Baixar Modelo LTX-2: Arquivos Hugging Face, Tamanhos e Estrutura de Pastas

A primeira vez que procurei por um download do LTX-2, não foi um grande plano. Eu apenas queria executar um pequeno lote através do ComfyUI e continuava tropeçando nos mesmos dois problemas: downloads lentos que travavam em 92%, e uma mensagem criptografada “Model not found” assim que finalmente tinha os arquivos. Nada dramático. Apenas o tipo de transtorno repetido que te faz parar e organizar o fluxo de trabalho.
Passei alguns dias no início de janeiro de 2026 testando diferentes fontes, formatos (NVFP4 vs NVFP8) e estruturas de pasta em uma caixa com GPU de 24GB. Nada de glamouroso, apenas execuções suficientes para ver o que era sólido versus frágil. Aqui está o caminho que reduziu a bagunça para mim, com notas que você pode ler rapidamente e aproveitar.
Fontes Oficiais de Download do LTX-2 (Cartão do Modelo Hugging Face)
 Eu não procuro por espelhos. Se um modelo importa para meu fluxo de trabalho, quero que o caminho seja entediante e confiável. Para o LTX-2, isso significa começar no cartão oficial do modelo Hugging Face.
Eu não procuro por espelhos. Se um modelo importa para meu fluxo de trabalho, quero que o caminho seja entediante e confiável. Para o LTX-2, isso significa começar no cartão oficial do modelo Hugging Face.
O que procuro antes de clicar no download:
- Publicador: É a organização verificada ou o autor vinculado ao LTX-2? Eu verifico o emblema da organização e se outros repositórios no namespace parecem ativos e consistentes.
- Licença e termos: Algumas variantes do LTX-2 são fechadas ou têm limites de uso. Se aceitar termos requer um token, prefiro fazer isso uma vez do que depurar erros de autenticação depois.
- Lista de artefatos: Eu procuro pelo modelo principal, quaisquer codificadores e uma variante destilada ou quantizada. Nomes de arquivo claros são melhores que nomes inteligentes.
- Instruções: Se o cartão se vincula a ComfyUI ou documentação específica de nós, eu sigo isso primeiro. Uma linha sobre as pastas esperadas pode economizar meia hora de adivinhação.
Dica prática: use a CLI do Hugging Face com credenciais definidas. Um repositório fechado não será puxado sobre git-lfs raw sem um token, e essa é a maneira mais rápida de acabar com arquivos parciais e sem erros até você tentar carregá-los.
pip install huggingface_hub git-lfs
huggingface-cli login # cole seu tokenEu sei, óbvio. Mas o número de vezes que vi um 403 silencioso se transformar em “model not found” a jusante é… não-zero.
Lista de Arquivos e Tamanhos (modelo principal / codificador / destilado)
Eu não memorizo tamanhos de arquivo. Eu apenas preciso de uma aproximação para planejar disco e decidir qual variante puxar primeiro. Aqui está o que realmente vi em drops recentes do LTX-2. Seu repositório pode diferir, sempre confie no cartão do modelo sobre minhas notas.
Artefatos típicos que você verá:
- Checkpoint do modelo principal (frequentemente
.safetensorsou um formato específico de tempo de execução): ~2,5–6,0 GB. Maior se incluir cabeçalhos extras ou multi-precisão; menor se quantizado. - Codificador de texto/imagem (CLIP ou similar): ~400 MB–1,5 GB. Algumas compilações agrupam isso; outras o enviam como um arquivo separado.
- VAE ou adaptador latente (se aplicável): ~100–500 MB.
- Variante destilada: ~1–3 GB. Mais rápida e leve, às vezes com saídas ligeiramente mais suaves. Bom para prototipagem.
- Variantes quantizadas (NVFP8/NVFP4): o tamanho varia, mas espere 30–60% menos disco do que precisão total.
