O que é Z-Image-Turbo? O Modelo Text-to-Image Ultra-Rápido de 6B Explicado

Oi, pessoal. Eu sou a Dora. Naquele dia, descobri o Z-Image-Turbo depois de um pequeno problema: eu precisava de texto limpo e legível dentro de uma imagem, e meu setup usual sempre produzia letras estranhas. Não era inutilizável, mas sempre um pouco errado, como um letreiro pintado com pressa. Eu continuava vendo notas sobre um modelo que tratava texto nativamente e rodava em uma placa de 16GB sem dificuldades. Então na semana passada (fev 2026), testei Z-Image-Turbo na minha própria máquina e através de uma API. Resumidamente: é rápido, é prático, e não tenta ser um espetáculo. Essa combinação me chamou atenção.
O que é Z-Image-Turbo?
 Z-Image-Turbo é um modelo de geração de imagens de código aberto com 6B parâmetros, construído para iteração rápida e renderização confiável de texto. Ele aponta para o ponto ideal que muitos de nós realmente precisamos: visuais bons o suficiente, tipografia confiável, e um setup que não força uma estação de trabalho completa. Ele suporta prompts bilíngues (inglês e chinês), e é ajustado para agendamentos de amostragem curtos, que é como mantém a latência baixa.
Z-Image-Turbo é um modelo de geração de imagens de código aberto com 6B parâmetros, construído para iteração rápida e renderização confiável de texto. Ele aponta para o ponto ideal que muitos de nós realmente precisamos: visuais bons o suficiente, tipografia confiável, e um setup que não força uma estação de trabalho completa. Ele suporta prompts bilíngues (inglês e chinês), e é ajustado para agendamentos de amostragem curtos, que é como mantém a latência baixa.
Testei tanto localmente quanto através de um endpoint hospedado. Localmente, rodou em uma GPU de 16GB sem necessidade de malabarismo de dispositivos. Através da API, consegui enviar imagens únicas em uma taxa constante por imagem sem me preocupar com ajuste de lotes. Não está tentando superar os modelos mais cinemáticos: está tentando obter uma imagem sólida com palavras legíveis, rápido.
A Arquitetura de 6B Parâmetros
Não escolho modelos por contagem de parâmetros, mas explica um pouco do comportamento. Com 6B, o Z-Image-Turbo parece intencionalmente limitado: mais leve que as variantes de difusão gigantes, mais pesado que os menores focados em mobile. Na prática, isso significou duas coisas para mim. Primeiro, a memória se manteve previsível, sem OOM de último estágio quando ajustei a resolução. Segundo, os prompts responderam consistentemente. Não tive que super-engenheirar a orientação para manter a tipografia intacta.
O detalhe da arquitetura que mais importava: é treinado para tratar texto-em-imagem como um objetivo de primeira classe, não um acidente feliz. Você consegue perceber quando pede letreiros, mockups de UI, ou fotos de produtos com rótulos. As letras não derretem assim que você adiciona estilo. Não são perfeitas, mas são estáveis o suficiente para que eu parasse de cuidar do prompt.
Amostragem de 8 Passos, Por Que É Tão Rápido
 A maioria das minhas gerações ficou entre 6–10 passos, com 8 como padrão. É aí que a velocidade aparece. Agendamentos de baixo passo frequentemente desabam em detalhes finos, mas aqui os resultados mantinham forma, e o texto permanecia legível na maioria das vezes. Na minha GPU de laptop de 16GB, imagens de 512×512 rotineiramente terminavam em alguns segundos: na API hospedada, a latência se mantinha rápida mesmo com concorrência leve.
A maioria das minhas gerações ficou entre 6–10 passos, com 8 como padrão. É aí que a velocidade aparece. Agendamentos de baixo passo frequentemente desabam em detalhes finos, mas aqui os resultados mantinham forma, e o texto permanecia legível na maioria das vezes. Na minha GPU de laptop de 16GB, imagens de 512×512 rotineiramente terminavam em alguns segundos: na API hospedada, a latência se mantinha rápida mesmo com concorrência leve.
