзаголовок на ZH»), но это не совершенно. Тем не менее, для двуязычных рабочих процессов это один из более простых опытов, который у меня был.
Нативный рендеринг текста в изображениях
 Это причина, по которой я осталась. Текст выглядит как текст в большинстве случаев, прямые базовые линии, узнаваемые шрифты и символы, которые переживают лёгкие изменения стиля. Я бросала ей типичные случаи отказа: изогнутые вывески, маленькие нижние колонтитулы, поддельные метки пользовательского интерфейса. Она держалась лучше, чем обычные открытые модели, которые я использую, особенно при скромных размерах. Не типография для обложки журнала, но достаточно хорошо, чтобы я перестала маскировать и компилировать каждый раз.
Это причина, по которой я осталась. Текст выглядит как текст в большинстве случаев, прямые базовые линии, узнаваемые шрифты и символы, которые переживают лёгкие изменения стиля. Я бросала ей типичные случаи отказа: изогнутые вывески, маленькие нижние колонтитулы, поддельные метки пользовательского интерфейса. Она держалась лучше, чем обычные открытые модели, которые я использую, особенно при скромных размерах. Не типография для обложки журнала, но достаточно хорошо, чтобы я перестала маскировать и компилировать каждый раз.
Маленькая практическая заметка: короткие, точные текстовые подсказки работали лучше всего. Длинные абзацы всё ещё размываются. Если вы разрабатываете большой объём текста в изображение, вам, вероятно, все ещё понадобится инструмент макета. Но для логотипов, тегов, баннеров и простых макетов пользовательского интерфейса Z-Image-Turbo сделала путь «просто отрисуй это здесь» жизнеспособным.
Совместимость с 16 ГБ видеопамяти
Я запустила это на 16 ГБ видеопамяти без шардирования или полдня копания в зависимостях. Изображения размером 768 пикселей квадратом работали: 1024 пиксела требовали немного больше терпения и правильных настроек точности, но всё ещё было хорошо. Для меня это важнее, чем красивая демонстрация. Если модель хорошо ведёт себя на видеопамяти обычного ноутбука, я могу держать её в своём повседневном цикле вместо спиннинга отдельной установки.
Если у вас есть 8–12 ГБ, вам может потребоваться уменьшить разрешение или положиться на API. Если у вас есть 24 ГБ+, вы получите больше места для больших форматов, но основная ценность модели — быстрые, стабильные результаты с текстом — проявляется даже при меньших размерах.
Производительность тестов
Тесты — это не работа, но они помогают проверить впечатления.
№1 открытым исходным кодом в рейтинге Artificial Analysis
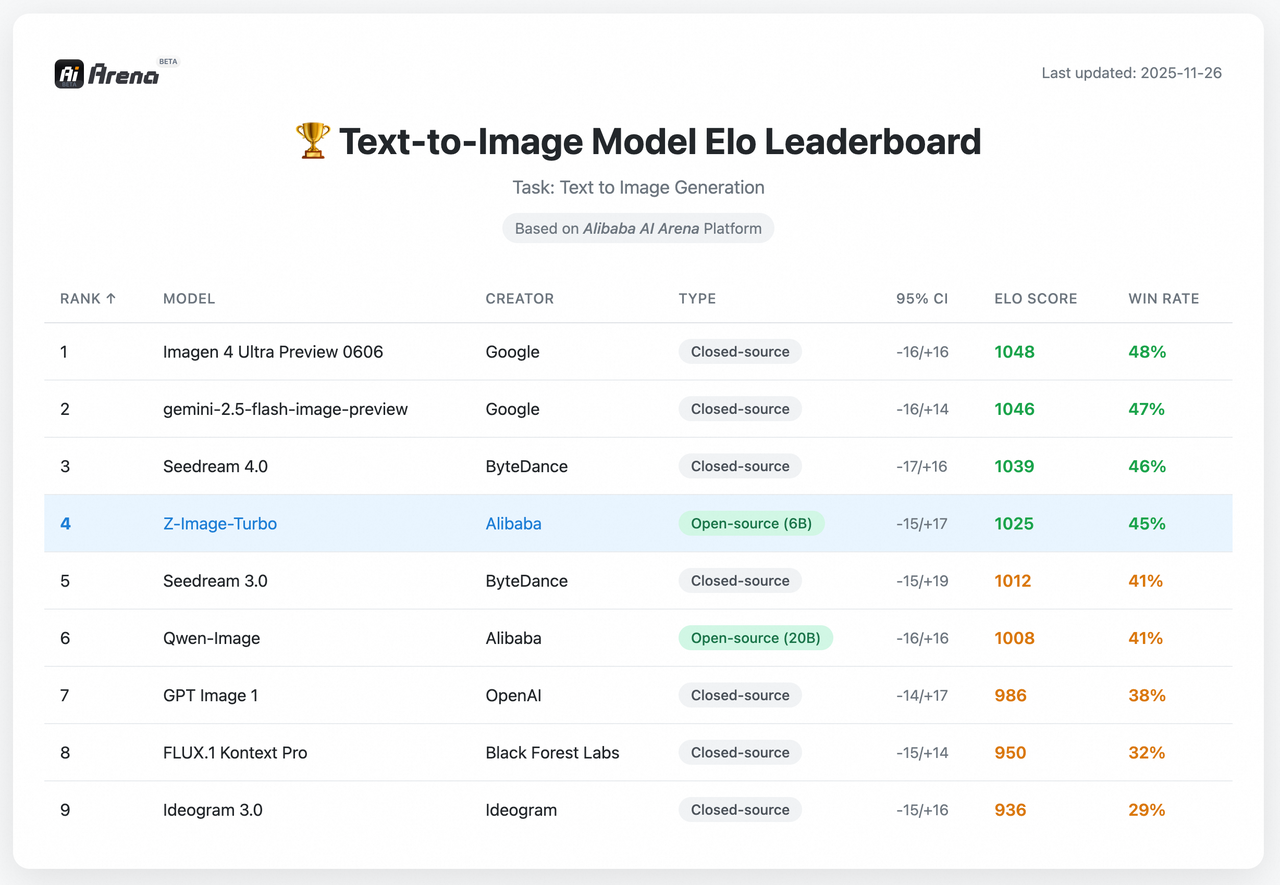 По состоянию на начало февраля 2026 года Z-Image-Turbo указана на вершине или рядом с ней среди открытых моделей изображений в рейтинге Artificial Analysis (рейтинги меняются, поэтому относитесь к этому как к снимку). Это соответствует тому, что я чувствовала: скорость и верность текста кажутся её сильными сторонами. Рейтинги не измеряют всё, но они полезны как прокси для того, как модель обобщает за пределами curated демонстрации.
