Crie um Âncora de IA em 5 Minutos: Um Guia para Iniciantes sobre Como Criar Humanos Digitais

Um tutorial passo a passo para construir um humano digital no WaveSpeedAI.
Prefácio
Nem todos nascem oradores naturais, e nem todos se sentem confortáveis falando em frente a uma multidão.
Apresentar-se em público pode ser assustador — mas e se um “você virtual” pudesse fazer a apresentação, ir ao vivo ou gravar seu texto de promoção para você? Você ainda teria medo?
No WaveSpeedAI, isso não é mais apenas uma ideia! Você pode criar seu próprio humano digital do zero e fazer com que ele fale suas palavras com voz e expressões realistas.
Ele não fica com medo de palco, nunca fica cansado, e você pode refiná-lo e reutilizá-lo quantas vezes quiser. É seu parceiro confiável no trabalho e na vida.
Neste tutorial, vamos guiá-lo do zero até a conclusão enquanto você constrói um humano digital simples passo a passo. Os modelos que usamos aqui são apenas o começo — sinta-se à vontade para explorar mais capacidades e estilos para tornar seu humano digital verdadeiramente único.
No WaveSpeedAI, nossos modelos produzem visuais claros e estáveis com bordas naturais e estão prontos para apresentação. Funcionam bem para segmentos formais de apresentação, conversas casuais e explicadores de produtos.
Geração de Imagem
Um humano digital bonito, fofo e com aparência natural oferece aos espectadores uma experiência melhor. Também atrairá mais atenção e tráfego para seu canal.
Você também pode criar um diretamente a partir de uma foto pessoal. Se você já tiver uma foto adequada pronta, sinta-se à vontade para pular esta parte.
Usarei bytedance/seedream-v4 como exemplo para ajudá-lo a criar um avatar virtual que seja únicamente seu.
No WaveSpeedAI, procure por bytedance/seedream-v4 — é um modelo texto-para-imagem. Agora, vamos inserir um prompt para criar seu próprio humano digital:
Retrato em meia-altura de uma jovem mulher humano digital (22-28 anos),
maquiagem natural, camiseta branca e blazer cinza claro,
olhando para a câmera, luz de estúdio suave,
fundo cinza claro simples, ultra realista, 4k, 85mm, f/2.8
Você pode personalizar elementos como gênero, roupas e fundo para atender suas necessidades, criando vários estilos e humores para que seu humano digital pareça mais atraente e alinhado com sua marca.
Geração de Voz
Agora que seu humano digital está pronto, o próximo passo é elaborar um script de narração claro para que ele possa “falar” naturalmente.
No WaveSpeedAI, vá para Categoria > Texto-para-Áudio para explorar vários modelos. Oferecemos modelos para narrações naturais, clonagem de voz e até composição de músicas.
Nesta seção, usaremos minimax/speech-02-hd como nosso exemplo. Sinta-se à vontade para tentar outros modelos e explorar diferentes estilos e efeitos vocais.
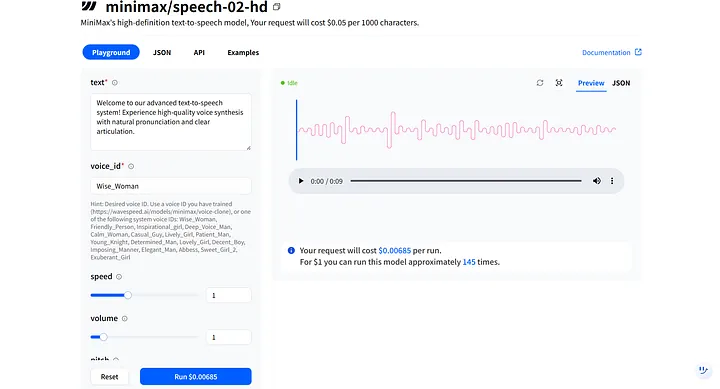
No Playground do modelo, você verá parâmetros-chave como text e voice_id. Eles trabalham juntos para moldar o tom e o timbre do seu humano digital, e você pode ajustá-los para diferentes cenários. Por exemplo, o humano digital que criei é feminino, então posso selecionar a primeira opção de voz, Wise_Woman.
Parâmetros-Chave
Velocidade
speed controla a rapidez com que seu humano digital fala. Escolha um ritmo que se adeque à cena — por exemplo, desacelere um pouco para introduções de produtos e acelere para conversas casuais. Um valor de 1 indica velocidade normal.

