DeepSeek V4 с контекстом в 1 млн токенов: как запрашивать целые кодовые базы

Let me translate the article directly:
Привет, друзья. Я Дора. В первый раз, когда я загрузила полный проект в окно из 1 млн токенов DeepSeek V4, я не почувствовала себя мощной. Я почувствовала осторожность. Миллион токенов звучит как бесконечный кофе, но тот, кто пробовал думать часами на кофеиновом уколе, знает, что край становится размытым. Я хотела посмотреть, действительно ли этот новый размер контекста изменит способ моей работы или просто будет побуждать меня вставлять больше.
Я потратила несколько дней (27–30 января 2026 г.) на использование DeepSeek V4 с 1M токенами для трёх задач, которые я часто встречаю:
- чтение среднего размера монорепозитория без локальной настройки,
- отслеживание ошибки через сервисы, которые слишком много общаются друг с другом,
- и запрос рекомендаций по рефакторингу, которые не испортят тесты.
Что я узнала: вы можете вместить многое, но модель по-прежнему нуждается в том, чтобы вы указали на карте. Выигрыши пришли не от добавления большего количества файлов: они пришли от того, как я структурировала подсказку и как я попросила модель двигаться через неё.
Что на самом деле означают 1M токенов
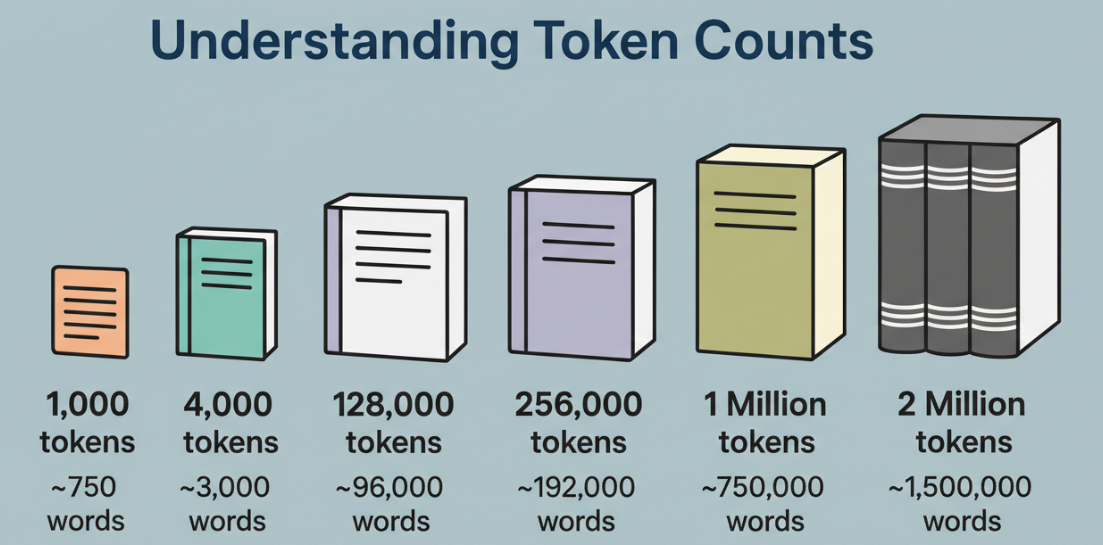 Мне не важно число само по себе. Мне важно то, что оно содержит с ясной головой.
Мне не важно число само по себе. Мне важно то, что оно содержит с ясной головой.
Токен — это не слово. Это кусок, иногда целое слово, иногда часть одного, иногда пунктуация. В английском тексте я обычно рассчитываю 1 токен как ~0,75 слова для грубого планирования. Для кода токены идут быстро: скобки, точки, названия методов, всё нарезано на части. Миллион токенов — это большая территория, но это не бесконечное внимание.
Что изменилось для меня на этой неделе: я перестала настолько агрессивно обрезать. При контекстах 128K я бы агрессивно резюмировала и оставляла только горячий путь. С 1M я могла оставить горячий путь плюс «холодные» файлы, которые обычно удивляют меня позже (конфигурация, миграции, сценарии сборки, рабочий процесс). При этом, если я всё это сразу выгружала, ответы становились расплывчатыми. Когда я кормила модель поэтапно, с чёткими указателями, результаты выглядели обоснованными.
