O Que É TranslateGemma? Modelo de Tradução de IA Aberto Explicado

Olá, pessoal! Eu sou a Dora. Naquele dia, eu estava editando um boletim informativo bilíngue e continuava alternando entre rascunhos, capturas de tela e abas do Google Translate. Nada disso era terrível. Era só… barulhento. Sabe aquele tipo? Eu queria algo tranquilo que pudesse se integrar ao meu fluxo de trabalho, não ao lado dele.
Então no início desta semana (janeiro de 2026), testei o TranslateGemma. Não esperava muito a princípio, apenas outro modelo “aberto” com um nome brilhante. Mas depois de algumas execuções dentro de um notebook e então uma pequena ferramenta interna, notei algo sutil: a carga mental diminuiu. Eu não estava mexendo em abas. Não estava revisando a redação tanto quanto antes. Parecia um tradutor que eu pudesse manter na minha mesa, não do outro lado da sala.
O que é TranslateGemma
 TranslateGemma é uma família de modelos de tradução abertos construídos sobre a arquitetura Gemma do Google. Em termos simples: é um conjunto de modelos de linguagem sintonizados especificamente para tarefas de tradução, com tamanhos que você realmente pode executar localmente ou dimensionar na nuvem.
TranslateGemma é uma família de modelos de tradução abertos construídos sobre a arquitetura Gemma do Google. Em termos simples: é um conjunto de modelos de linguagem sintonizados especificamente para tarefas de tradução, com tamanhos que você realmente pode executar localmente ou dimensionar na nuvem.
Algumas coisas se destacaram enquanto eu estava realmente usando:
- É especificamente ajustado para tradução. Você não precisa forçar um LLM geral a se comportar. Os prompts permanecem simples.
- Ele lida melhor com contexto do que uma simples API de frase por frase. Parágrafos com idiomatismos, nomes de produtos e dicas de tom leve passaram com menos “pontos planos”.
- É tranquilo. A saída não é chamativa ou inclinada a parafrasear. Para documentos de trabalho, isso é um alívio.
No papel, TranslateGemma fica entre assistentes totalmente generativos e tradutores clássicos baseados em frases. Na prática, é um tradutor que respeita o significado da fonte enquanto ainda suaviza a língua de destino. Quando alimentei com uma breve nota de lançamento com uma mistura de rótulos de UI e linhas conversacionais, manteve os rótulos intactos e ainda fez a redação ler naturalmente. Esse equilíbrio é o que me fez continuar testando.
O licenciamento está na família Gemma: permissivo para muitos usos comerciais com restrições de IA responsável. Se você estiver incorporando em um produto, leia a licença no repositório oficial ou na entrada do Model Garden. É a parte chata, mas importa.
Tamanhos de Modelo: 4B, 12B e 27B
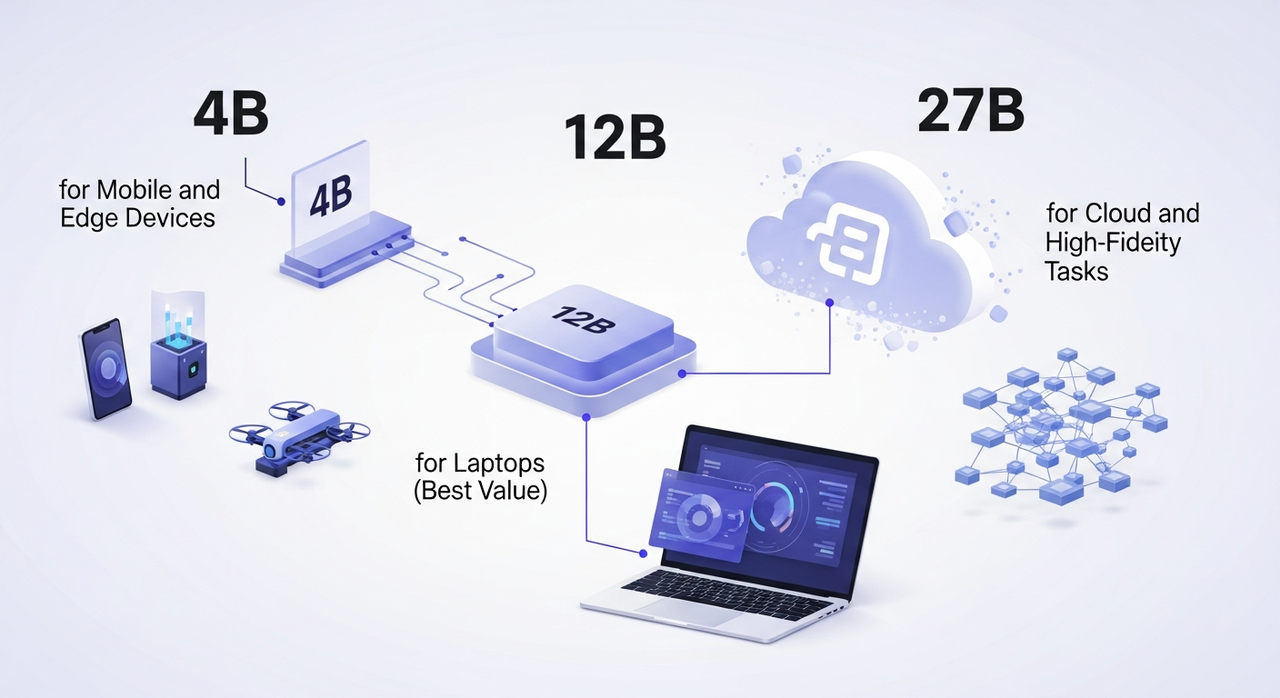 TranslateGemma vem em três tamanhos. Mesma família, diferentes compensações. Executei pequenos testes em cada um durante dois dias, algumas páginas de produtos, uma sequência de e-mail e um resumo de pesquisa em espanhol, francês e japonês.