Padrões de nomenclatura que observo:
ltx-2.safetensors(principal)ltx-2-encoder.safetensorsouopen_clip-vit-…(codificador)ltx-2-vae.safetensors(se separado)ltx-2-distilled-…(menor, mais rápido)ltx-2-nvfp8/ltx-2-nvfp4(específico do formato)
Se o disco está apertado, puxo o destilado primeiro, valido meu pipeline, depois puxo o modelo completo. Não é apenas sobre velocidade: reduzir a carga cognitiva da primeira execução me ajuda a testar prompts e nós sem lutar contra VRAM imediatamente.
Estrutura de Pasta do ComfyUI para LTX-2 (Caminhos Exatos)
É aqui que tropecei no primeiro dia: meus arquivos estavam bem, mas ComfyUI não sabia onde procurar. Diferentes nós personalizados esperam locais ligeiramente diferentes, mas os padrões abaixo foram seguros para mim.
Em uma instalação padrão de ComfyUI (sem sobreposições de nó personalizado):
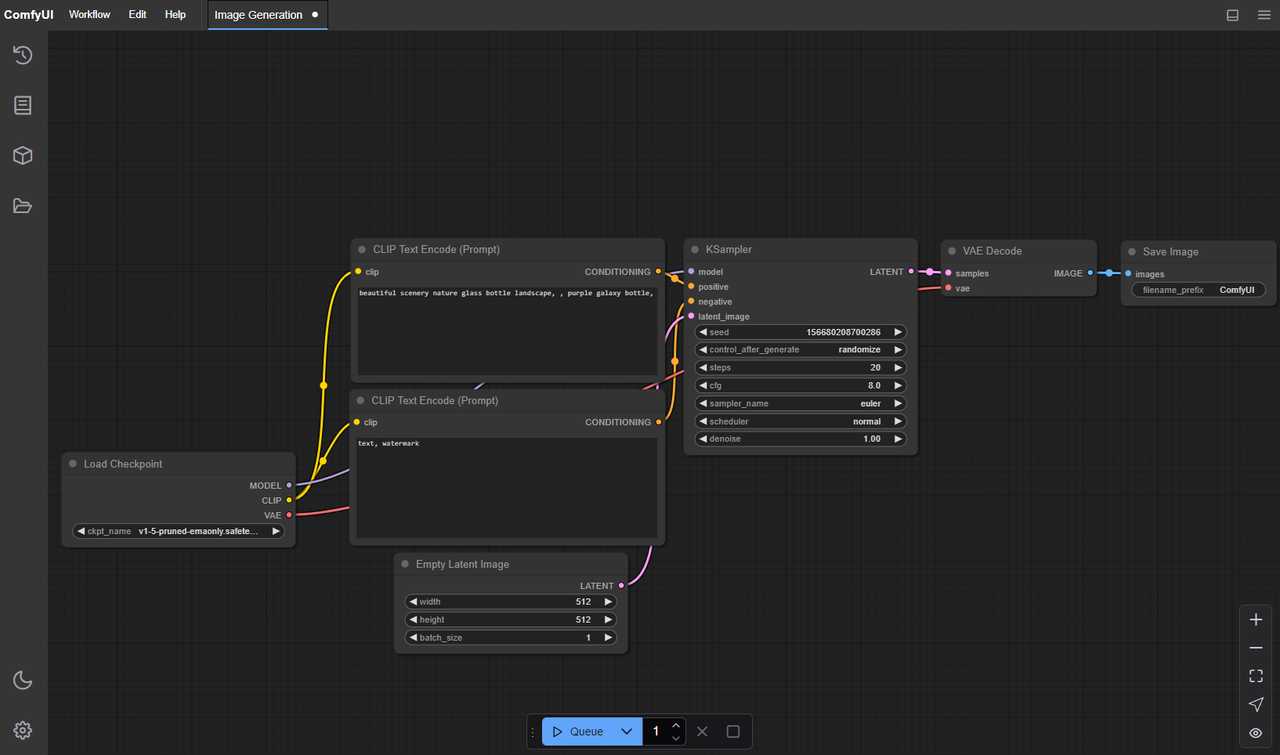
- Checkpoint do modelo principal:
ComfyUI/models/checkpoints/LTX-2.safetensors - Codificador de texto/imagem (CLIP ou similar):
ComfyUI/models/clip/LTX-2-encoder.safetensors- Algumas compilações usam nomenclatura open_clip: coloque-as em
models/clip/também.