Isso não me economizou tempo no início, ainda mexia com a redação do prompt. Mas depois de algumas tentativas, notei a carga mental cair. Menos tentativas. Menos “deixa mais uma vez” impulsos. Se você trabalha em ciclos curtos (rascunho → ajuste → publicar), a contagem de passos curtos se acumula rapidamente.
Recursos Principais Que Importam
Tento evitar listas de recursos, mas algumas escolhas aqui moldaram como usei o modelo.
Suporte a Prompts Bilíngues (EN/ZH)
Testei prompts em inglês e chinês simples lado a lado, rótulos, letreiros, legendas curtas. O modelo lidou com ambos sem que eu mudasse nada nas configurações. O que se destacou foi a intenção do prompt se mantendo consistente entre idiomas. Quando pedi “um painel de menu limpo com três seções” em chinês, ele me deu a mesma estrutura que o prompt em inglês, não uma reinterpretação vaga. Se você trabalha entre equipes ou mercados, isso reduz o atrito, sem ajuste fino extra, sem hacks específicos de idioma.
Limitações: prompts mistos dentro de uma única imagem às vezes tendiam mais para um idioma no texto renderizado. Eu conseguia guiar com instruções explícitas (ex: “título em EN, subtítulo em ZH”), mas não é perfeito. Ainda assim, para fluxos de trabalho bilíngues, é uma das experiências mais diretas que já tive.
Renderização Nativa de Texto em Imagens
 Essa é a razão pela qual fiquei. Texto parece com texto na maioria das vezes, linhas de base retas, fontes reconhecíveis, e caracteres que sobrevivem a mudanças leves de estilo. Joguei casos de falha comuns contra isso: letreiros curvos, rodapés pequenos, rótulos de faux-UI. Resistiu melhor que os modelos abertos usuais que uso, especialmente em tamanhos modestos. Não é tipografia de capa de revista, mas bom o suficiente para que eu parasse de mascarar e compor toda vez.
Essa é a razão pela qual fiquei. Texto parece com texto na maioria das vezes, linhas de base retas, fontes reconhecíveis, e caracteres que sobrevivem a mudanças leves de estilo. Joguei casos de falha comuns contra isso: letreiros curvos, rodapés pequenos, rótulos de faux-UI. Resistiu melhor que os modelos abertos usuais que uso, especialmente em tamanhos modestos. Não é tipografia de capa de revista, mas bom o suficiente para que eu parasse de mascarar e compor toda vez.
Uma pequena nota prática: prompts de texto curtos e precisos funcionaram melhor. Parágrafos longos ainda ficam embaçados. Se você está projetando muito texto em uma imagem, você provavelmente ainda vai querer uma ferramenta de layout. Mas para logos, tags, banners, e mockups simples de UI, o Z-Image-Turbo tornou o caminho “apenas renderize aqui” viável.
Compatibilidade com 16GB VRAM
Rodei em uma GPU de 16GB sem fragmentação ou um dia inteiro de bingo de dependências. Imagens de 768px quadrados funcionaram: 1024px precisava de um pouco mais de paciência e as configurações de precisão certas, mas ainda bem. Para mim, isso importa mais que uma demo sofisticada. Se o modelo se comporta bem em uma GPU comum de laptop, posso mantê-lo no meu loop diário em vez de girar uma rig separada.
Se você está em 8–12GB, pode precisar reduzir a resolução ou contar com a API. Se você tem 24GB+, terá mais espaço para formatos grandes, mas o valor principal do modelo, resultados rápidos e estáveis com texto, aparece mesmo em tamanhos menores.
Desempenho de Benchmark
Benchmarks não são o trabalho, mas ajudam a verificar as impressões.