TranslateGemma vem em três tamanhos. Mesma família, diferentes compensações. Executei pequenos testes em cada um durante dois dias, algumas páginas de produtos, uma sequência de e-mail e um resumo de pesquisa em espanhol, francês e japonês.
4B para Dispositivos Móveis e Edge
Testei um build 4B quantizado em 4 bits em um telefone Android recente e um Raspberry Pi 5 (só para ver). A latência no telefone era aceitável para frases curtas (menos de um segundo por linha), e os resultados eram limpos para cópia direta: strings de UI, texto de ajuda, legendas curtas. Qualquer coisa com tom em camadas ou cláusulas aninhadas começava a oscilar. Esse foi meu sinal para parar de forçar.
O que funcionou:
- Tradução em dispositivo de strings de aplicativo sem enviar dados para um servidor.
- Rascunhos rápidos para legendas de mídia social em um segundo idioma.
Limites que encontrei:
- Parágrafos mais longos acumulavam rigidez. Mantinha o significado, perdia a música.
- Texto code-mixed (EN + um segundo idioma) às vezes era excessivamente normalizado.
Se você precisa de tradução na borda, quiosques, aplicativos offline, fluxos de trabalho sensíveis à privacidade, 4B é o pequeno martelo que cabe no seu bolso. Para escrita cotidiana, eu o trataria como um primeiro rascunho, não o rascunho final.
12B para Laptops (Melhor Valor)
Este é o que eu continuava usando. No meu laptop (32GB RAM, GPU de consumidor), o modelo 12B em 4-8 bits funcionava confortavelmente com prompts em nível de parágrafo. Latência média: 1-2 segundos para algumas frases, talvez 5-8 segundos para um parágrafo denso. Isso está na faixa de “não interrompe o pensamento”.
A qualidade pareceu equilibrada: menos literal que 4B, menos ornamental que LLMs maiores que adoram parafrasear. Quando traduzi um pequeno estudo de caso do francês para o inglês, manteve a estrutura e refletiu a ênfase da sentença sem aglomerar tudo em um tom. Nomes, termos de produtos e citações permaneceram no lugar.
Onde se destaca:
- E-mails de marketing que precisam de tom, mas não de poesia.
- Documentação, notas de lançamento e cópia de UX onde clareza vence o floreio.
- Trabalhos em lote em um laptop: 50-200 parágrafos de cada vez sem uma conta de nuvem.
Onde ainda o ajusto:
- Linhas adjacentes à poesia (taglines, slogans) às vezes leem de forma segura. Uma passagem rápida corrige.
- Artigos altamente técnicos podem ficar literais. Adicionar “mantenha o registro acadêmico formal” no prompt ajudou.
27B para Nuvem e Tarefas de Alta Fidelidade
Girei o modelo 27B em um único A100 na nuvem. É a opção para equipes que se importam com nuance e podem justificar infraestrutura. A latência foi boa para uso interativo, mas obviamente não é amigável para dispositivos móveis.
O que notei:
- Mantinha dicas estilísticas em seções mais longas. Em texto legal de japonês para inglês, mantinha formalidade sem parecer artificial.
- Tratava melhor pronomes ambíguos. Menos referentes incompatíveis entre parágrafos.
- Para pares de linguagem de baixo recurso, não fazia milagres, mas falhava com mais graça, menos termos alucinados.
Para ser honesto, se você está traduzindo conteúdo de longa forma para publicação, ou precisa de consistência em milhares de segmentos, 27B vale a pena. Para pequenas equipes, eu só recorreria quando a fidelidade de tom é inegociável ou você precisa padronizar resultados em escala.
TranslateGemma vs Google Translate
 Não estou aqui para substituir o Google Translate com pressa. É rápido, está em todo lugar, e para pesquisas rápidas ainda é o caminho mais rápido de “o que isso significa?” para “entendi.” Mas as compensações são diferentes.
