Instalar LTX-2 no ComfyUI no Windows: Guia de Configuração CUDA e Primeira Execução

I’ll translate this article to Portuguese now.
Oi, sou Dora. Naquele dia, eu só queria fazer uma passagem rápida de texto-para-vídeo para um esboço, e continuava vendo LTX-2 mencionado em threads do ComfyUI. No meio da manhã eu estava olhando para um gráfico em branco e uma pasta chamada “ltx”, me perguntando se tinha me inscrito novamente em uma roleta de driver.
Anotei enquanto configurava no Windows 11. Se você está procurando por “ltx-2 comfyui windows” porque está no meio de uma instalação, eu já passei por isso. Aqui está o que ajudou.
Lista de Verificação Pré-Instalação (GPU / CUDA / versões de driver)
Uma verificação rápida antes de começar economiza a hora que você gastará perseguindo erros de DLL depois:
- GPU: Um cartão NVIDIA com pelo menos 12 GB de VRAM tornou o LTX-2 utilizável para mim com configurações modestas (largura 512–768, clipes curtos). 8 GB podem funcionar com configurações muito conservadoras, mas é apertado e frequentemente frustrante.
- Drivers: Atualize para um driver recente Game Ready ou Studio (usei 552.xx).
- CUDA: Você não instala um kit CUDA completo para ComfyUI portátil. Você só precisa das DLLs de tempo de execução que acompanham o PyTorch. É por isso que corresponder à compilação PyTorch+CUDA é importante (cu121 ou cu122, etc.).
- Python: A compilação portátil do ComfyUI vem com seu próprio Python. Se você executar um venv personalizado, mantenha-o alinhado com a wheel do PyTorch que escolher.
- VC++ Redistributable: Instale/repare o Microsoft Visual C++ Redistributable mais recente. É uma correção silenciosa para erros de DLL estilo “entrada de procedimento”.
Duas verificações de sanidade que faço antes de qualquer modelo pesado:
nvidia-smié executado em um terminal e mostra o driver corretamente.python -c "import torch: print(torch.version, torch.cuda.is_available())"retorna True para CUDA em qualquer ambiente que o ComfyUI usará.
Nada disso garante uma navegação suave, mas reduz os modos de falha.
Atualizar ComfyUI para Versão Pronta para LTX-2
O que fiz:
- Atualize ComfyUI primeiro. Se você estiver na compilação portátil do GitHub, pegue a versão mais recente ou faça git pull e execute os scripts de atualização.
- Abra o ComfyUI Manager (se você o usar) e atualize as dependências principais. Deixei o Manager reconstruir o venv quando solicitado.
- Instale o pacote de nós LTX-2 do repositório oficial. O nome varia (já vi repositórios estilo “ComfyUI-LTXVideo”/“LTX-Video”): usei o vinculado da página oficial do modelo. Se a descrição de um repositório diz que suporta LTX-Video v2/LTX-2, esse é o que você quer.
Por que isso importa na prática:
- LTX-2 depende de recursos do PyTorch 2.3+ e compilações CUDA 12.x. Misturar torch antigo (cu118) com nós novos é uma forma rápida de bater em erros de importação criptografados.
- Alguns pacotes expõem alternadores FP8/BF16 de forma diferente. Corresponder ao pacote de nós e à versão do ComfyUI evita entradas incompatíveis e gráficos sem saída.
Resisti à instalação limpa no início, parecia desnecessária. Depois comparei: a compilação nova iniciou na primeira tentativa; a mais antiga continuava pedindo ops ausentes. Não senti falta da adivinhação.
Colocação de Arquivo de Modelo (passo a passo)
É aqui que geralmente perco tempo. Diferentes nós esperam pastas diferentes. Aqui está o que funcionou para mim com o pacote de nós LTX-2 que instalei, e o padrão geral mantém mesmo se os nomes de suas pastas forem diferentes.
-
Encontre os caminhos esperados do nó. No ComfyUI, abra o nó do carregador LTX e passe o mouse sobre qualquer entrada de arquivo. A maioria dos pacotes mostra o caminho relativo que estão verificando (por exemplo,
models/ltx,models/checkpoints, ou uma subpasta personalizada comomodels/ltx_video). Se tiver dúvidas, verifique o README do repositório. Eles geralmente listam o diretório exato. -
Baixe os pesos LTX-2 da fonte oficial (frequentemente Hugging Face, vinculado da página do modelo). Você normalmente receberá um arquivo principal
.safetensorsou.pthmais configurações. Alguns repositórios dividem codificadores de texto/VAEs separadamente; outros os agrupam. -
Coloque os arquivos exatamente onde o nó procura. Para meu pacote:
ComfyUI/models/ltx_video/continha o arquivo do modelo principal. Se seu pacote dizmodels/checkpoints, use isso. O nome deve aparecer no menu suspenso do nó após uma reinicialização ou rescan. -
Opcional: codificador de texto / VAE. Se o nó expuser entradas separadas para codificadores ou um VAE, siga sua orientação. Muitos nós LTX-2 escondem isso e agrupam componentes internamente. Se for exposto, coloque arquivos CLIP/Tokenizer em
models/clipoumodels/text_encodersconforme instruído pelo README. -
Reinicie o ComfyUI. Eu sei, é óbvio. Mas o recarregamento a quente nem sempre faz rescan nessas pastas, e eu já olhei para um menu suspenso vazio mais vezes do que admito.