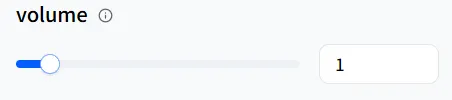
Volume
volume define o volume. Se seu humano digital estiver narrando uma história de ninar, você pode diminuir a speed para desacelerar as coisas e reduzir o volume para uma entrega mais suave. Um valor de 1 é o volume padrão.
Tom
pitch ajusta o tom da voz. Ajuste isso para tornar a voz soar mais brilhante e nítida ou mais profunda e cheia. Um valor de 0 é o tom padrão.

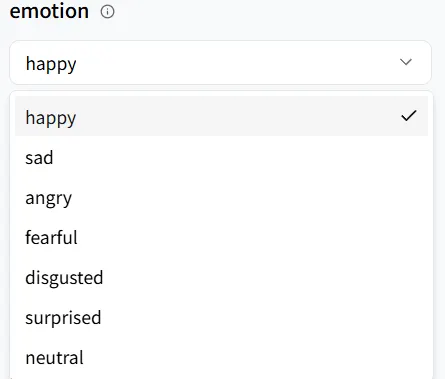
Emoção
emotion controla o estilo de fala do seu humano digital. Escolha um tom que corresponda à cena — aqui, vamos escolher happy (feliz).
Normalização em Inglês
A opção english_normalization, quando ativada, faz com que números e símbolos em inglês soem naturais na fala. Sem ela, o sistema pode ler dígitos um por um (por exemplo, “um dois três” para “123”) em vez de “cento e vinte e três”.

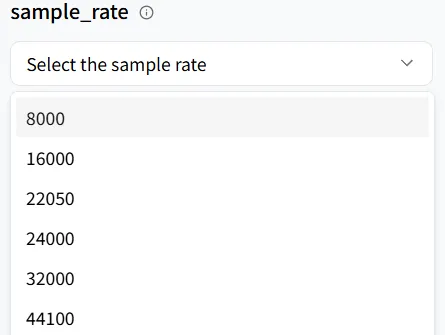
Taxa de Amostragem
sample_rate determina a qualidade do áudio (resolução). Se você estiver produzindo conteúdo no estilo ASMR, aim para uma taxa de amostragem mais alta para detalhes mais ricos. Para este exemplo do tutorial, não é crítico — manter o padrão é perfeitamente adequado.
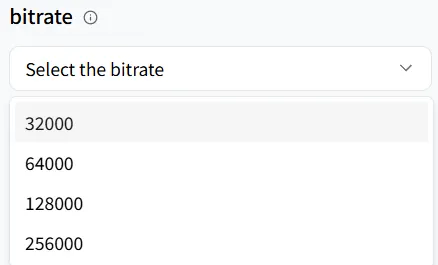
Taxa de Bits
bitrate determina tanto a qualidade quanto o tamanho do seu arquivo de áudio. Representa o número de bits processados por segundo. Uma taxa de bits mais baixa cria um arquivo menor, mas pode perder detalhes; uma taxa de bits mais alta resulta em um arquivo maior com som mais claro.
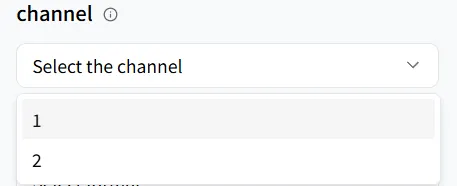
Canal
O parâmetro channel determina o número de canais de áudio gerados.
- channel = 1 (mono): Todo o som é misturado em um único canal — ideal para voz telefônica, gravações de chamadas ou conteúdo focado em diálogo, onde a largura espacial não é necessária.
- channel = 2 (estéreo): O som é dividido em canais esquerdo e direito, criando largura e uma sensação de espaço para uma experiência mais imersiva e em camadas — perfeito para música, filmes, jogos e narrações de vídeo que exigem maior qualidade de audição.
Formato
format permite que você selecione o tipo de arquivo de áudio de saída (vamos pular os detalhes aqui).
Reforço de Idioma
language_boost melhora a compreensão do modelo do idioma selecionado. Para este tutorial, escolha English (Inglês).
