Preços da API WaveSpeed: Como os Créditos Funcionam + Uma Calculadora de Custos Simples

Olá, lembra de mim? Eu sou a Dora.
Não comecei pensando em preços. Apenas queria uma tarde tranquila de teste. Mas no meio da montagem de um pequeno protótipo (janeiro de 2026), minhas notas começaram a desviar de “isso funciona?” para “quanto custará se isso realmente sair do forno?” É normalmente o momento em que faço uma pausa. O preço da API do WaveSpeed não é chamativo. É aquele tipo que se esconde nos detalhes, tamanho de contexto, tentativas, tamanho de dados. Nada disso é dramático, mas soma. Aqui está como tenho dimensionado isso, com números reais onde consigo e estimativas simples onde não consigo. Se você trabalha como eu, enviando pequenos experimentos que podem crescer, isso pode ajudá-lo a planejar sem adivinhar.
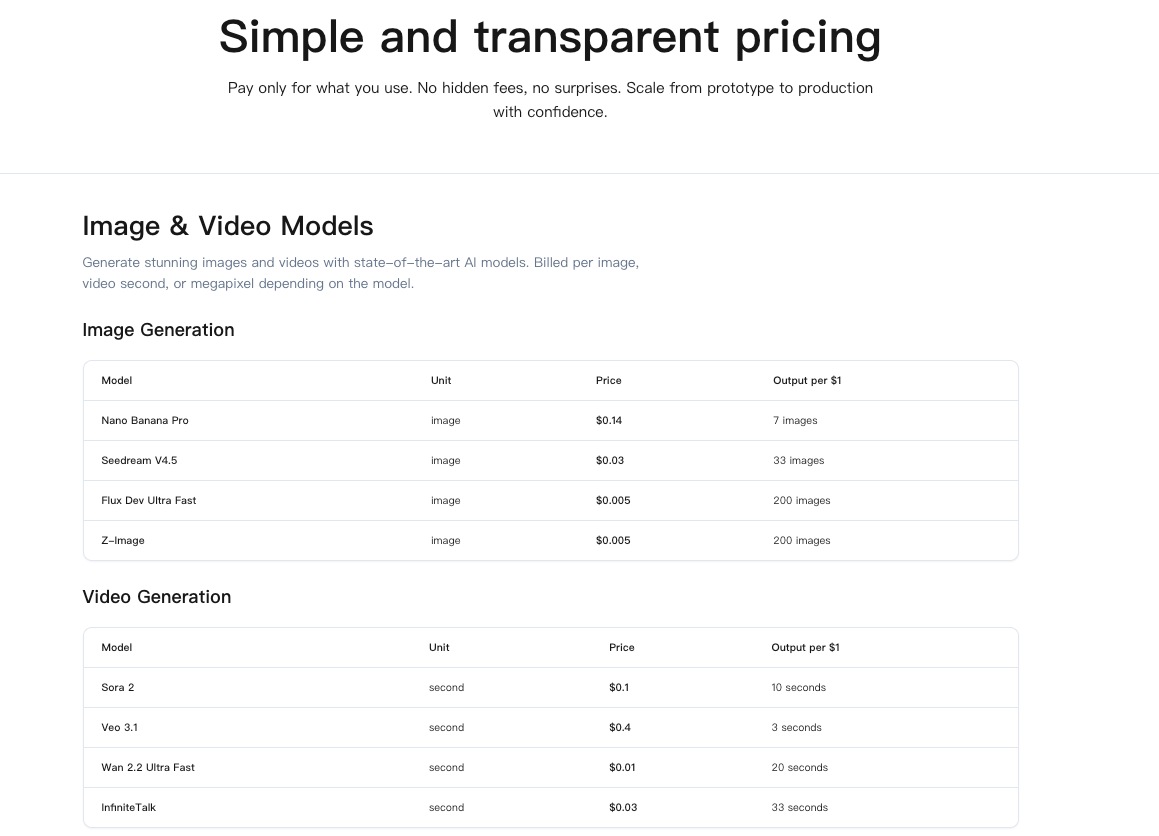
Como o preço é medido
Não consegui encontrar um único número que capturasse o preço da API do WaveSpeed de forma clara. Então trato como três categorias:
- Chamada base: a taxa para acessar um endpoint uma vez. Pense nisso como a “taxa de entrada”.
- Carga de trabalho variável: a parte que cresce com o que você envia e pede, tokens, tamanho de arquivo, nível de modelo, ferramentas usadas, comprimento do contexto.
- Extras: armazenamento, saída de dados e qualquer coisa que persista ou mova dados para fora.
