GLM-4.7-Flash vs GLM-4.7: Qual é o Melhor para Seu Projeto?

Olá, meus amigos. Sou a Dora. Se isso soa familiar, você não está sozinho. Já passei por isso: olhando para uma fila de prompts minúsculos e repetitivos que só precisam de uma resposta rápida e sólida—enquanto um par de tarefas de raciocínio multi-etapas teimosas fica no canto, exigindo silenciosamente muito mais potência.
Então finalmente fiz a pergunta em voz alta: onde é que o leve e relâmpago GLM-4.7-Flash realmente brilha, e onde você precisa trazer o mais pesado e deliberado GLM-4.7? Esta é a resposta direta, sem hype, na qual cheguei—fundamentada em execuções reais, benchmarks quando importa, e o objetivo discreto de fazer sua stack diária parecer notavelmente mais leve. Se você já pausou em “qual modelo eu deveria usar aqui?”, isto é para você.
Resposta de 30 Segundos
Se velocidade e baixo custo são suas alavancas principais, o GLM-4.7-Flash provavelmente parecerá certo. Se seu trabalho se inclina para profundidade de raciocínio, ferramentas ou saídas de maior fidelidade, o GLM-4.7 é a escolha mais estável. O resto é nuance em torno de orçamentos de latência, tamanho de contexto e como seus prompts se comportam sob pressão.
Escolha Flash Se…
Flash não é “mais fraco”—é apenas muito honesto sobre o que é bom.
- Você está enviando muitos trabalhos pequenos: resumos, tags, rascunhos, transformações rápidas.
- Latência importa mais do que extrair os últimos 10% de qualidade.
- Você está experimentando, prototipando ou construindo interações de UI que devem parecer instantâneas.
- Oscilações ocasionais em longas etapas de raciocínio não o derrotarão.
- Você quer um modelo padrão mais barato e pode escalar para o GLM-4.7 apenas quando necessário.
Escolha GLM-4.7 Se…
Este é seu modelo “não estrague isso”.
- Você se importa com a confiabilidade do código, raciocínio multi-etapas ou precisão de uso de ferramentas.
- Os prompts são longos, as instruções rigorosas, ou as saídas precisam ser consistentes.
- Você está executando avaliadores, testes ou fluxos de trabalho onde um erro é caro.
- Você precisa de resultados mais fortes em tarefas de codificação e contexto longo.
- Você pode tolerar custo mais alto e um pouco mais de latência para melhores resultados.
Diferenças de Arquitetura
 Eu não persigo contagens de parâmetros por esporte, mas a arquitetura explica muito sobre o comportamento: por que um modelo parece ágil e o outro parece deliberado.
Eu não persigo contagens de parâmetros por esporte, mas a arquitetura explica muito sobre o comportamento: por que um modelo parece ágil e o outro parece deliberado.
Contagem de Parâmetros e Especialistas Ativos
O GLM-4.7 parece executar um backbone maior e (de notas públicas) usa roteamento de especialistas que prioriza o raciocínio. Flash é ajustado para throughput, roteamento mais leve, menos especialistas ativos por token e configurações de eficiência agressivas. Na prática, isso tende a aparecer como:
- Flash: computação mais baixa por token, tempos rápidos de primeiro token, mas pode soltar cadeias de raciocínio sob estresse.
- GLM-4.7: mais computação por token, caminhos de raciocínio mais estáveis, melhores escolhas de chamadas de ferramentas.
Se você folhear diagramas de provedor, verá dicas de mistura de especialistas (MoE) e esparsidade de ativação. Os números exatos variam entre versões, então os trato como direcionais, não absolutos. A grande ideia: Flash gasta menos “pensamento” por token então se move mais cedo; GLM-4.7 pensa mais e tropeça menos em casos extremos.
Janela de Contexto e Limite de Saída
Duas questões práticas importam mais do que o número de contexto do headline:
- Até onde na profundidade de prompts longos a qualidade se mantém?
- Quando as saídas ficam longas, o modelo perde o fio?
Flash geralmente anuncia uma janela de contexto saudável, mas a qualidade tende a diminuir mais cedo com prompts muito longos ou instruções densas. O GLM-4.7 mantém coerência mais profundamente em contextos longos e permanece mais obediente à estrutura em saídas longas. Se você está empacotando uma base de conhecimento, GLM-4.7 é o padrão mais seguro. Se você está dividindo entradas ou usando recuperação para manter prompts slim, Flash é muitas vezes bom o suficiente—e muito mais rápido.