Gerar Áudio
Em seguida, cole seu script e clique em Run para gerar o áudio!
Bem-vindo ao Tutorial de Humano Digital do WaveSpeedAI. Vamos apresentar ideias novas em AIGC e mostrar passos práticos. Vamos liberar sua criatividade juntos!
Baixe o arquivo de áudio — esta é a peça crucial que permitirá que seu humano digital fale mais tarde!
Deixe o Humano Digital Falar
Finalmente, o momento emocionante: vamos fazer seu humano digital realmente falar!
No WaveSpeedAI, procure por wavespeed-ai/infinitetalk — nosso modelo de alta qualidade projetado especificamente para narrações de humanos digitais.
No Playground do modelo, você verá duas entradas necessárias: audio e image.
- audio: Faça upload do arquivo de narração que você acabou de baixar.
- image: Faça upload da imagem do humano digital que você gerou anteriormente.
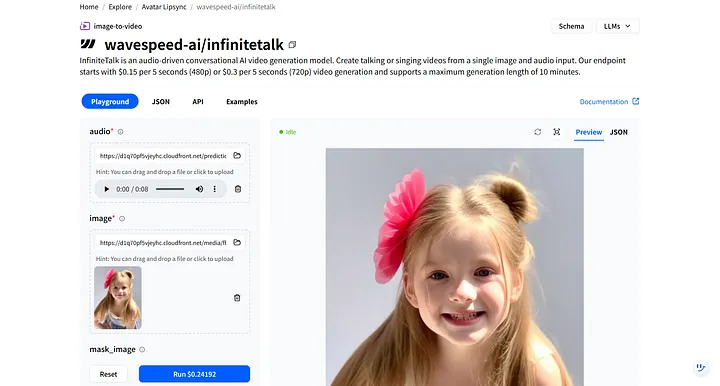
Depois de clicar em Run, o humano digital responde ao áudio e sincroniza automaticamente os movimentos dos lábios e as expressões faciais.
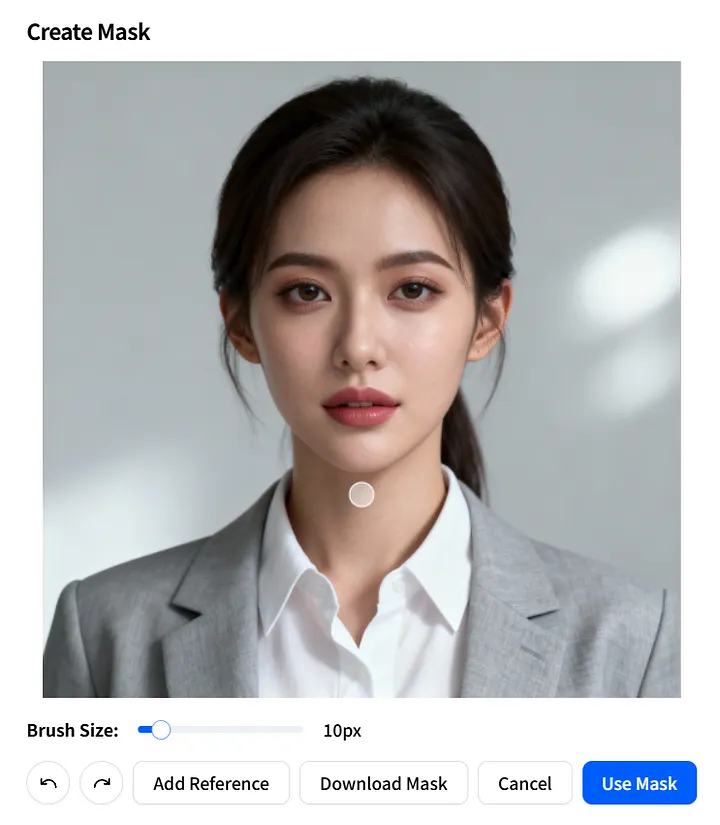
Parâmetro de Imagem de Máscara
Em seguida, vamos examinar o parâmetro mask_image. Ele permite especificar exatamente quais partes da imagem devem ser animadas.
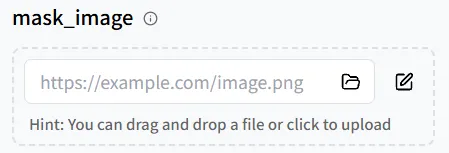
Na página Create Mask, defina com precisão a área móvel: ajuste o Brush Size, pinte sobre as regiões que deseja animar e clique em Use Mask para aplicar.