#1 em Código Aberto no Leaderboard da Artificial Analysis
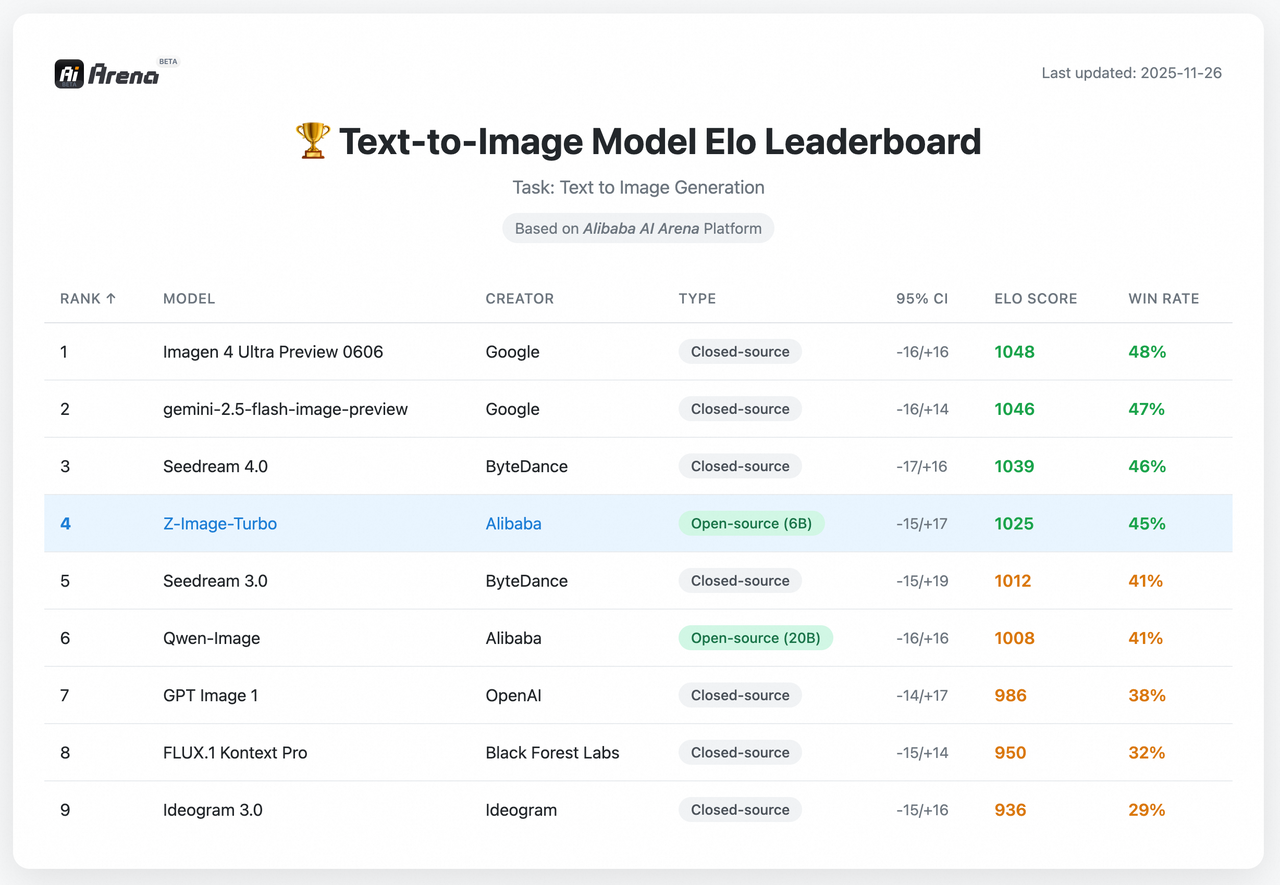 No início de fev 2026, Z-Image-Turbo está listado em ou perto do topo entre modelos de imagem de código aberto no leaderboard da Artificial Analysis (rankings mudam, então trate isso como um snapshot). Isso se alinha com o que senti: velocidade e fidelidade de texto parecem ser seus cartazes de visita. Leaderboards não medem tudo, mas são um proxy útil de como um modelo generaliza além de uma demo curada.
No início de fev 2026, Z-Image-Turbo está listado em ou perto do topo entre modelos de imagem de código aberto no leaderboard da Artificial Analysis (rankings mudam, então trate isso como um snapshot). Isso se alinha com o que senti: velocidade e fidelidade de texto parecem ser seus cartazes de visita. Leaderboards não medem tudo, mas são um proxy útil de como um modelo generaliza além de uma demo curada.
