Установка LTX-2 в ComfyUI на Windows: руководство по настройке CUDA и первому запуску

Привет, я Дора. В тот день я просто хотела быстро сделать проход text-to-video для скетча, и я постоянно видела упоминания LTX-2 в ветках ComfyUI. К середине утра я стояла перед пустым графом и папкой с названием “ltx” и задавалась вопросом, не подписалась ли я снова на русскую рулетку драйверов.
Я делала заметки, пока настраивала это на Windows 11. Если вы ищете “ltx-2 comfyui windows” потому что находитесь в процессе установки, я была в такой же ситуации. Вот что помогло.
Чек-лист перед установкой (GPU / CUDA / версии драйверов)
Быстрая проверка перед началом сэкономит час, который вы потратите на отладку ошибок DLL позже:
- GPU: видеокарта NVIDIA с минимум 12 ГБ VRAM сделала LTX-2 приемлемым для меня при скромных настройках (512–768 ширина, короткие клипы). 8 ГБ может работать с очень консервативными настройками, но это тесно и часто разочаровывает.
- Драйверы: обновитесь до свежего Game Ready или Studio драйвера (я использовала 552.xx).
- CUDA: вы не устанавливаете полный CUDA toolkit для ComfyUI portable. Вам нужны только runtime DLL, которые поставляются с PyTorch. Вот почему важно совпадение PyTorch+CUDA сборки (cu121 или cu122 и т.д.).
- Python: комплектная сборка ComfyUI поставляется с собственным Python. Если вы используете пользовательский venv, держите его согласованным с выбранным вами колесом PyTorch.
- VC++ Redistributable: установите/отремонтируйте последний Microsoft Visual C++ Redistributable. Это тихое решение для ошибок DLL типа “procedure entry point”.
Два теста на здравый смысл, которые я делаю перед любой тяжелой моделью:
nvidia-smiзапускается в терминале и чисто показывает драйвер.python -c "import torch: print(torch.version, torch.cuda.is_available())"возвращает True для CUDA в той среде, которая будет использоваться ComfyUI.
Ничто из этого не гарантирует гладкую работу, но это сужает возможные режимы отказа.
Обновите ComfyUI до версии, готовой к LTX-2
Что я делала:
- Сначала обновите ComfyUI. Если вы работаете с комплектной сборкой с GitHub, возьмите последний релиз или выполните git pull и запустите скрипты обновления.
- Откройте ComfyUI Manager (если вы его используете) и обновите основные зависимости. Я позволила Manager пересоздать venv, когда было предложено.
- Установите пакет узлов LTX-2 из его официального репозитория. Название варьируется (я видела репозитории стиля “ComfyUI-LTXVideo”/“LTX-Video”): я использовала тот, который связан со страницы официальной модели. Если описание репозитория говорит, что он поддерживает LTX-Video v2/LTX-2, это то, что вам нужно.
Почему это важно на практике:
- LTX-2 опирается на функции PyTorch 2.3+ и сборки CUDA 12.x. Смешивание старого torch (cu118) с новыми узлами — это быстрый способ попасть на криптические ошибки импорта.
- Некоторые пакеты по-разному выставляют переключатели FP8/BF16. Совпадение пакета узлов и версии ComfyUI избегает неправильных входов и тупиковых графов.
Я сначала сопротивлялась свежей установке, она казалась ненужной. Потом я сравнила: новая сборка стартовала с первой попытки; старая всё ещё просила отсутствующие операции. Я не скучала по предположениям.
Размещение файлов модели (пошагово)
Здесь я обычно теряю время. Разные узлы ожидают разные папки. Вот что сработало для меня с установленным пакетом узлов LTX-2, и общий паттерн сохраняется, даже если названия ваших папок отличаются.
-
Найдите ожидаемые пути узла.
В ComfyUI откройте узел загрузки LTX и наведитесь на любой ввод файла. Большинство пакетов показывают относительный путь, который они сканируют (например,models/ltx,models/checkpoints, или пользовательскую подпапку вродеmodels/ltx_video).
