GLM-4.7-Flash: Data de Lançamento, Camada Gratuita e Recursos Principais (2026)

Oi galera, sou a Dora.
Recentemente, GLM-4.7-Flash continuava aparecendo em threads de pessoas em quem confio, geralmente mencionado com um encolher de ombros: “rápido o suficiente para sair do caminho.” Essa frase ficou comigo. Não estou atrás de modelos brilhantes agora: estou atrás de ferramentas que tornam o trabalho diário mais leve. Entende?
Então dei a GLM-4.7-Flash alguns dias na minha stack (20–21 de janeiro de 2026). Prompts curtos, pequenos scripts de API, alguns trabalhos em lote. Nada dramático. A pergunta que mantive comigo era simples: é uma adição prática, ou apenas outro nome de modelo passando pela timeline?
O que é GLM-4.7-Flash?
GLM-4.7-Flash é uma variante focada em velocidade da família GLM-4.7 da Zhipu AI. Pense nela como aquela que você usa quando quer gerações responsivas e de baixa latência sem sobrecarga de raciocínio pesado. Não está tentando vencer benchmarks de longa duração ou debater filosofia: está visando retornar respostas decentes rapidamente e com custo baixo.
Quem Fez (Zhipu AI / Z.ai)
 Zhipu AI (também vista como Z.ai) é o time por trás da série GLM. Se você experimentou modelos GLM anteriores, a nomenclatura parecerá familiar: o número reflete a geração, e o sufixo (Flash, Standard, etc.) dá dicas sobre os trade-offs. Sua documentação é direta e regularmente atualizada: se você está integrando, marque como favorito a documentação oficial da API no portal de desenvolvedores da Zhipu.
Zhipu AI (também vista como Z.ai) é o time por trás da série GLM. Se você experimentou modelos GLM anteriores, a nomenclatura parecerá familiar: o número reflete a geração, e o sufixo (Flash, Standard, etc.) dá dicas sobre os trade-offs. Sua documentação é direta e regularmente atualizada: se você está integrando, marque como favorito a documentação oficial da API no portal de desenvolvedores da Zhipu.
Usei modelos Zhipu de vez em quando no último ano quando precisava de cobertura multilíngue e saídas estáveis e previsíveis. GLM-4.7-Flash continua esse padrão, apenas com mais atenção na velocidade e throughput.
Flash vs Standard, Posicionamento
Aqui está como senti as diferenças na prática:
- Flash: otimizada para velocidade, menor computação por requisição, ótima para endpoints de alto volume, assistentes de UI e classificação ou marcação em lote. Percebi que era mais feliz com prompts concisos e estrutura clara.
- Standard (não-Flash): mais lenta mas mais estável em tarefas que requerem raciocínio pesado. Se eu jogasse análise multi-etapa em Flash, ela tentava, mas podia ver que estava comprimindo etapas para manter a latência baixa.
Se você está escolhendo entre elas, uma regra gentil: se latência e custo moldam seu dia-a-dia, comece com Flash. Se a correção em raciocínio multi-hop é sua restrição primária, Standard (ou um irmão sintonizado para raciocínio maior) provavelmente funcionará melhor. Sabe, escolha seu lutador.
Lançamento Oficial: 19 de janeiro de 2026
Zhipu AI anunciou GLM-4.7-Flash em 19 de janeiro de 2026. Comecei a testar no dia seguinte. O contexto de versão importa com esses modelos: os primeiros dias geralmente vêm com iteração rápida. Se você está lendo isso depois, verifique as notas de lançamento na documentação oficial para confirmar quaisquer mudanças nos limites ou comportamento.
Arquitetura em Síntese
Não preciso conhecer os internos de um modelo para usá-lo, mas certos detalhes me ajudam a estimar custos e onde ele se destacará.