Como Compara com Modelos Proprietários
Contra os grandes modelos hospedados, Z-Image-Turbo negocia fotorrealismo de pico por velocidade, custo, e texto controlável. Se você quer cenas brilhosas e cinemáticas com iluminação intricada, algumas opções proprietárias ainda superam. Se você quer um gráfico limpo com palavras legíveis em dois minutos, esse aqui se mantém bem. Também notei que menos ginástica de prompt era necessária para manter a tipografia intacta, menos tentativa, mais resultado. Para pequenas equipes ou criadores solo, esse equilíbrio geralmente é a diferença entre “experimento legal” e “isso sai hoje.”
Quem Deveria Usar Z-Image-Turbo?
Casos de Uso Ideais
- Gráficos de redes sociais com texto curto e legível (anúncios, banners, miniaturas)
- Mockups de produtos e cenas simples de UI onde rótulos precisam sobreviver
- Docs internos e slides que se beneficiam de visuais rápidos sem um desvio de design
- Ativos bilíngues onde a flexibilidade de linguagem do prompt economiza idas e vindas
- Iteração rápida em sprints, quando você quer 3–5 variantes decentes rápido e seguir em frente
Nos meus testes, a vitória não foi apenas velocidade bruta. Foi previsibilidade. Conseguia ajustar estilo ou layout sem perder o texto completamente, o que significava menos reinicializações.
Quando Escolher Outros Modelos Em Vez Disso
- Fotorrealismo de alta qualidade para impressões em larga escala ou anúncios, alguns modelos proprietários ainda entregam um acabamento mais polido.
- Parágrafos longos ou sistemas tipográficos complexos, use uma ferramenta de layout ou pós-processamento.
- Composição pesada ou consistência entre múltiplas imagens (mesmo personagem em diferentes cenas), você vai querer um modelo com identidade forte e controles de multi-shot.
Se seu trabalho tende mais para narrativa cinemática ou estudos de iluminação intricados, você pode preferir uma ferramenta diferente. Z-Image-Turbo é mais um carro diário que um carro de show.
Como Começar
Quick Start da WaveSpeed API
Testei a WaveSpeed API primeiro para evitar desvio de setup. Autenticação era padrão, e o corpo da requisição era simples: prompt, steps (fiquei com 8), tamanho, e uma seed se quiser reprodutibilidade. Os padrões eram sensatos. Se você está testando renderização de texto, comece com frases curtas e uma resolução média, depois escale assim que gostar da aparência. Fui de ideia para primeira imagem usável em menos de cinco minutos, a parte mais rápida desse experimento inteiro.
Se você prefere local, o modelo rodou limpo em uma GPU de 16GB com configurações de precisão típicas. Fique atento ao VRAM conforme você cruza 768px. Se atingir limites, reduz passos antes de reduzir orientação: amostragem de 8 passos é o ponto aqui.
Visão Geral de Preços ($0.005/imagem)
 Através do WaveSpeed, o preço saiu cerca de $0.005 por imagem em configurações padrão. É difícil reclamar disso para rascunhos, ativos de redes sociais, ou experimentos rápidos. Se você está gerando em escala, fique de olho em limites de concorrência, latência se manteve baixa para mim com pequenos picos, mas não fiz stress test além de um punhado de trabalhos paralelos.
Através do WaveSpeed, o preço saiu cerca de $0.005 por imagem em configurações padrão. É difícil reclamar disso para rascunhos, ativos de redes sociais, ou experimentos rápidos. Se você está gerando em escala, fique de olho em limites de concorrência, latência se manteve baixa para mim com pequenos picos, mas não fiz stress test além de um punhado de trabalhos paralelos.
Isso funcionou para mim, sua quilometragem pode variar. Se você está malabarisando prompts bilíngues ou apenas quer texto que pareça que pertence à imagem, vale a pena uma olhada. A última coisa que notei, quase por acaso: parei de screenshootar e editar repetidamente. Menos desvios. Isso parecia ser o ponto.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