Эквивалент в строках кода
Примерный расчёт, который я использовала при работе:
- Многие репозитории смешивают код и документацию. В папках, богатых кодом, я видела ~2–3 токена на символ в плотных языках, но практический ярлык: думайте ~4 токена на строку для простых строк, ~8–12 для реальных строк с отступом, именами и комментариями.
- В таком темпе 1M токенов содержит примерно 80K–150K строк кода, в зависимости от стиля и языка. Сервис TypeScript с комментариями и дружественными к linter именами находится в верхней части. Минифицированные пакеты взрывают счётчик и не стоят включения.
На практике мой «безопасный размер» был ~60K строк осмысленного исходного кода + целевая документация и тесты. Я могла бы пойти выше, но задержка увеличивалась и ответы размягчались. Ваш результат будет зависеть от правил токенизера и смеси языков.
vs Текущие модели (128K)
Переход с 128K на 1M кажется не похожим на большой рюкзак, а скорее на прихват тележки. Вы можете нести больше, но вы не будете бегать спринтом.
Что я заметила:
- Задержка: целые контекстные подсказки занимали заметно больше времени. Когда я разбила сессию (поэтапно), задержка казалась управляемой.
- Отзыв: при 128K модель часто «забывала» более ранние файлы, если я не повторяла ключевую часть. При 1M она не забывала, но иногда обобщала вместо цитирования конкретики. Мне лучше удавалось, когда я просила указать пути файлов и диапазоны строк, где это возможно.
- Точность: чем больше контекст, тем больше вам нужны индексирующие поведения в вашей подсказке. В противном случае вы получите компетентные резюме, которые избегают беспорядочных граничных случаев, о которых вы на самом деле заботитесь.
Если вы надеетесь, что 1M токенов означает «больше никакой инженерии подсказок», я бы не рассчитывала на это. Это смещает тип управления, которое вы делаете.
Структура подсказки для больших кодовых баз
 Я перестала думать о подсказке как о сообщении и начала относиться к ней как к плану чтения. Модель может много читать сейчас, но она всё еще выигрывает от оглавления и след.
Я перестала думать о подсказке как о сообщении и начала относиться к ней как к плану чтения. Модель может много читать сейчас, но она всё еще выигрывает от оглавления и след.
Что лучше всего мне дало, выглядело так: короткое системное обрамление, краткий индекс проекта, объявленный порядок изучения, затем конкретная задача. И затем я продолжила разговор раундами, а не одной мега-подсказкой.
Порядок файлов
Я получила более надёжные ответы, когда я сказала модели, что открывать сначала, второе, третье. Один список вверху помог ему построить психологический стек:
- Начните с точек входа (CLI, HTTP обработчики, задания). Это якорирует поток.
- Затем слой композиции (DI контейнер, main.ts, app.py), где подключаются зависимости.
- Далее, основные модули предметной области и их интерфейсы.
- Только потом: помощники, утилиты и сквозные части (логирование, телеметрия, конфигурация).
- Тесты в последнюю очередь, если я не отлаживаю конкретный сбой, в этом случае начните с падающей спецификации, чтобы установить ожидания.
Я также включила заметки «не читай» для папок, которые выглядят важно, но не являются: сгенерированный код, скомпилированные активы, снимки. Это сэкономило токены и сохранило внимание модели на живом коде.
Маленький трюк: я попросила модель вести прокручиваемый список «активных файлов» (пути и краткие резюме) и обновлять его по мере того, как мы двигались. Когда он дрейфовал, я могла вернуться к этому списку и сказать: «Пока оставайтесь в этом наборе». Это держало ответы конкретными.
Отображение зависимостей
Одним из наиболее полезных проходов было запрос отображения зависимостей в начале, не как диаграмма, а как простая таблица рёбер: модуль A импортирует B, B использует C, C попадает в переменные окружения, и так далее. Я держала это текстовым и кратким.
Что это сделало на практике:
- Это обнаружило блудные зависимости (тип, который кровоточит проблемами через папки).
- Это дало мне короткий список «точек давления» для проверки перед любым рефакторингом.
- Это помогло модели ссылаться на правильное место, когда я просила изменения.