Если в сомнениях, проверьте README репозитория. Они обычно перечисляют точный каталог. -
Загрузите веса LTX-2 из официального источника (часто Hugging Face, связано со страницы модели).
Вы обычно получите основной файл.safetensorsили.pthплюс конфиги. Некоторые репозитории разделяют текстовые энкодеры/VAE отдельно; другие объединяют их. -
Поместите файлы точно туда, где узел их ищет.
Для моего пакета:ComfyUI/models/ltx_video/содержал основной файл модели. Если ваш пакет говоритmodels/checkpoints, используйте вместо этого. Название должно появиться в раскрывающемся списке узла после перезагрузки или пересканирования. -
Опционально: текстовый энкодер / VAE.
Если узел выставляет отдельные входы для энкодеров или VAE, следуйте его рекомендациям. Многие узлы LTX-2 скрывают это и объединяют компоненты внутри. Если это выставлено, поместите файлы CLIP/Tokenizer вmodels/clipилиmodels/text_encodersсогласно инструкциям README. -
Перезагрузите ComfyUI.
Я знаю, это очевидно. Но горячая перезагрузка не всегда пересканирует эти папки, и я смотрела на пустой раскрывающийся список больше раз, чем хочу признать.
Маленькое замечание: если Windows отмечает загруженные файлы как заблокированные (правый клик > Свойства > Разблокировать), очистите это. У меня Python отказывался трогать файлы “загруженные с интернета” в более строгих установках.
Типичные ошибки Windows (DLL / разрешения)
“DLL load failed while importing …” или отсутствует nvrtc64_X.dll
- Причина: сборка PyTorch не совпадала с CUDA runtime, ожидаемым пакетом узлов, или среда смешивала cu118 и cu12x.
- Решение: переустановите/подтвердите PyTorch 2.3+ с cu121/cu122 внутри окружения ComfyUI. Если вы используете portable, позвольте Manager справиться с этим. Обновление драйверов NVIDIA помогло однажды.
 “Access is denied” при записи кадров/видео
“Access is denied” при записи кадров/видео - Причина: я указала узел SaveVideo на синхронизированную папку с агрессивными разрешениями (OneDrive).
- Решение: сначала пишите на локальный не синхронизируемый путь (например,
ComfyUI/output/ltx_test). Переместите файл позже.
Проблемы с длинными путями при распаковке
- Причина: ограничения длины пути Windows плюс глубокие подпапки ComfyUI.
- Решение: включите длинные пути в Windows (Local Group Policy или реестр) или распакуйте ближе к
C:\.
Антивирус сканирует временные кадры во время рендера
- Симптом: зависание или заикание ComfyUI во время кодирования.
- Решение: добавьте исключение для папки ComfyUI или просто пути вывода временных файлов.
“Could not find model” хотя папка правильная
- Решение: перезагрузите ComfyUI. Если всё ещё не показывается, проверьте точную ожидаемую папку узла. Некоторые узлы LTX-2 ищут в пользовательском имени каталога. Совпадите с ним точно.
Я также столкнулась с классической ситуацией “работает один раз, следующий раз падает”. Для меня это свелось к тому, что вкладка браузера пыталась предпросмотреть частичный MP4, пока узел кодирования ещё писал. Я переключилась на запись в новое имя файла за каждый запуск. Нестабильность исчезла.
Первый тестовый рабочий процесс вывода
Я держала первый граф маленьким. Ничего умного, просто достаточно, чтобы подтвердить конвейер.
Что я построила:
- Узел Prompt с одним предложением (10–20 токенов). Держите это просто.
- Узел загрузки LTX-2 указывающий на загруженную модель.
- Узел LTX-2 Sampler/Scheduler (как его называет ваш пакет) с низким количеством шагов.
- Путь декодирования/сборки видео, который записывает кадры в узел SaveVideo (MP4, H.264 хороший для быстрой проверки).