30B MoE, 3B Parâmetros Ativos
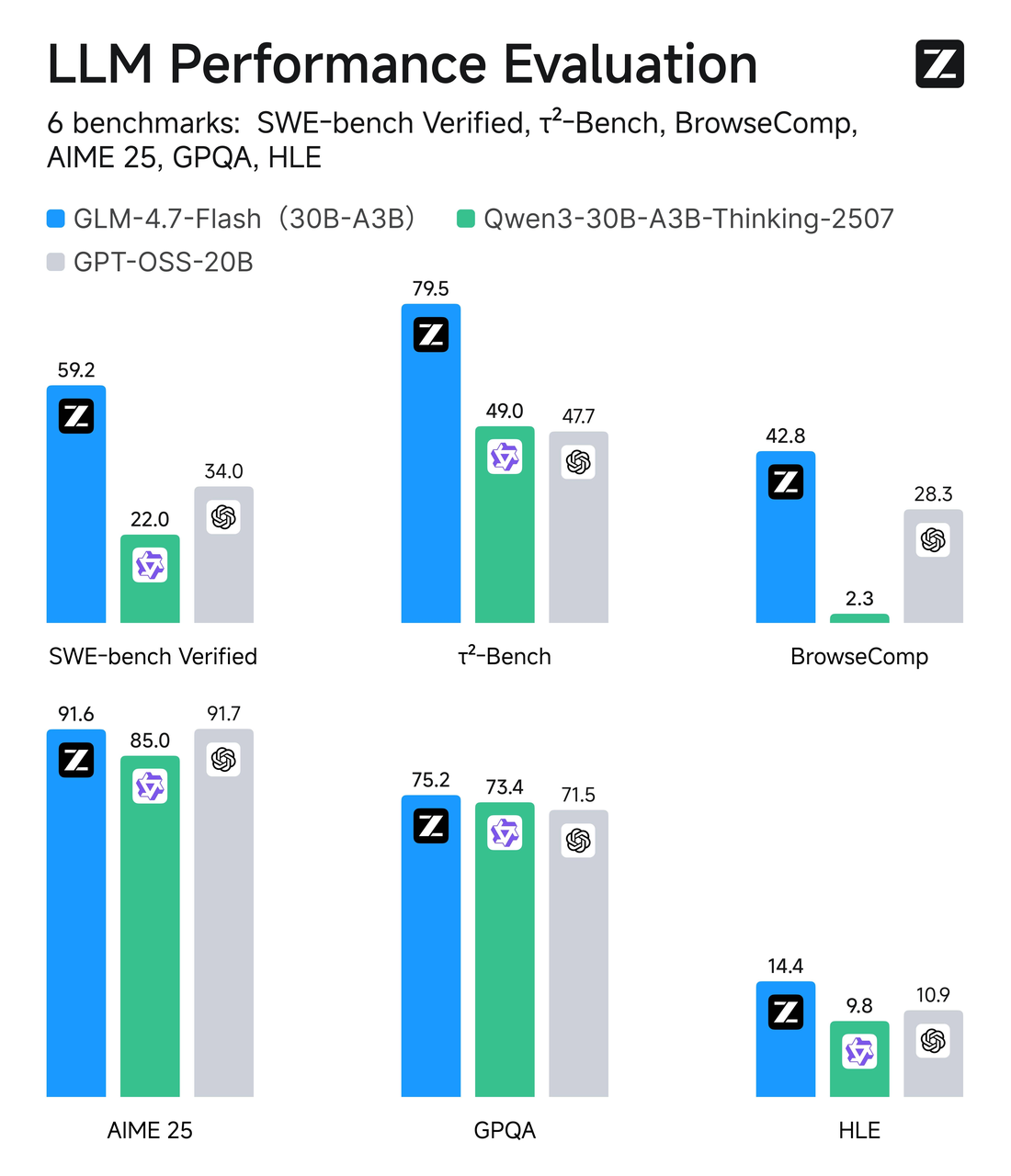 GLM-4.7-Flash usa um design Mixture-of-Experts (MoE) com contagem total de parâmetros em torno de 30B, mas apenas ~3B experts são ativos por token. Em termos simples: é um modelo amplo com roteamento seletivo. Na maioria das vezes, apenas uma pequena fatia da rede funciona no seu token, o que mantém a inferência enxuta.
GLM-4.7-Flash usa um design Mixture-of-Experts (MoE) com contagem total de parâmetros em torno de 30B, mas apenas ~3B experts são ativos por token. Em termos simples: é um modelo amplo com roteamento seletivo. Na maioria das vezes, apenas uma pequena fatia da rede funciona no seu token, o que mantém a inferência enxuta.
Na prática, MoE geralmente oferece uma sensação de “cérebro maior quando necessário” sem sempre pagar o preço completo da computação. Durante meus testes, isso se traduziu em saídas responsivas mesmo sob carga, e latência mais consistente do que modelos densos de escala relatada similar. Não é mágica, apenas uma forma inteligente de equilibrar capacidade e velocidade.
MLA (Multi-Headed Latent Attention)
Os documentos mencionam MLA (Multi-Headed Latent Attention). Meu entendimento como usuária: é uma estratégia de atenção visando ser mais eficiente que a auto-atenção clássica completa, especialmente em contextos mais longos. Não forcei os limites de contexto longo aqui: meus testes foram principalmente sob alguns milhares de tokens. Ainda assim, a pegada de memória permaneceu razoável, e não vi o slide lento usual na latência conforme os prompts cresciam de “curto” para “médio”.
Se você está planejando fluxos de trabalho com retrieval pesado ou loops de agente, MLA mais MoE é um sinal útil: este modelo foi projetado para manter o throughput em vez de perseguir profundidade de raciocínio máxima de um único disparo.
API Gratuita — O que está Incluído
O acesso gratuito se destacou. Sou cuidadosa aqui porque os níveis gratuitos mudam, às vezes semanalmente. O que estou compartilhando é o que observei em 20–21 de janeiro de 2026, e o que os documentos da Zhipu sugeriram no lançamento. Sempre verifique novamente os limites antes de conectar isso à produção.
 Em resumo: a API gratuita me permitiu fazer requisições reais com padrões sensatos. Executei pequenos trabalhos sem atingir um paywall no meio do teste. Isso reduziu o atrito para experimentá-la em um script ao vivo em vez de em um playground.