Não estou aqui para substituir o Google Translate com pressa. É rápido, está em todo lugar, e para pesquisas rápidas ainda é o caminho mais rápido de “o que isso significa?” para “entendi.” Mas as compensações são diferentes.
Onde TranslateGemma pareceu melhor nas minhas execuções:
- Janelas de contexto: Eu poderia descarregar um ou dois parágrafos inteiros e manter o tom e as referências intactos. O Google Translate geralmente acerta o significado, mas achata o estilo quando o contexto é confuso.
- Personalização: Uma instrução de uma linha como “preservar nomes de produtos, manter contrações” moldava confiável a saída. Com o Google Translate, você recebe o que recebe.
- Privacidade/controle: Executar localmente (4B/12B) ou em uma nuvem privada reduz a exposição de dados. Sem alternância de abas, sem chamadas externas se não quiser.
Onde o Google Translate ainda vence:
- Amplitude e conveniência: 100+ idiomas, acesso web instantâneo, OCR, entrada de câmera móvel. É a faca suíça.
- Velocidade em escala para uso casual: Se eu só preciso de uma frase rápida, TranslateGemma é excessivo a menos que já esteja integrado no meu editor.
- Colaboração sem atrito: É fácil enviar a alguém uma página do Google Translate e dizer “isso está perto?”
Em termos de custo, TranslateGemma desloca o gasto de taxas de API por solicitação para computação. Se você já tem uma GPU decente ou uma configuração de nuvem modesta, pode ser mais barato para uso sustentado. Se não tiver, a camada gratuita do Google Translate é difícil de questionar.
A qualidade é mais próxima do que eu esperava. TranslateGemma era menos literal de uma forma boa, modesto, não chamativo. O Google Translate melhorou o tratamento de tom, mas ainda lê como um dicionário que foi à escola de etiqueta. Se você escreve para pessoas, essa diferença importa.
Minha regra de ouro depois de uma semana: eu ainda recorro ao Google Translate para fazer uma verificação de sanidade de uma linha em um idioma que mal conheço. Eu recorro ao TranslateGemma quando me importo com como soa, não apenas com o que diz.
Uma vez que decidi que TranslateGemma era o ajuste certo, a próxima pergunta era onde realmente executá-lo sem transformar a configuração em um projeto em si.
É exatamente por isso que construímos WaveSpeed. Nosso time o usa para ativar ambientes de GPU limpos, executar trabalhos de tradução em lote e seguir em frente — sem cuidar de drivers, filas ou scripts temporários.
Onde Obter TranslateGemma
Puxei modelos dos locais usuais:
- Hugging Face: Mais fácil para testes rápidos com Transformers ou Text Generation Inference. Procure por “TranslateGemma” e verifique o card para licença e variantes quantizadas.
- Google’s Model Garden (Vertex AI): Implantação gerenciada, dimensionamento automático, endpoints privados. Se sua equipe já vive no GCP, é o caminho mais suave.
- Kaggle Models: Útil para notebooks de um clique e benchmarking rápido se você não quiser configurar infraestrutura ainda.
- GitHub + Colab: Andaimes da comunidade aparecem rapidamente, loaders, modelos de prompt e scripts de avaliação básicos.
Notas de configuração da minha execução:
- Quantização ajuda. 4-8 bits tornaram o modelo 12B confortável em uma GPU de consumidor sem danificar a saída. Não senti falta dos bits extras.
- Prompts permanecem curtos. “Traduzir para inglês. Preservar nomes de produtos. Manter contrações.” Isso é o suficiente na maioria das vezes.
- Lote com cuidado. Divida por parágrafos ou grupos de marcadores. Frase por frase funciona, mas você perde a cola de tom.
Se você precisa de guardrails ou controle de glossário, coloque uma leve etapa de pré/pós-processamento:
- Pré-marque nomes de produtos com tags (por exemplo, ) e peça ao modelo para preservá-los.
- Pós-verificação com um glossário matcher para detectar desvio em termos como “Entrar” vs “Fazer login.”
Quem acho que vai gostar de TranslateGemma
- Escritores e profissionais de marketing que querem rascunhos locais de qualidade decente sem alternar ferramentas.
- Equipes de produto adicionando tradução discretamente dentro de um aplicativo, não terceirizando para mais um serviço.
- Pesquisadores que se importam com parágrafos longos e referências permanecendo intactos.
Quem provavelmente não vai
- Qualquer pessoa que precise de tradução instantânea de câmera em férias, use Google Translate.
- Equipes que não querem gerenciar nenhuma computação. Uma API paga com SLAs pode ser mais tranquila.
Eu não esperava mantê-lo por perto. Mas ficou no meu fluxo de trabalho toda a semana porque pede menos de mim: menos abas, menos lembretes, menos pequenas decisões. Essa geralmente é minha pista. E a pequena surpresa? Eu confio nisso com o tom de um parágrafo, não apenas com as palavras. Seu quilômetro pode variar — mas se você está sentindo o barulho de muitas ferramentas, esta fica tranquila. É por isso que ficou comigo.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