- Algumas compilações usam nomenclatura open_clip: coloque-as em
- VAE (se separado):
ComfyUI/models/vae/LTX-2-vae.safetensors - LoRA/patches (se usar):
ComfyUI/models/loras/
Se você estiver usando nós que dependem de arquivos TensorRT ou engine:
ComfyUI/models/trt/ltx-2/*.engineComfyUI/models/unet/ltx-2/*.engine
Dois hábitos entediantes mas úteis:
- Corresponda exatamente aos nomes de arquivo que seu nó espera. Mantenho nomes curtos e removo espaços.
- Depois de mover arquivos, use a atualização de modelo do ComfyUI ou reinicie. O recarregamento a quente funciona às vezes: uma reinicialização completa é mais consistente.
Se você usar um disco externo ou uma pasta compartilhada de modelos, defina Caminhos Extras de Modelo do ComfyUI para que não verifique silenciosamente a unidade errada. A sensibilidade de caso no Linux já me mordeu mais de uma vez.
Pesos NVFP4 vs NVFP8: Qual Baixar
 Eu estava curioso se NVFP4 valia a compressão extra. Resposta curta: talvez, se você estiver apertado em VRAM e seus nós realmente o suportarem.
Eu estava curioso se NVFP4 valia a compressão extra. Resposta curta: talvez, se você estiver apertado em VRAM e seus nós realmente o suportarem.
Aqui está como se sentiu na prática em minha caixa (GPU classe Hopper, builds de janeiro de 2026):
NVFP8
- Equilíbrio: Bom termo médio. Notavelmente menor em memória do que precisão total com desvio de saída mínimo.
- Compatibilidade: Melhor. Mais nós e tempos de execução aceitam FP8 do que FP4 agora.
- Quando eu o escolho: Execuções diárias onde quero estabilidade sobre o menor volume.
NVFP4
- Volume: Menor. Permitiu-me aumentar a resolução ou contexto em um entalhe onde FP8 não permitiria.
- Desvio: Ligeiramente mais artefatos ou suavidade em casos extremos. Nem sempre, mas apenas o suficiente para que eu note.
- Compatibilidade: Mais seletiva. Alguns carregadores caem ou falham se não detectarem os kernels certos.
- Quando eu o escolho: Rascunhos rápidos, buscas em grade ou quando o fluxo de trabalho é estritamente suportado pelo caminho FP4 do nó.
Uma coisa mais: esses formatos geralmente assumem que você está em uma pilha NVIDIA que pode acelerá-los adequadamente. Se seu nó não disser explicitamente “NVFP4/NVFP8 suportados”, padrão para precisão total ou uma compilação destilada .safetensors. Perseguir ganhos marginais não vale a pena o crash misterioso no meio da renderização.
Aceleração de Download do LTX-2 e Dicas de Verificação de Checksum
Eu trato grandes puxadas de modelos como qualquer outro trabalho de arquivo grande: acelero e depois verifico.
Aceleração que realmente ajudou:
- Aceleração de transferência Hugging Face: defina variável de ambiente
HF_HUB_ENABLE_HF_TRANSFER=1antes de usarhuggingface_hub. Isso ativa seu backend acelerado onde disponível.
aria2c para chunks paralelos:
aria2c -x 16 -s 16 -k 1M -cO sinalizador -c retoma downloads parciais com clareza quando minha conexão falha em 97%.
puxadas ajustadas do git-lfs
git lfs installe depoisgit clone.- Seguindo o guia de instalação do Git LFS, se for um repositório enorme, às vezes uso sparse-checkout para evitar puxar exemplos que não usarei.
Verificação que realmente faço (e não pulo mais)
Compare SHA256 do cartão do modelo (ou arquivos .sha256 do repositório) contra seu arquivo local.