Em resumo: a API gratuita me permitiu fazer requisições reais com padrões sensatos. Executei pequenos trabalhos sem atingir um paywall no meio do teste. Isso reduziu o atrito para experimentá-la em um script ao vivo em vez de em um playground.
Limites de Taxa e Concorrência
O que observei:
- Concorrência: Consegui executar confortavelmente múltiplas requisições paralelas de um pequeno worker sem disparar erros. Em meus testes, 5–10 chamadas simultâneas permaneceram estáveis. Quando aumentei para cima, comecei a ver throttling, o que é esperado em uma camada gratuita.
- Throughput: Prompts curtos (classificação, pequenas transformações) retornaram no intervalo de sub-segundo para alguns segundos. Em média, vi 300–900 ms para respostas muito curtas e 1,5–3 s para saídas modestas. A variação de rede se aplica.
- Segurança: A API respondeu com códigos de erro claros quando excedi os limites. Isso sozinho me economizou tempo, não tive que adivinhar o que correu mal.
Não persegui tetos de TPS exatos: meu objetivo era ver se pequenos pipelines podiam rodar sem babá. Conseguiram. Parece liberdade, honestamente. Se você está planejando cargas de trabalho abruptas, teste com concorrência realista e construa retry/backoff simples. Os níveis gratuitos são generosos até que não são mais.
Nível Pago FlashX
Zhipu menciona uma opção paga “FlashX” visando throughput mais alto e desempenho mais previsível. Não moveI meus testes para FlashX durante essa corrida, mas aqui está o que tipicamente muda quando você atualiza tiers com provedores como este:
- Limites de taxa mais altos e garantidos com menos throttles.
- Mais requisições simultâneas por chave, útil para trabalhos em lote e assistentes voltados para o usuário.
- Roteamento prioritário (latência de cauda mais baixa). Isso importa quando você se importa com o pior 5% de requisições, não apenas a mediana.
Se você está lançando um recurso voltado para o cliente, FlashX é a rota mais segura. Se você está mexendo, o nível gratuito é bom o suficiente para ter uma sensação de estabilidade e trabalho de integração. Sua quilometragem dependerá do seu orçamento de latência e da frequência com que você faz lotes.
Melhores Casos de Uso
Tentei um punhado de tarefas reais. Nada glamoroso, apenas o que aparece na minha semana.
- Assistentes de interface onde lag mata o clima. Pense em: rewrites inline, pequenos esclarecimentos, pequenos follow-ups. GLM-4.7-Flash mantinha a UI parecendo imediata.
- Transformações de texto em lote. Executei um pequeno CSV (alguns milhares de linhas) para ajustes de tom e tags de categoria. O modelo permaneceu consistente e não derivou no meio do caminho.
- Andaimes de esboço. Esboços, expansões ponto-a-ponto, breves simples. Lidou bem com estrutura quando dei instruções nítidas. Como ter um mini-assistente que você não precisa subornar.
- Resumos de recuperação com pequenas janelas de contexto. Quando canalizei 2–4 trechos, respondeu limpar sem alucinar estranhas pontes. Com contexto longo e bagunçado, tentou ser útil mas às vezes comprimiu agressivamente demais.
- Comentários de código de “primeira passagem” ou docstrings. Não refatorações profundas. Apenas esclarecendo intenção e nomenclatura, rápido e útil.
Onde eu não usaria:
- Análise multi-hop com casos extremos onde precisão importa mais que velocidade. Alcançaria um modelo de raciocínio mais pesado.
- Geração de longa duração onde você precisa de tom constante e costura factual profunda em milhares de tokens. Flash pode fazer, mas parece fora de personagem.
Por que isso importa: modelos rápidos que não explodem seu orçamento abrem recursos que você cortaria de outra forma. Se seu produto precisa de dezenas de pequenas chamadas de modelo por sessão, latência reduzida e computação menor por chamada se somam. Pequenas vitórias, grande recompensa.
💡 Para tornar a execução de modelos como GLM-4.7-Flash mais fácil e confiável em fluxos de trabalho reais, uso WaveSpeed — nossa própria plataforma que lida com requisições de API, concorrência e trabalhos em lote suavemente, para que você possa se concentrar em resultados em vez de babá scripts.
Tente WaveSpeed →
 Uma pequena nota das trincheiras: minha primeira hora não foi mais rápida. Mexi com estrutura de prompt, temperatura e max tokens. Depois de alguns testes, encontrei um padrão, prompt de sistema curto, formato de saída explícito, restrições claras. Isso reduziu tanto tempo quanto esforço mental. Não foi mágica: foi configuração.
Uma pequena nota das trincheiras: minha primeira hora não foi mais rápida. Mexi com estrutura de prompt, temperatura e max tokens. Depois de alguns testes, encontrei um padrão, prompt de sistema curto, formato de saída explícito, restrições claras. Isso reduziu tanto tempo quanto esforço mental. Não foi mágica: foi configuração.
Quem mais começou um teste “rápido de 10 minutos” de GLM-4.7-Flash (ou qualquer modelo Flash) e piscou para encontrar o relógio dizendo meia-noite? Deixe seu recorde pessoal—e a mudança de prompt que finalmente o fez se comportar—nos comentários.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