Я также заставила модель высказать предположения, то, что она вывела из именования, комментариев или тестов. Когда предположение было неправильным, я исправляла его один раз, и последующие шаги оставались чище.
Одно предупреждение: запрос полного отображения зависимостей на большом репо за один раз привёл к истечению времени и расплывчатым графикам. У меня были лучшие результаты при его области по слою (например, только доступ к данным, только обработчики HTTP) и затем объединения заметок самой. Это заняло дополнительные 10 минут, но окупилось в точности.
Стратегии разбиения при необходимости
 Даже с окном 1M токенов я всё равно разбивала. Не потому, что оно не смогло бы вместиться, а потому что моё мышление было лучше поэтапно, и модель отвечала более точно, когда я сужала его поле зрения.
Даже с окном 1M токенов я всё равно разбивала. Не потому, что оно не смогло бы вместиться, а потому что моё мышление было лучше поэтапно, и модель отвечала более точно, когда я сужала его поле зрения.
Несколько шаблонов, которые держались на этой неделе:
- Этап краткого описания: я начала с небольшого контекста, индекса проекта, задачи, известных ограничений, затем попросила план чтения и проверки. Только после этого я кормила код в порядке, который мы согласовали.
- Ограничьте активный набор: для рефакторинга я оставляла только 5–12 файлов в игре и просила изменения с явными путями. Если редактирование коснулось общей утилиты, я добавляла этот файл в следующий ход. Модель оставалась плотнее.
- Резюмируйте на краях: перед переходом в новую папку, я просила краткое резюме того, что мы узнали, и любых неясностей. Эти резюме действовали как хлебные крошки через ходы без переналадки каждого файла.
- Используйте поиск целенаправленно: для репо, которые не подходили комфортно, я использовала встраивания, чтобы вызвать файлы по запросу («нормализация платёжного ID», «отступ повтора»). Я держала полученный набор небольшим за ход, обычно под 40K токенов, поэтому ответы не размывались.
- Проверяйте вперёд, а не назад: вместо того, чтобы спрашивать: «Вы использовали всё, что я вставила?» я спросила: «Укажите конкретные функции и строки, на которые зависит ваше предложение». Это заставило конкретные ссылки и сделало ошибки очевидными.
Трение, которое я ударила:
- Задержка переходит, когда вы отправляете полные контекстные сообщения каждый ход. Постановка сократила мое среднее время отклика с 70–90s на 20–40s для тех же задач.
- Стоимость имеет значение. Большие подсказки складываются. Я сэкономила токены, обрезав комментарии, которые повторяли очевидное, удалив скомпилированные артефакты и пропустив пакеты поставщиков.
- Эффекты положения реальны. Контент в самом начале или конце гигантской подсказки, как правило, более «доступен». Я противодействовал этому, повторяя крошечные, критические ограничения рядом с концом каждого хода.
Кому полезно окно 1M?

- Если вы живёте в монорепозиториях, занимаетесь аудитами или делаете сквозные рефакторинги, это снижает количество этапов настройки и локальных расходов на индексирование. Это более спокойная отправная точка.
- Если ваша работа в основном ориентирована на исправление ошибок в небольших сервисах, дополнительная ёмкость не поможет много. Меньший контекст плюс плотный конвейер поиска будут казаться быстрее.
Заметка о доверии: я просила модель цитировать точные строки кода для рискованных изменений (миграции, аутентификация). Когда она колебалась или перефразировала, я относилась к этому как флаг для сужения области или вставки конкретного файла снова. Эта маленькая привычка предотвратила пару почти промахов.
Если вы хотите формальное описание пределов модели или поведение токенизера, проверьте документы поставщика. Когда мне нужны были конкретики, я вернулась к официальной карточке модели и примечаниям об окне контекста. Это держало меня честной относительно того, что я просила модель делать.
Это не магия. Это просто более большой стол. Полезно, если вы расставите стулья.
Я продолжаю думать об одной маленькой вещи со вторника: я попросила исправить, и модель предложила изменить функцию, которая выглядела правильно с первого взгляда. Это не было. Ошибка жила в помощнике двумя уровнями ниже. Миллион токенов не изменил это. Мои заметки сделали.
Похожие статьи

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
