WaveSpeedAI X DataCrunch: Inferência de Imagens FLUX em Tempo Real no B200

WaveSpeedAI X DataCrunch: Inferência em Tempo Real de FLUX no B200
WaveSpeedAI se associou ao provedor europeu de GPU em nuvem DataCrunch para alcançar um avanço na implantação de modelos generativos de imagem e vídeo. Ao otimizar o modelo de peso aberto FLUX-dev no GPU NVIDIA B200 de ponta da DataCrunch, nossa colaboração oferece uma inferência de imagem até 6 vezes mais rápida comparada aos padrões do setor.
Neste artigo, fornecemos uma visão geral técnica do modelo FLUX-dev e do GPU B200, discutimos os desafios de dimensionar FLUX-dev com pilhas de inferência padrão e compartilhamos resultados de benchmark que demonstram como o framework proprietário da WaveSpeedAI melhora significativamente a latência e a eficiência de custos. Equipes de ML empresariais aprenderão como esta solução WaveSpeedAI + DataCrunch se traduz em respostas de API mais rápidas e custo por imagem significativamente reduzido – capacitando aplicações de IA do mundo real. (WaveSpeedAI foi fundada por Zeyi Cheng, que lidera nossa missão de acelerar a inferência de IA generativa.)
Este blog é republicado no blog do DataCrunch.
FLUX-Dev: Modelo SOTA de geração de imagem
FLUX-dev é um modelo de geração de imagem de código aberto estado da arte (SOTA) capaz de geração texto-para-imagem e imagem-para-imagem. Suas capacidades incluem bom entendimento do mundo e aderência ao prompt (graças ao codificador de texto T5), diversidade de estilos, semântica de cenas complexas e compreensão de composição. A qualidade da saída do modelo é comparável ou pode superar modelos populares de código fechado como Midjourney v6.0, DALL·E 3 (HD) e SD3-Ultra. FLUX-dev se tornou rapidamente o modelo de geração de imagem mais popular na comunidade de código aberto, estabelecendo um novo benchmark para qualidade, versatilidade e alinhamento com prompts.
FLUX-dev usa flow matching, e sua arquitetura de modelo é baseada em uma arquitetura híbrida de blocos transformador de difusão multimodal e paralelo. A arquitetura possui 12B de parâmetros, aproximadamente 33 GB fp16/bf16. Portanto, FLUX-dev é computacionalmente exigente com esta grande contagem de parâmetros e processo de difusão iterativo. Inferência eficiente é essencial para cenários de inferência em larga escala onde a experiência do usuário é crucial.
Arquitetura NVIDIA Blackwell GPU: B200
A arquitetura Blackwell inclui novos recursos como núcleos tensor de 5ª geração (fp8, fp4), Tensor Memory (TMEM) e pares CTA (2 CTA).
-
TMEM: Tensor Memory é um novo nível de memória no chip, aumentando a hierarquia tradicional de registradores, memória compartilhada (L1/SMEM) e memória global. No Hopper (por exemplo, H100), dados no chip eram gerenciados via registradores (por thread) e memória compartilhada (por thread block ou CTA), com transferências de alta velocidade via Tensor Memory Accelerator (TMA) para memória compartilhada. Blackwell retém aqueles, mas adiciona TMEM como 256 KB adicionais de SRAM por SM dedicados a operações de núcleo tensor. TMEM não muda fundamentalmente como você escreve kernels CUDA (o algoritmo lógico é o mesmo), mas adiciona novas ferramentas para otimizar fluxo de dados (veja ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (Pares CTA) e Cooperação de Cluster: Blackwell também introduz pares CTA como forma de acoplar fortemente dois CTAs no mesmo SM. Um par CTA é essencialmente um cluster de tamanho 2 (dois thread blocks agendados concorrentemente em um SM com habilidades de sincronização especiais). Enquanto Hopper permite até 8 ou 16 CTAs em um cluster para compartilhar dados via DSM, o par CTA do Blackwell permite que eles usem os núcleos tensor em dados comuns coletivamente. De fato, o modelo PTX do Blackwell permite que dois CTAs executem instruções de núcleo tensor que acessam o TMEM um do outro.