Você também pode clicar em Download Mask para salvar a mask_image como um modelo para reutilização rápida em projetos futuros.
Personalização Adicional
Se você tiver necessidades adicionais — como especificar uma pose, gestos de mão ou direção do olhar — adicione instruções mais específicas no prompt.
Para fácil replicação, defina um valor seed fixo. Isso garante que a aleatoriedade seja consistente para que você possa reproduzir os mesmos resultados mais tarde.
Finalmente, clique em Run, e vamos nos antecipar ao resultado final!
Parabéns! Você tem seu próprio humano digital!
Pronto para avançar para cenas com múltiplas pessoas? O WaveSpeedAI também oferece modelos dedicados para isso. Vamos explorá-los juntos!
Geração Multi-Falante
No WaveSpeedAI, procure por wavespeed-ai/infinitetalk/multi. Seus passos são basicamente iguais aos do modelo de pessoa única.
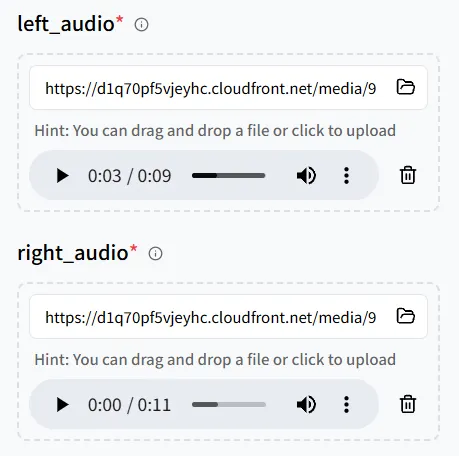
Desta vez, adicione dois arquivos de áudio, depois faça upload de uma imagem com dois humanos digitais para que ambos os personagens possam entregar suas falas.
Preste muita atenção ao emparelhamento entre áudio e posições na imagem:
- left_audio → a pessoa à esquerda na imagem
- right_audio → a pessoa à direita na imagem
Revise o mapeamento cuidadosamente; caso contrário, as vozes poderiam ser vinculadas aos personagens errados.
Modos de Fala
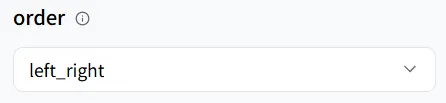
No modelo wavespeed-ai/infinitetalk/multi, ele suporta três modos de fala:
- left_right (esquerda para direita)
- right_left (direita para esquerda)
- meanwhile (fala simultânea)
Da mesma forma, com este modelo, você pode adicionar os detalhes que deseja através do prompt e definir um seed para fácil reprodutibilidade.
E assim, você tem um show de narração com duas pessoas!
Outros Modelos
No WaveSpeedAI, também oferecemos muitos modelos adicionais para você:
- wavespeed-ai/multitalk: Perfeito para “humanos digitais no estilo de música”, permitindo vocais em múltiplas partes e performances mais expressivas.
- wavespeed-ai/infinitetalk/video-to-video: Adicione narração ou narração a vídeos existentes para que os visuais e o áudio permaneçam naturalmente sincronizados.
- wavespeed-ai/song-generation: Crie música do zero para projetar uma trilha sonora e atmosfera personalizadas para seu conteúdo.
Esses modelos também oferecem experiências únicas que são difíceis de replicar em outras plataformas. Seja ousado — experimente-os e compartilhe seu trabalho! Você pode postar na seção Inspiration para se conectar e interagir com outros criadores!

Pensamentos Finais
Nosso mundo está mudando rapidamente e a IA está influenciando cada vez mais nossas vidas diárias. Aderir a métodos antigos apenas aumenta custos, desacelera o progresso e arrisca perder novas oportunidades.
Agora é o momento perfeito para adotar novas tecnologias e aproveitar a conveniência e eficiência que elas oferecem. O WaveSpeedAI oferece suporte de longo prazo para sua criação de conteúdo com tecnologia confiável e um ecossistema sempre crescente.
Onde quer que sua criatividade o leve, o WaveSpeedAI estará lá como sua base confiável e parceiro de confiança.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa

Análise do Vidu Q3: Como se Compara ao Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1 e Grok Imagine Video