Comparação de Benchmarks
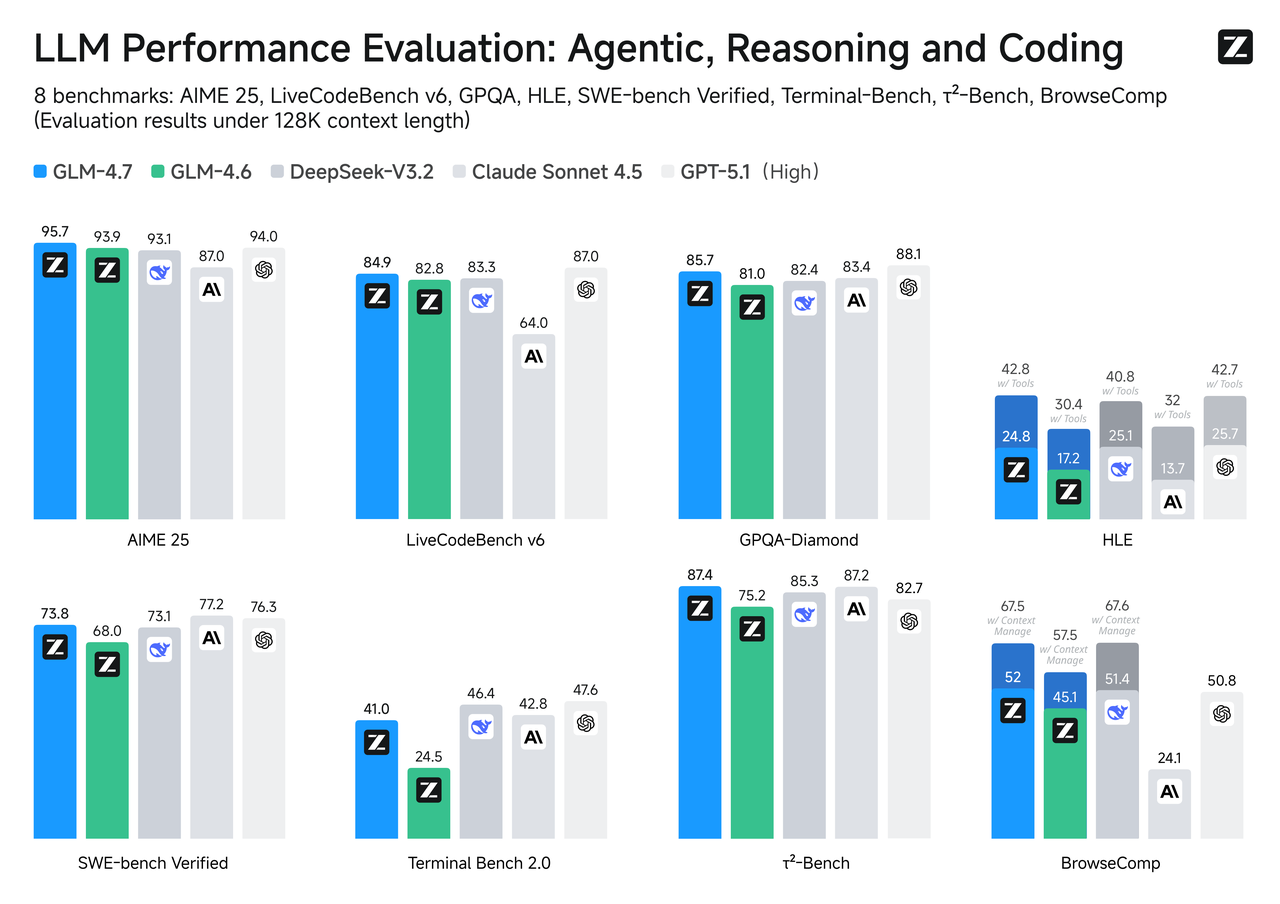 Benchmarks não são toda a história, mas são uma bússola útil, especialmente quando seu caso de uso se alinha com a tarefa.
Benchmarks não são toda a história, mas são uma bússola útil, especialmente quando seu caso de uso se alinha com a tarefa.
SWE-bench Verificado
Para alterações de código que devem realmente compilar e passar testes, o GLM-4.7 tende a classificar acima de seu irmão Flash. Isso corresponde ao que você esperaria de um modelo ajustado para profundidade de raciocínio e uso de ferramentas. Flash pode rascunhar correções e explicar código bem, mas quando o patch precisa de várias edições coordenadas em vários arquivos, o GLM-4.7 é mais provável que siga a cadeia sem soltar etapas.