По состоянию на начало февраля 2026 года Z-Image-Turbo указана на вершине или рядом с ней среди открытых моделей изображений в рейтинге Artificial Analysis (рейтинги меняются, поэтому относитесь к этому как к снимку). Это соответствует тому, что я чувствовала: скорость и верность текста кажутся её сильными сторонами. Рейтинги не измеряют всё, но они полезны как прокси для того, как модель обобщает за пределами curated демонстрации.
Как это сравнивается с закрытыми моделями
Против больших размещённых моделей Z-Image-Turbo торгует пиковым фотореализмом ради скорости, стоимости и контролируемого текста. Если вы хотите глянцевых, кинематографичных сцен со сложным освещением, некоторые закрытые варианты всё ещё это превосходят. Если вы хотите чистую графику с разборчивыми словами за две минуты, эта держит свою позицию. Я также заметила, что требуется меньше манипуляций с подсказками, чтобы сохранить типографию нетронутой, меньше испытаний, больше результатов. Для небольших команд или одиночных создателей это обычно разница между «хорошим экспериментом» и «это отправляется сегодня».
Кто должен использовать Z-Image-Turbo?
Идеальные варианты использования
- Социальная графика с коротким, разборчивым текстом (объявления, баннеры, миниатюры)
- Макеты продуктов и простые сцены пользовательского интерфейса, где метки должны выжить
- Внутренние документы и слайды, которые выигрывают от быстрой визуализации без обхода дизайна
- Двуязычные активы, где гибкость языка подсказок экономит туда-сюда
- Быстрая итерация в спринтах, когда вы хотите 3–5 приличных вариантов быстро и двигаться дальше
В моих тестах выигрыш был не только в сырой скорости. Это была предсказуемость. Я могла отрегулировать стиль или макет без полной потери текста, что означало меньше перезапусков.
Когда выбрать другие модели вместо этой
- Высокопроизводительный фотореализм для крупноформатной печати или объявлений, некоторые закрытые модели по-прежнему обеспечивают более отполированный результат.
- Длинные абзацы или сложные типографические системы, используйте инструмент макета или постобработку.
- Тяжёлая компилирование или многоизображальная согласованность (один и тот же персонаж в разных сценах), вам понадобится модель с сильной идентичностью и многокадровыми элементами управления.
Если ваша работа ориентирована на кинематографичные рассказы или исследования замысловатого освещения, вы можете предпочесть другой инструмент. Z-Image-Turbo больше похожа на ежедневный водитель, чем на выставочный автомобиль.
Как начать
Быстрый старт WaveSpeed API
Я сначала попробовала WaveSpeed API, чтобы избежать дрейфа установки. Аутентификация была стандартной, и тело запроса было простым: подсказка, шаги (я придерживалась 8), размер и сид, если вам нужна воспроизводимость. Значения по умолчанию были разумными. Если вы тестируете рендеринг текста, начните с коротких фраз и среднего разрешения, затем увеличивайте, как только вам понравится внешний вид. Я прошла от идеи к первому пригодному изображению менее чем за пять минут, самая быстрая часть этого всего эксперимента.
Если вы предпочитаете локально, модель чисто запускалась на 16 ГБ видеопамяти с типичными настройками точности. Следите за видеопамятью, когда вы пересекаете 768 пикселей. Если вы столкнулись с ограничениями, уменьшите шаги перед тем, как уменьшить руководство: 8-шаговое сэмплирование — это суть.
Обзор цен ($0,005/изображение)
 Через WaveSpeed цены составили около 0,005 долл. США за изображение при стандартных настройках. Это сложно критиковать за черновики, социальные активы или быстрые эксперименты. Если вы генерируете в масштабе, следите за ограничениями параллелизма, задержка для меня оставалась низкой при небольших всплесках, но я не стресс-тестировала за пределами нескольких параллельных заданий.
Через WaveSpeed цены составили около 0,005 долл. США за изображение при стандартных настройках. Это сложно критиковать за черновики, социальные активы или быстрые эксперименты. Если вы генерируете в масштабе, следите за ограничениями параллелизма, задержка для меня оставалась низкой при небольших всплесках, но я не стресс-тестировала за пределами нескольких параллельных заданий.
Это сработало для меня, ваш опыт может быть другим. Если вы жонглируете двуязычными подсказками или просто хотите текст, который выглядит так, как будто он принадлежит изображению, это стоит посмотреть. Последнее, что я заметила, почти случайно: я перестала делать скриншоты и редактировать снова и снова. Меньше обходных путей. Это казалось целью.
Похожие статьи

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