Para planejamento, uso uma fórmula simples:
Custo estimado = (execuções × base_por_chamada) + (volume_entrada × taxa_entrada) + (volume_saída × taxa_saída) + (dados_armazenados × taxa_armazenamento × meses) + (egress_GB × taxa_egress)
É chato, e é por isso que funciona. Mantenho as taxas em uma pequena planilha e ajusto conforme os documentos mudam. Se você está fazendo isso também, adicione aos favoritos as páginas oficial de preços e limites: elas mudam frequentemente, e pequenas mudanças lá se propagam por tudo mais.
Fatores que multiplicam o custo
Algumas coisas aumentam silenciosamente os totais. Nenhuma delas é uma “pegadinha” por si só. Juntas, são a razão pela qual os orçamentos mudam.
- Prompts longos e saídas generosas: Cada 1k token extra aparece na conta. Eu limito os tokens de saída máxima a menos que haja uma razão para não fazer isso.
- Tentativas e fallbacks: Ótimos para confiabilidade, difíceis no custo se deixados abertos. Uso backoff exponencial com um teto firme.
- Arquivos grandes: Transcrição, visão ou análise de PDF ficam caros quando você joga grandes ativos neles. Eu faço downsampling ou chunking.
- Cadeias de ferramentas: Uma ação do usuário pode se expandir para múltiplas chamadas de API. É fácil esquecer que cada etapa da ferramenta é outro custo faturável.
- Concorrência: Paralelismo é ótimo para latência, mas multiplica custos durante testes de carga. Aumento tarde, não cedo.
- Registro e capturas: Útil para depuração. Caro se você armazena tudo para sempre. Mantenho logs estruturados finos e giro agressivamente.
Se você medir nada mais, meça tokens, tamanhos de arquivo e contagens de tentativas. Esses três explicam a maioria das surpresas para mim.
3 cenários reais (10 / 50 / 100 execuções)
Estes não são números oficiais. São minhas estimativas de planejamento de um protótipo de janeiro de 2026. Substitua suas próprias taxas: a forma deve se manter.
Taxas de espaço reservado assumidas (apenas para matemática):
- Base por chamada: $0,002
- Tokens de entrada: $0,50 por 1M tokens ($0,0005 por 1k)
- Tokens de saída: $1,00 por 1M tokens ($0,001 por 1k)
- Armazenamento: $0,02 por GB-mês
- Egress: $0,09 por GB
Cenário A: prompt curto → resposta curta
- Entrada média: 600 tokens: saída: 200 tokens: sem arquivos.
- Por execução: base $0,002 + entrada (0,6k × $0,0005 = $0,0003) + saída (0,2k × $0,001 = $0,0002) = $0,0025
- 10 execuções ≈ $0,025: 50 execuções ≈ $0,125: 100 execuções ≈ $0,25
Como se sentiu: basicamente gratuito até que as tentativas começassem. Quando permiti 3 tentativas, os custos quase dobraram durante uma hora instável. Limitei a 1 tentativa e enfileirei o resto.
Cenário B: resumo de um PDF médio
- Entrada média: 6.000 tokens de texto em chunks: saída: 1.000 tokens.
- Por execução: base $0,002 + entrada (6k × $0,0005 = $0,003) + saída (1k × $0,001 = $0,001) = $0,006
- 10 execuções ≈ $0,06: 50 execuções ≈ $0,30: 100 execuções ≈ $0,60
Nota: o custo oculto aqui foi a extração. Quando enviei PDFs completos em vez de chunks de texto limpos, a etapa de preparação adicionou tempo e às vezes uma segunda chamada. Texto em primeiro lugar foi mais barato e mais previsível.
Cenário C: visão leve + resumo + exportação
- Imagem: 1,5 MB em média: entrada 2.000 tokens: saída 500 tokens: armazenar resultado por 1 mês: exportar 0,5 GB total entre execuções.
- Por execução (API): base $0,002 + entrada (2k × $0,0005 = $0,001) + saída (0,5k × $0,001 = $0,0005) = $0,0035
- Armazenamento: se cada resultado adiciona ~200 KB de artefatos, 100 execuções ≈ 20 MB = 0,02 GB × $0,02 ≈ $0,0004/mês (negligenciável)
- Egress: 0,5 GB × $0,09 = $0,045 total entre o lote
- 10 execuções ≈ $0,035 + armazenamento minúsculo: 50 execuções ≈ $0,175 + egress se você exportar: 100 execuções ≈ $0,35 + ~$0,045 egress
O que me surpreendeu: o egress foi o único item de linha que senti. Não enorme, mas notável quando exportei mídia para clientes.
Em algum ponto, parei de querer estimar e apenas queria que as coisas permanecessem previsíveis.