Se seu pipeline inclui PRs automáticos ou loops de reparo, vale a pena verificar com uma pequena amostra primeiro. A diferença aparece mais em problemas multi-hop do que em ajustes de arquivo único.
LiveCodeBench / τ²-Bench
Em benchmarks de codificação ao vivo ou rotacionando no tempo, o GLM-4.7 geralmente rastreia mais perto do nível superior, dado seu orçamento de raciocínio mais pesado. Flash, otimizado para velocidade, fica um nível abaixo, mas responde rapidamente. Se seu produto depende mais da qualidade de síntese de código do que da velocidade de interação, GLM-4.7 é a escolha conservadora. Se o código é consultivo (você o revisará de qualquer forma) e a responsividade importa, Flash pode ser a negociação certa.
Velocidade e Latência
É aqui que a divisão se sente mais clara. Flash frequentemente retorna o primeiro token notavelmente mais rápido, e o tempo total até o último token permanece baixo para saídas curtas e médias. Isso soma se você estiver executando muitas chamadas pequenas ou transmitindo para uma UI.
GLM-4.7 começa mais lento e funciona mais pesado, mas é mais estável em gerações longas e sequências complexas de chamadas de ferramentas. Você verá menos travamentos, menos desvios estranhos e melhor aderência aos esquemas de função.
Se você está construindo um sistema:
- Use Flash para momentos de UX de alto tráfego: autocompletar, resumos rápidos, ajuda inline.
- Use GLM-4.7 para a pista lenta: avaliadores, ações de código, verificações de política, passagens finais.
Uma regra de roteamento simples frequentemente se paga: comece com Flash, escale para GLM-4.7 quando a confiança cair ou os limites forem ultrapassados. Deixe as regras decidirem para você não ter que fazê-lo.
Detalhamento de Preços
Os preços mudam por região e provedor, então os trato como alvos em movimento e mantenho a estrutura estável.
Camada Gratuita do Flash vs GLM-4.7 Pay-per-Token
-
Flash: Muitas plataformas expõem uma camada gratuita ou de baixo custo para modelos tipo Flash, com limites de taxa generosos em comparação com modelos de ponta. Ótimo para prototipagem, tarefas de fundo e polimento de UI.
-
GLM-4.7: Normalmente cobrado por token a uma taxa mais alta. Melhor relação custo-valor em tarefas sérias, mas é fácil gastar demais se você o deixar como padrão.
 Dicas práticas:
Dicas práticas: -
Limite tokens de saída por padrão. Aumente o limite apenas nas rotas que precisam dele.
-
Use recuperação para manter prompts curtos: não despeje todo o corpus na janela.
-
Cache sub-resultados determinísticos (mapas regex, trechos de esquema, blocos few-shot) para que você não pague por eles novamente.
-
Registre custos de token por rota. O relatório que você realmente lê é aquele que fica em seu fluxo de trabalho semanal, não o com mais gráficos.
Quando em dúvida, comece barato, meça, depois promova. Escalação vence otimismo.
Escolha por Caso de Uso
Aqui está como eu os alocaria quando o objetivo é menos dores de cabeça:
- Operações de conteúdo de alto fluxo (snippets, linhas de assunto, metadados): Flash. A vitória é throughput e consistência a baixo custo.
- Macros de suporte e triagem rápida: Flash primeiro, depois escale para GLM-4.7 se a detecção sinalizar complexidade ou risco de política.
- Notas de pesquisa, síntese, resumos estruturados: Flash para skims; GLM-4.7 para a passagem que deve ser fiel à fonte e bem estruturada.
- Assistência de código: Flash para explicações e “o que isto faz?”; GLM-4.7 para edições multi-arquivo, migrações e mudanças conscientes de teste.
- Limpeza e transformação de dados: Flash é bom para mapeamento simples; GLM-4.7 para esquemas rigorosos, validação e junções multi-etapas.
- Agentes e uso de ferramentas: GLM-4.7. Você obterá argumentos de função mais confiáveis e menos tentativas.
- Leitura de contexto longo ou QA aterrado em documentos: GLM-4.7 se você está empurrando a janela; Flash se você mantém chunks lean.
Alguns apontamentos de campo que mantenho perto:
- Prompts curtos ocultam diferenças. A lacuna aparece quando as instruções são densas ou as saídas devem seguir uma estrutura.
- O roteamento ajuda. Mesmo uma regra simples, “Flash a menos que prompt > N tokens, então GLM-4.7”, economiza dinheiro sem drama.
