Executar GLM-4.7-Flash Localmente: Configuração Ollama, Mac e Windows

Olá, sou a Dora. Alguns dias atrás, um pequeno atrito me empurrou para isto: eu continuava esperando por conclusões remotas para pequenas tarefas de rascunho. Não minutos, apenas o tempo suficiente para me desviar para o email e perder o fio da meada. Na semana passada (janeiro de 2026), tentei executar GLM-4.7-Flash localmente para ver se eliminar esses segundos realmente ajudaria meu pensamento a ser mais direto.
Versão curta: ajudou, mas não pelas razões glamourosas. GLM-4.7-Flash parecia mais um assistente constante do que um modelo de destaque. É rápido o suficiente para me manter no fluxo, e leve o suficiente para rodar em um laptop sem cozinhá-lo. Vou compartilhar o que funcionou, onde estagnou, e a configuração que manteve as coisas entediantes, de uma forma boa.
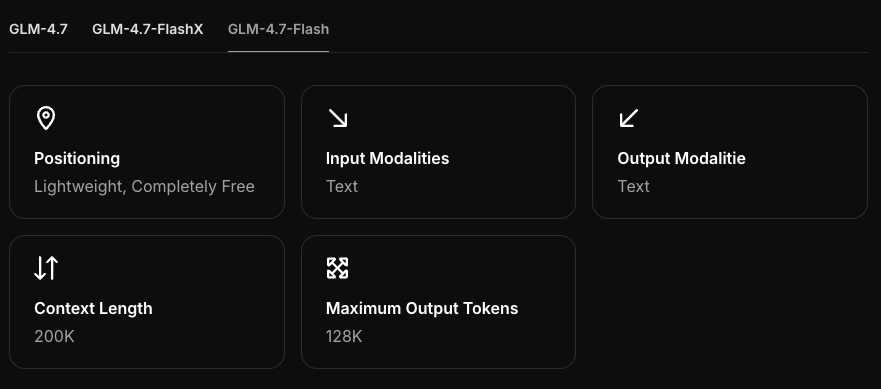
Requisitos de Hardware
GPU / RAM Mínimos
Executei GLM-4.7-Flash em três máquinas:
- MacBook Pro M3 Pro (CPU 12-core / GPU 18-core, 36 GB RAM)
- Mac mini M2 (24-GB de memória unificada)
- Desktop Windows com RTX 4090 (24-GB VRAM)
A partir desses testes, um piso prático:
- Apenas CPU (Mac/Windows/Linux): 16 GB de memória do sistema funcionam, 32 GB é mais gentil. Espere por primeiros tokens mais lentos.
- Apple Silicon (Metal): 16 GB de memória unificada é utilizável com quantização 4-bit/5-bit e contexto modesto (2–4K). 8 GB pareceu apertado.
- NVIDIA: 8–12 GB VRAM é o mínimo que eu tentaria para uma quantização 4-bit. 16 GB+ é mais confortável.
GLM-4.7-Flash parece um modelo de tamanho médio (pense em menos de 10–12B params). Em 4-bit, você geralmente está olhando para ~5–6 GB de memória do dispositivo mais cache KV. Se você empurrar contextos longos ou muitos prompts paralelos, a memória aumenta.
Especificações Recomendadas
Se você quer aquele sentimento “sempre responsivo”:
- Apple Silicon: M3 ou mais novo com 24–36 GB de memória unificada: mantenha contexto 4–8K.
- NVIDIA: 24 GB VRAM (ex.: 3090/4090) oferece espaço para contextos e concorrência mais altos.
- Armazenamento: SSD rápido: os modelos carregam mais rápido e fazem swap menos.
Notei que o modelo deixa de parecer “rápido” quando a pressão de memória aumenta, page-outs ou derramamentos de VRAM adicionam um tremor sutil que quebra o fluxo. Um pouco de espaço extra faz uma grande diferença.
Configuração Ollama
Usei Ollama porque mantém execuções locais simples e consistentes entre máquinas. O contexto da versão importa aqui.
Instale Ollama 0.14.3+
- macOS: brew install ollama (ou atualize com brew upgrade ollama).
- Windows: use o instalador oficial do site Ollama.

- Linux: siga o script curl da documentação.