É por isso que construímos o WaveSpeed — para executar experimentos como esses sem estar constantemente observando contagens de tokens, tentativas ou linhas de egress surpresa.
Se você está testando ideias que podem escalar, experimente.
Tabela da calculadora de custos
Mantenho uma pequena planilha. Não é sofisticada, apenas matemática honesta. Se você quiser um esboço rápido, coloque seus números neste padrão.
| Execuções | Base/chamada ($) | Tokens entrada/execução | Tokens saída/execução | Taxa entrada ($/1k) | Taxa saída ($/1k) | Egress (GB) | Egress $/GB | Total est. ($) |
|---|---|---|---|---|---|---|---|---|
| 10 | 0,002 | 600 | 200 | 0,0005 | 0,001 | 0 | 0,09 | (10×0,002) + (10×0,6×0,0005) + (10×0,2×0,001) + (0×0,09) |
| 50 | 0,002 | 6000 | 1000 | 0,0005 | 0,001 | 0 | 0,09 | (50×0,002) + (50×6×0,0005) + (50×1×0,001) |
| 100 | 0,002 | 2000 | 500 | 0,0005 | 0,001 | 0,5 | 0,09 | (100×0,002) + (100×2×0,0005) + (100×0,5×0,001) + (0,5×0,09) |
Nota: Substitua as taxas de espaço reservado pelos números atuais da página de preços do WaveSpeed. Mantenho versões na planilha, apenas uma coluna de data, então me lembro do que mudou e quando.
Como reduzir desperdício
O que mais me ajudou não foi magia, apenas garantias que duraram:
- Defina tokens de saída máximos. Respostas longas são legais: contas previsíveis são melhores.
- Aparar prompts. Reutilizar prompts do sistema e IDs de referência em vez de colar paredes de texto.
- Armazenar resultados intermediários em cache. Não re-incorporar ou re-resumir conteúdo inalterado.
- Lote onde for seguro. Dez pequenas chamadas podem ser mais baratas do que uma gigante, ou o oposto. Teste ambas.
- Dimensionar corretamente os arquivos. Fazer downsampling de imagens, extrair texto de PDFs antes de enviar.
- Limitar tentativas e timeouts. Confiabilidade é boa: loops infinitos não são.
- Registrar escassamente. Manter hashes e IDs: descartar cargas úteis brutas a menos que você realmente precise delas.
Dicas de faturamento em equipe
 Eu tropeçei em custos de equipe mais de uma vez. Alguns hábitos me salvaram:
Eu tropeçei em custos de equipe mais de uma vez. Alguns hábitos me salvaram:
- Chaves separadas por ambiente e projeto. Torna a atribuição óbvia.
- Marcar solicitações com IDs de usuário ou recurso. Custo pós-hoc por recurso é ouro durante o planejamento.
- Painel compartilhado com snapshots semanais. Ninguém lê ruído diário.
- Orçamentos suaves no nível do projeto. Quando 80% é atingido, os recursos desaceleram ou mudam para um caminho mais barato.
- Uma pessoa possui atualizações de preços. Não para bloquear, apenas para reduzir desvio.
- Manter um runbook: o que reduzir primeiro quando os custos aumentam (tokens de saída, concorrência ou ferramentas opcionais).
Garantias de orçamento
Aqui está o que coloquei em prática antes de qualquer coisa enfrentar usuários reais:
- Estimador de voo de verificação: uma pequena função que calcula o custo estimado por ação e o adiciona aos logs.
- Tetos por ação: se uma única execução se projeta acima de $X, ela recusa educadamente.
- Caps diários e mensais com alertas. Os alertas vão para um canal tranquilo que alguém realmente observa.
- Modo lento: um sinalizador que reduz pela metade a concorrência sob pressão orçamentária.
- Sinalizadores de recurso para caminhos pesados: desligar visão ou recursos de contexto longo sem reimplantar.
- Cadência de revisão: 15 minutos a cada duas sextas-feiras para atualizar as taxas da página de preços oficial.
 Honestamente, nada disso é glamouroso. Mas o preço da API do WaveSpeed se comporta quando você faz. A coisa engraçada é que uma vez que as garantias estão em vigor, a ferramenta desaparece de novo no fundo, exatamente onde eu gosto.
Honestamente, nada disso é glamouroso. Mas o preço da API do WaveSpeed se comporta quando você faz. A coisa engraçada é que uma vez que as garantias estão em vigor, a ferramenta desaparece de novo no fundo, exatamente onde eu gosto.
Eu ainda me pego verificando as contagens de tokens por hábito, depois fecho a aba quando os números parecem razoáveis. Hábitos antigos. Pequenos alívios. Vou com isso.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