Параметры, которые со мной не боролись:
- Разрешение: 512×288 или 640×360
- Кадры: 8–16 кадров (0.5–1 секунда)
- Шаги: 6–12
- Guidance/CFG: золотая середина (5–7)
- Seed: фиксированный номер (делает отладку менее шумной)
- Точность: FP16 (по умолчанию) если ваш узел не предлагает BF16 на Ada: оба работали для меня, FP16 использовал меньше VRAM
На что я смотрю при первом запуске:
- Скачки VRAM в
nvidia-smi. Если вы сразу прижаты к 99% VRAM, уменьшите разрешение или кадры. - Время до первого кадра. Мой первый чистый запуск был ~25–40 секунд для 16 кадров на 512×288 на 4070, steps=8. Что-то намного более долгое обычно указывало на кодирование CPU или узкое место I/O.
Если ваш рендер завершается, но видео пусто или повреждено, попробуйте:
- Сначала записать PNG кадры, потом позвольте отдельному узлу или внешнему инструменту собрать видео.
- Переключиться на другой кодировщик (H.264 vs H.265) или значение CRF.
Полезная часть была не скорость, это было видеть один связный клип. Вот момент, когда я расслабляюсь. Потом я осторожно масштабирую.
Настройка производительности (batch / точность)
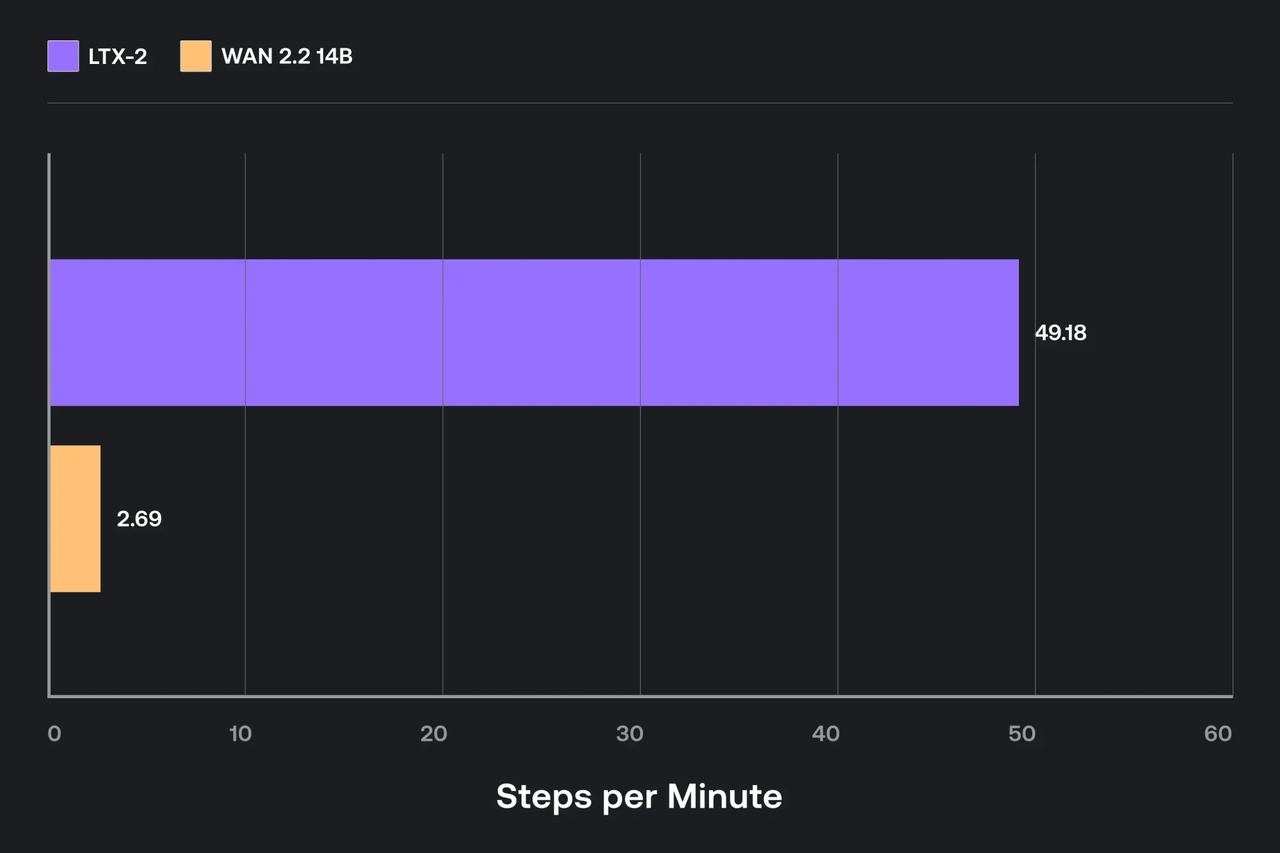 Я не гонялась за славой в бенчмарках. Я просто хотела настройки, которые не позволяли мне нянчиться с памятью.