Estou na 0.14.3 neste teste (janeiro de 2026). As versões mais recentes às vezes alteram backends padrão ou comportamento de quantização, então fico com a versão que é estável para mim até ter uma razão para pular.
Puxe e Execute GLM-4.7-Flash
Dois caminhos funcionaram para mim:
-
Se sua biblioteca Ollama inclui uma compilação oficial GLM-4.7-Flash:
- ollama pull glm-4.7-flash
- ollama run glm-4.7-flash
-
Se não aparecer (isso aconteceu em uma máquina):
- Crie um Modelfile que aponta para um GGUF conhecido ou artefato compatível para GLM-4.7-Flash.
- Exemplo Modelfile (simplificado):
- FROM ./glm-4.7-flash-q4.gguf
- Adicione modelos de prompt apenas se souber que precisa: deixei mínimo.
- Depois: ollama create glm-4.7-flash-local -f Modelfile
- Execute: ollama run glm-4.7-flash-local
Notas do uso:
- O primeiro carregamento é mais lento conforme aquece os caches.
- Mantenho num_ctx conservador (4K ou 8K) a menos que esteja resumindo um rascunho de livro. Contextos maiores parecem legais, mas são gulosos em memória e nem sempre ajudam a qualidade para rascunhos cotidianos.
- Se as gerações parecerem hesitantes, tente reduzir a temperatura para 0.6–0.7 e aumentar top_p um pouco: isso aprimorou as saídas para mim sem perder velocidade.
Referências: a documentação Ollama é sólida para sinalizadores específicos da plataforma e backends atuais.

Desempenho do Mac
Benchmarks M4 / M3 / M2
Estes não são de laboratório, apenas execuções constantes em escrita e prompts de código leve, temperatura 0.7, contexto 4K, quantização 4-bit:
- M4 (máquina emprestada, 48 GB): 60–85 tok/s uma vez aquecido. Primeiro token em ~350–500 ms.
- M3 Pro (36 GB): 35–55 tok/s. Primeiro token em ~500–800 ms.
- M2 (24 GB): 20–30 tok/s. Primeiro token em ~900–1200 ms.
Considere os intervalos como uma verificação de vibe. Empurrei alguns contextos 8K no M3 Pro: a velocidade caiu ~20–30% mas permaneceu utilizável para rascunho. No M2, contextos longos cruzaram minha linha “sente-se pegajoso”. Mantive de 2–4K lá.
Otimização de Memória
O que mais ajudou no macOS:
- Mantenha menos abas de terminal executando modelos. Óbvio, sim, mas eu esqueço.
- Dimensione corretamente o contexto. 4K é um ponto ideal para mim.
- Use quantização 4-bit quando puder. 5-bit pareceu semelhante em qualidade para meu uso, mas mais lento.
- Feche aplicativos que puxam tempo de GPU (editores de vídeo, algumas abas do navegador com WebGL).
Também notei que usar um prompt do sistema estável reduziu refazimentos. Não é mais rápido no papel, mas menos tentativas significa melhor “velocidade percebida”. Um pequeno prompt como: “Seja conciso, use inglês simples, sem tom de marketing.” Ele se encaixa nos pontos fortes do modelo.
Windows + NVIDIA
Configuração RTX 3090 / 4090
Na 4090 (24 GB), GLM-4.7-Flash se sentiu consistentemente rápido:
- Quantização 4-bit, contexto 4–8K: 120–220 tok/s após aquecimento.
- Primeiro token: ~250–400 ms.
- Prompts paralelos: 2–3 fluxos antes de ver tremor.
Um amigo executou na 3090 (24 GB) e viu ~15–25% de throughput mais baixo com configurações semelhantes. Se você empurrar além de contexto 8K ou mantiver muitas respostas acontecendo ao mesmo tempo, você atingirá o espaço de VRAM. Geralmente recuo para 4–6K e mantenho lotes pequenos.
Configuração CUDA
O que importava na prática:
- Driver NVIDIA recente (limpeza de instalação ajudou uma máquina que tremulava).
- CUDA 12.x e runtime correspondente se você está saindo do Ollama (vLLM/SGLang). Para o próprio Ollama, você nem sempre precisa de um Kit completo, mas drivers atualizados são inegociáveis.