- Guardrails importam mais do que a escolha do modelo para tarefas repetitivas. Validação, tentativas e pequenos verificadores previnem bagunças a jusante.
- Não fetichize velocidade. Menos de um segundo parece “instantâneo” para a maioria dos usuários. Depois disso, comportamento estável vence raspar 100 ms.
Por que isso importa: as ferramentas envelhecem bem quando reduzem a carga mental. Flash mantém as coisas pequenas leves. GLM-4.7 carrega as caixas pesadas sem soltá-las. A maioria das stacks precisa de ambas.
Se você está inseguro, comece com Flash como seu padrão e crie uma pista clara para GLM-4.7. Deixe rotas, não humores, decidirem. Seu quilometragem pode variar e tudo bem.
Ainda noto, em dias tranquilos, como essa divisão reduz a fadiga de decisão. Nada chamativo—apenas menos dores de cabeça.
Como eu realmente executo essa divisão na prática
 Quando preciso rotear trabalhos rápidos para Flash e escalar os mais pesados para GLM-4.7 sem cuidar de scripts, uso o WaveSpeed—nossa própria plataforma.
Quando preciso rotear trabalhos rápidos para Flash e escalar os mais pesados para GLM-4.7 sem cuidar de scripts, uso o WaveSpeed—nossa própria plataforma.
Construímos para lidar com comutação de modelo, concorrência e chamadas em lote com limpeza, então o padrão “Flash primeiro, escale quando necessário” permanece simples em vez de frágil.
Se você está executando muitas chamadas pequenas e não quer que a lógica de roteamento se torne outra coisa para manter, tente Wavespeed!
FAQ: GLM-4.7-Flash vs GLM-4.7
1. Quais são as principais diferenças entre GLM-4.7-Flash e GLM-4.7?
GLM-4.7-Flash é uma variante leve e otimizada do GLM-4.7. Ele alcança inferência mais rápida e menor custo reduzindo o número de especialistas ativos, simplificando o roteamento e aplicando ajustes de eficiência. GLM-4.7 retém um backbone maior e capacidades de raciocínio mais fortes, exccelindo em raciocínio multi-etapas complexo, coerência de longo contexto e chamadas de ferramentas precisas.
Em resumo: Flash troca um pouco de inteligência por velocidade; GLM-4.7 prioriza profundidade e confiabilidade.
2. Qual modelo é mais rápido e em quais cenários a diferença de velocidade é mais perceptível?
GLM-4.7-Flash tem tempo significativamente menor para primeiro token (TTFT) e latência por token. Ele brilha em casos de uso de alta throughput e baixa latência, como interações de UI em tempo real, resumo de conteúdo, geração de metadados e prototipagem rápida.
GLM-4.7 tem sobrecarga de inicialização mais alta e computação mais pesada, mas permanece mais estável para saídas longas ou sequências complexas de chamadas de ferramentas. Na prática, Flash é notavelmente mais rápido para saídas curtas e médias (menos de 500 tokens).
3. Qual modelo é mais forte em inteligência e raciocínio?
GLM-4.7 supera Flash em raciocínio multi-etapas, confiabilidade de código, uso de ferramentas e tarefas de contexto longo. Exemplos:
- SWE-bench Verificado: GLM-4.7 lidera em edição de código multi-arquivo e patches coordenados.
- LiveCodeBench / τ²-Bench: GLM-4.7 oferece código de qualidade superior, especialmente para cenários de raciocínio profundo.
Flash é adequado para edições de arquivo único ou tarefas assistivas que toleram revisão humana, mas se degrada mais rapidamente em cadeias de raciocínio longas ou prompts densos.
4. Como o comprimento do contexto e os limites de saída se comparam?
Ambos os modelos compartilham janelas de contexto semelhantes, mas GLM-4.7 mantém melhor coerência e conformidade com instruções em contextos muito longos (>32k tokens) ou prompts densos. Flash se degrada mais rapidamente sob comprimento ou densidade de prompt extrema—combine com chunking ou RAG para melhores resultados.
5. Como devo escolher com base em preços e controle de custos?
GLM-4.7-Flash normalmente oferece quotas gratuitas mais altas e preços por token mais baixos (ou até zero), tornando-o ideal para prototipagem, tarefas de fundo e chamadas de alto volume e baixo risco. GLM-4.7 tem custos por token mais altos, mas melhor valor para tarefas críticas.
Recomendação: padrão para Flash, escale para GLM-4.7 para trabalho complexo e sempre defina limites de token e cache para evitar gastos excessivos.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