Я не гонялась за славой в бенчмарках. Я просто хотела настройки, которые не позволяли мне нянчиться с памятью.
Что дало результат:
- Кадры перед шириной. Было проще для VRAM держать 12–16 кадров и увеличить ширину до 640, чем прыгать на 24+ кадра. Более длинные клипы быстро растут в памяти.
- Точность: FP16 работала лучше всего на моей 4070. BF16 тоже работала, но использовала немного больше памяти. Я не получила видимого качества от BF16 при этих размерах.
- Backend внимания: если ваш пакет выставляет переключатель для
scaled_dot_product_attention(PyTorch native) vs xFormers, сначала попробуйте native на недавнем PyTorch. Для меня это было более стабильно на Windows. - Размер батча: держите его на 1 для видео. Мини-батчи в основном наказывали VRAM без экономии стенных часов на моей установке.
- Torch compile: стоит тестирования, но я видела только небольшие выигрыши для более длительных запусков. Для коротких тестов 8–16 кадров, время компиляции могло съесть сбережения.
- Смешанный IO: запись на быстрый локальный SSD имела большее значение, чем я ожидала. Медленные сетевые папки делали фазу кодирования похожей на проблему модели, когда это не было.
Простая лестница, которая не взорвала мою VRAM:
- 512×288, 12 кадров, steps=8
- 640×360, 16 кадров, steps=10
- 768×432, 16–24 кадра, steps=12–14
Если вы столкнулись с недостатком памяти:
- Сначала уменьшите кадры на 4, прежде чем снижать ширину.
- Сначала уменьшите шаги, если вам просто нужен черновик.
- Закройте другие GPU приложения (видеоплееры, браузер с аппаратным ускорением). Утомительно, но это работает.
Я также пробовала крошечный режим tile/patch, который предлагают некоторые пакеты. Это помогло при большей ширине, но иногда вводило швы. Хорошо для экспериментов: не мой по умолчанию.
Путь WaveSpeed (CUDA не требуется локально)
 Я протестировала один запуск через размещённый путь, чтобы избежать замешательства с GPU. Идея: позвольте ComfyUI общаться с удаленным рабочим процессом, который запускает LTX-2, так что ваш локальный ящик Windows просто обрабатывает UI графа.
Я протестировала один запуск через размещённый путь, чтобы избежать замешательства с GPU. Идея: позвольте ComfyUI общаться с удаленным рабочим процессом, который запускает LTX-2, так что ваш локальный ящик Windows просто обрабатывает UI графа.
Как это выглядело на практике:
- Установите соединитель/расширение в ComfyUI (тот, который я использовала, обозначила себя как “WaveSpeed” в списке Manager). После установки появился новый набор узлов для удаленного выполнения.
- Аутентифицируйтесь или укажите конечную точку рабочего процесса. Моя использовала ключ панели управления. Установка заняла несколько минут.
- Замените локальный загрузчик/семплер LTX-2 на эквиваленты WaveSpeed. Те же подсказки, та же форма графа, только другие узлы.
Пропустите головные боли при установке: протестируйте LTX-2 мгновенно на WaveSpeed — никакого локального GPU, никакого жонглирования драйверами, просто введите вашу подсказку и начните рендеринг.
Если вы любопытны, проверьте официальную документацию соединителя для текущих шагов установки. Я бы не перестраивала весь свой рабочий процесс вокруг этого, но как путь без CUDA, это было освежающе скучно, в хорошем смысле.
Похожие статьи

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