- Configurações de energia: configure sua GPU para “Preferir desempenho máximo.” Parece conselho para jogadores, mas impediu throttling de clock durante execuções longas.
Se você atingir erros de carga ou quedas difíceis para CPU, eu verificaria:
- Alinhamento de versão de driver com tempo de execução CUDA.
- Se um antivírus está digitalizando seu diretório de modelo (aconteceu: foi tolo: foi lento).
Referência: a tabela de compatibilidade driver–CUDA da NVIDIA vale uma verificação rápida antes de você gastar uma hora depurando.
vLLM / SGLang
Tentei GLM-4.7-Flash com vLLM e SGLang quando queria mais controle sobre batching e endpoints de servidor.
vLLM
- Instalar: Python recente, PyTorch compatível com CUDA, depois pip install vllm.
- Executar:
python -m vllm.entrypoints.openai.api_server --model <your_glm_flash_id> --dtype auto --max-model-len 4096 - Por que usei: API compatível com OpenAI estável, throughput sólido para fluxos multi-usuário ou multi-aba.
SGLang
- Instalar: pip install sglang
- Executar:
python -m sglang.launch_server --model <your_glm_flash_id> --context-length 4096 - Por que usei: streaming de baixa latência se sentiu ágil, e jogou bem com pequenas tarefas de roteamento.
Ambos querem um caminho de modelo adequado ou ID de repo HF. Se GLM-4.7-Flash não está em seu índice padrão, você precisará apontá-los para um GGUF local ou um formato de peso compatível. Também: corresponda versões CUDA e driver, ou você perseguirá erros de kernel opacos. Mantive dtype em auto e apenas forcei fp16 quando sabia que tinha VRAM para poupar.
Para minhas sessões de escrita mono-usuário, Ollama permaneceu mais simples. vLLM/SGLang fizeram sentido quando testei ferramentas que precisavam de um endpoint de estilo OpenAI.
Solução de Problemas
Falhas de Carregamento de Modelo
O que vi:
- “sem memória” durante o carregamento. Correção: mude para uma quantização menor (ex.: 4-bit), abaixe num_ctx, ou feche aplicativos pesados em GPU.
- “nenhum backend compatível” no Windows. Correção: atualize driver de GPU: certifique-se de não ter instalado PyTorch apenas para CPU se estiver usando vLLM/SGLang: reinicie após atualizações de driver.
- Modelo não encontrado em Ollama. Correção: criar um Modelfile e ollama create: ou puxar do tag de repo exato se existir.
Se um modelo cai silenciosamente para CPU, o sinal é ruído do ventilador (ou falta dele) mais tokens/sec muito mais lentos. Aprendi a verificar a utilização do dispositivo antes de assumir que o modelo ficou “pior”.
Correções de Inferência Lenta
Pequenas mudanças que importaram mais do que eu esperava:
- Dimensione corretamente o contexto. Reduzir o contexto pela metade geralmente o acelera mais do que mexer na amostragem.
- Aqueça o cache. Uma execução curta rápida melhora a próxima.
- Reduza fluxos paralelos. Concorrência parece eficiente até o cache KV o derrotar.
- Para NVIDIA: configure modo Desempenho Alto, feche aplicativos de sobreposição, e pare codificadores em segundo plano.
- No macOS: mantenha o carregador ligado: alguns laptops reduzem de velocidade quando na bateria.
Um mais: parei de perseguir máximo tokens/sec. A métrica melhor para mim foi “primeiro pensamento utilizável.” GLM-4.7-Flash me deu isso rapidamente quando mantive prompts focados e contextos razoáveis.
 Se você gosta da velocidade do GLM-4.7-Flash mas não ama cuidar de drivers, versões CUDA, ou peculiaridades de backend, tente WaveSpeed - nossa própria plataforma focada em inferência estável e rápida sem ajuste de baixo nível. Você obtém latência previsível sem se preocupar com arquivos de modelo, formatos de quantização, ou compatibilidade de GPU.
Se você gosta da velocidade do GLM-4.7-Flash mas não ama cuidar de drivers, versões CUDA, ou peculiaridades de backend, tente WaveSpeed - nossa própria plataforma focada em inferência estável e rápida sem ajuste de baixo nível. Você obtém latência previsível sem se preocupar com arquivos de modelo, formatos de quantização, ou compatibilidade de GPU.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