- macOS/Linux:
shasum -a 256 - Windows:
certutil -hashfile SHA256
Verificação de senso comum de tamanho de arquivo
- Se o tamanho esperado é 4,2 GB e vejo 3,3 GB, eu paro aí. Arquivos parciais ocasionalmente “carregam”, depois geram erros de lixo depois.
Pequeno hábito que economiza tempo: mantenho um pequeno README.txt ao lado dos arquivos do modelo com a URL de origem, data e hash. Quando revisito três meses depois, não preciso fazer engenharia reversa das escolhas do meu eu anterior.
Correções “Model Not Found”
Este erro consumiu uma hora que não vou recuperar. Aqui estão as correções que realmente moveram a agulha para mim:
- Pasta errada: ComfyUI espera checkpoints em
models/checkpoints/, codificadores emmodels/clip/e VAEs emmodels/vae/. Coloque-os em qualquer outro lugar e o scanner pode ignorá-los. - Incompatibilidade de nome de arquivo: Alguns nós procuram por um basename específico. Se o nó disser
ltx-2.safetensors, não o chame deLTX-2 (final).safetensors. Eu renomeio agressivamente. - Sensibilidade de caso:
ltx-2.safetensors≠LTX-2.safetensorsno Linux. Pergunte-me como sei. - Indexação de cache: Atualize modelos ou reinicie ComfyUI após mover arquivos. O índice nem sempre é em tempo real.
- Dependência faltante: Se o nó espera um codificador externo e você apenas baixou o modelo principal, obterá um erro vago. Puxe o codificador listado no cartão do modelo e tente novamente.
- Modelo fechado sem token: Se clonou sem fazer login (ou seu token expirou), arquivos locais podem ser stubs. Faça login novamente com
huggingface-cli logine repuxe. - Nós personalizados e caminhos alternativos: Alguns nós substituem pastas padrão. Verifique seu README para caminhos esperados ou variáveis de ambiente. Em caso de dúvida, coloque um link simbólico de seu diretório de modelos compartilhados para o caminho local esperado.
Quando fico preso, aponto temporariamente o nó para um modelo pequeno e conhecido para apenas confirmar que o carregador funciona. Se o pequeno carrega, o bug vive nos arquivos LTX-2, não no meu ambiente.
Pule Downloads do LTX-2 Usando WaveSpeed
Tentei uma rota diferente em um laptop de viagem: ignore downloads locais completamente e execute o LTX-2 através do WaveSpeed. Ele transmite ou hospeda os pesos remotamente para que você possa conectar um gráfico semelhante ao ComfyUI sem estacionar 10+ GB no seu disco.
 O que funcionou para mim:
O que funcionou para mim:
- A integração foi leve. Apontei o gráfico para seu endpoint LTX-2 e não toquei em pastas locais.
- Inicializações frias eram mais lentas (a primeira execução inicia uma sessão), mas execuções quentes pareciam normais para lotes pequenos.
- Mantinha o ventilador do meu laptop de uivar. Apenas isso tornava útil na estrada.
Trade-offs que notei:
- Latência: Há uma pequena sobrecarga, mais óbvia com muitas execuções curtas. Para renderizações longas, parei de notar.
- Controle: Você desiste de algum pinning de versão. Eles mantêm modelos corrigidos, o que é bom, até que você quer reproduzir um resultado mais antigo.
- Custo/quotas: Não é “gratuito como um download”. Se você está em um orçamento apertado ou precisa de muito trabalho em lote, local ainda vence.
- Privacidade: Mantenho prompts e ativos sensíveis localmente. Para trabalho público ou de teste, tenho certeza.
Quem pode gostar disso: pessoas testando LTX-2 em máquinas com menos poder, ou qualquer um que queira esboçar um fluxo de trabalho antes de se comprometer com uma configuração local completa. Se você tem VRAM rico e se importa com exatidão reprodutível, instalações locais ainda parecem melhores.
Eu não esperava gostar, mas para experimentos rápidos, pular o download foi um pequeno alívio.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