-
Núcleos tensor de 5ª geração (fp8, fp4): Os núcleos tensor no B200 são notavelmente maiores e ~2–2,5 vezes mais rápidos que os núcleos tensor no H100. Alta utilização de núcleo tensor é crítica para alcançar grandes acelerações de hardware de nova geração (veja Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Números de desempenho sem esparsidade
| Especificações Técnicas | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| Memória GPU | 80 GB HBM3 | 180GB HBM3E |
| Largura de Banda de Memória GPU | 3.35 TB/s | 7.7TB/s |
| Largura de banda NVLink por GPU | 900GB/s | 1,800GB/s |
Micro-benchmarking de nível de operador de GEMM e atenção mostra o seguinte:
- Kernels BF16 e FP8 cuBLAS, CUTLASS GEMM: até 2 vezes mais rápido que GEMMs cuBLAS no H100;
- Atenção: cuDNN é 2 vezes mais rápido que FA3 no H100.
Os resultados de benchmarking sugerem que o B200 é excepcionalmente adequado para cargas de trabalho de IA em larga escala, especialmente modelos generativos que exigem alta taxa de transferência de memória e computação densa.
Desafios com Pilhas de Inferência Padrão
Executar FLUX-dev em pipelines de inferência típicos (por exemplo, PyTorch + Hugging Face Diffusers), mesmo em GPUs de alta qualidade como H100, apresenta vários desafios:
- Alta latência por imagem devido a sobrecarga CPU-GPU e falta de fusão de kernel;
- Utilização subótima de GPU e núcleos tensor ociosos;
- Gargalos de memória e largura de banda durante etapas de difusão iterativa.
Os objetivos de otimização para servir inferência em larga escala e barata são maior throughput e menor latência, reduzindo o custo de geração de imagem.
Framework de Inferência Proprietário da WaveSpeedAI
WaveSpeedAI aborda esses gargalos com um framework proprietário desenvolvido especificamente para inferência generativa. Desenvolvido pelo fundador Zeyi Cheng, este framework é nosso mecanismo de inferência de alto desempenho interno otimizado especificamente para modelos de transformador de difusão estado da arte como FLUX-dev e Wan 2.1. As inovações principais no mecanismo de inferência incluem:
- Execução GPU de ponta a ponta eliminando gargalos de CPU;
- Kernels CUDA personalizados e fusão de kernel para execução otimizada;
- Quantização avançada e precisão mista (BF16/FP8) usando Blackwell Transformer Engine mantendo a maior precisão;
- Planejamento de memória otimizado e pré-alocação;
- Mecanismos de agendamento com prioridade de latência que priorizam velocidade sobre profundidade de batch.
Nosso mecanismo de inferência segue um co-design HW-SW, utilizando totalmente a capacidade de computação e memória do B200. Representa um salto significativo para frente em servir modelos de IA, permitindo-nos oferecer inferência com latência ultra-baixa e alta eficiência em escala de produção. Avaliamos como essas otimizações impactam a qualidade da saída, priorizando otimizações sem perdas versus frouxas. Ou seja, não aplicamos otimização que poderia reduzir significativamente capacidades do modelo ou colapsar completamente a qualidade visível da saída, como renderização de texto e semântica de cenas.
Benchmark: WaveSpeedAI no B200 vs. Baseline H100
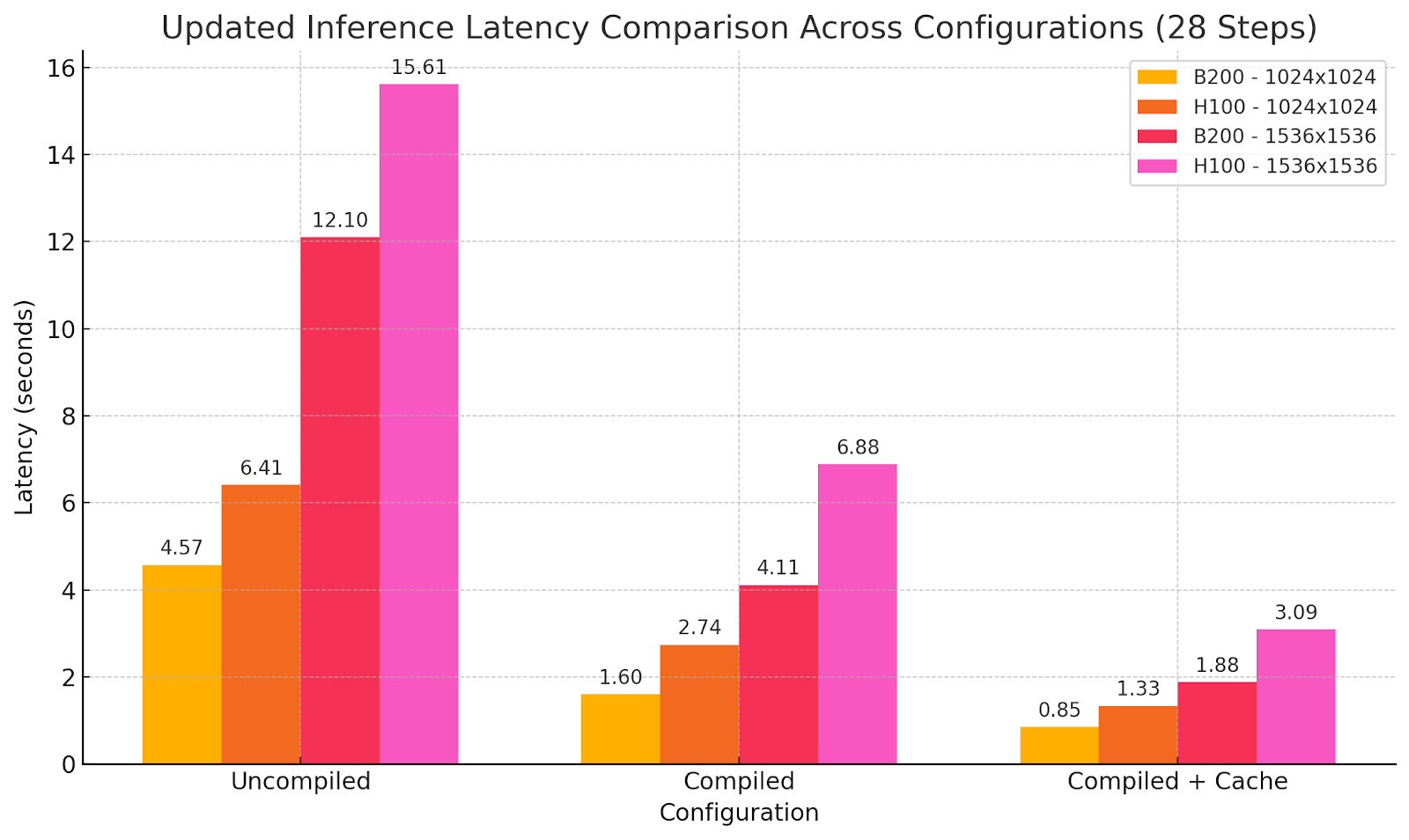
Saídas de modelo usando diferentes configurações de otimização:

Prompt: photograph of an alternative female with an orange bandana, light brown long hair, clear frame glasses, septum piecing [sic], beige overalls hanging off one shoulder, a white tube top underneath, she is sitting in her apartment on a bohemian rug, in the style of a vogue magazine shoot
Implicações
As melhorias de desempenho se traduzem em:
- Design de algoritmo de IA (por exemplo, cache de ativação DiT) e otimização de sistema, usando kernels sintonizados para arquitetura de GPU, para melhor utilização de HW;
- Latência de inferência reduzida levando a novas possibilidades (por exemplo, Test-Time Compute in diffusion models);
- Custo por imagem reduzido devido a melhor eficiência e utilização reduzida de hardware.
Alcançamos razão de desempenho de custo B200 igual H100, mas com metade da latência de geração. Assim, o custo por geração não aumenta enquanto agora ativa novas possibilidades em tempo real sem sacrificar capacidades do modelo. Às vezes mais não é mais, mas diferente, e aqui alcançamos um novo estágio de desempenho, fornecendo um novo nível de experiência do usuário em geração de imagem usando modelos SOTA.
Isso permite ferramentas criativas responsivas, plataformas de conteúdo escaláveis e estruturas de custos sustentáveis para IA generativa em escala.
Conclusão e Próximos Passos
A implantação de FLUX-dev usando B200 demonstra o que é possível quando hardware de classe mundial encontra software de melhor classe. Estamos expandindo as fronteiras de velocidade de inferência e eficiência na WaveSpeedAI, fundada por Zeyi Cheng — criador de stable-fast, ParaAttention e nosso mecanismo de inferência interno. Nas próximas versões, focaremos em inferência eficiente de geração de vídeo e como alcançar inferência próxima a tempo real. Nossa parceria com DataCrunch representa uma oportunidade de acessar GPUs de ponta como B200 e o próximo NVIDIA GB200 NVL72 (Pré-encomende clusters NVL72 GB200 do DataCrunch) enquanto co-desenvolvemos uma pilha crítica de infraestrutura de inferência.”
Comece Hoje:
- Website WaveSpeedAI
- Todos os Modelos WaveSpeedAI
- Documentação da API WaveSpeedAI
- Instâncias DataCrunch B200 sob demanda/spot
Junte-se a nós enquanto construímos a infraestrutura de inferência generativa mais rápida do mundo.
Artigos relacionados

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa

Apple SHARP: Transforme Qualquer Foto em 3D em Menos de um Segundo

Seedream 4.5 vs Nano Banana Pro: Qual Modelo de IA para Geração de Imagens é o Melhor?
Melhor Alternativa ao Adobe Firefly em 2026: WaveSpeedAI para Geração de Imagens com IA