Pequena observação: se o Windows marcar os arquivos baixados como bloqueados (clique direito > Propriedades > Desbloquear), limpe isso. Tive Python recusando-se a tocar em arquivos “baixados da internet” em configurações mais rigorosas.
Erros Comuns do Windows (DLL / permissões)
“DLL load failed while importing …” ou nvrtc64_X.dll faltando
- Causa: A compilação do PyTorch não correspondia ao tempo de execução CUDA esperado pelo pacote de nós, ou o ambiente misturou cu118 e cu12x.
- Correção: Reinstale/confirme PyTorch 2.3+ com cu121/cu122 dentro do ambiente do ComfyUI. Se você executar portátil, deixe o Manager lidar. Atualizar drivers NVIDIA ajudou uma vez.
“Access is denied” ao escrever quadros/vídeo
- Causa: Apontei o nó SaveVideo para uma pasta sincronizada com permissões agressivas (OneDrive).
- Correção: Escreva primeiro em um caminho local não sincronizado (por exemplo,
ComfyUI/output/ltx_test). Mova o arquivo depois.
Problemas de caminho longo no descompactar
- Causa: Limites de comprimento de caminho do Windows mais subpastas profundas do ComfyUI.
- Correção: Ative caminhos longos no Windows (Política de Grupo Local ou registro) ou descompacte mais perto de
C:\.
Antivírus verificando quadros temp durante renderização
- Sintoma: Travamento ou entrecorte do ComfyUI durante a codificação.
- Correção: Adicione uma exclusão para a pasta ComfyUI ou apenas o caminho temp de saída.
“Could not find model” mesmo com pasta correta
- Correção: Reinicie o ComfyUI. Se ainda não aparecer, verifique a pasta exata esperada do nó. Alguns nós LTX-2 procuram em um nome de diretório personalizado. Corresponda exatamente.
Também encontrei o clássico “funciona uma vez, falha na próxima execução”. Para mim, isso se resumiu a uma aba do navegador tentando visualizar o MP4 parcial enquanto o nó de codificação ainda estava escrevendo. Mudei para escrever em um nome de arquivo novo por execução. A instabilidade desapareceu.
Fluxo de Trabalho do Teste de Primeira Inferência
Mantive o primeiro gráfico pequeno. Nada elaborado, apenas o suficiente para confirmar o pipeline.
O que construí:
- Um nó Prompt com uma única frase (10–20 tokens). Mantenha simples.
- Nó Carregador LTX-2 apontando para o modelo baixado.
- Um nó Amostrador/Agendador LTX-2 (como seu pacote o nomeia) com poucos passos.
- Um caminho Decodificar/Montar Vídeo que escreve quadros para um nó SaveVideo (MP4, H.264 é bom para um teste de fumaça).
Parâmetros que não me enfrentaram:
- Resolução: 512×288 ou 640×360
- Quadros: 8–16 quadros (0,5–1 segundo)
- Passos: 6–12
- Orientação/CFG: ponto médio (5–7)
- Seed: número fixo (torna a solução de problemas menos ruidosa)
- Precisão: FP16 (padrão) a menos que seu nó sugira BF16 em Ada: ambos funcionaram para mim, FP16 usou menos VRAM
O que observo na primeira execução:
- Picos de VRAM em
nvidia-smi. Se você estiver no máximo em 99% de VRAM instantaneamente, diminua a resolução ou quadros. - Tempo até o primeiro quadro. Minha primeira execução limpa foi ~25–40 segundos para 16 quadros em 512×288 em um 4070, steps=8. Qualquer coisa muito mais longa geralmente apontava para codificação de CPU ou um gargalo de I/O.
Se sua renderização é concluída mas o vídeo está vazio ou corrompido, tente:
- Escrever quadros PNG primeiro, depois deixar um nó separado ou ferramenta externa montar o vídeo.
- Mudar para um codificador diferente (H.264 vs H.265) ou valor CRF.
A parte útil não era velocidade, era ver um clipe coerente. Esse é o momento em que relaxo. Então escalo com cuidado.
Ajuste de Desempenho (lote / precisão)
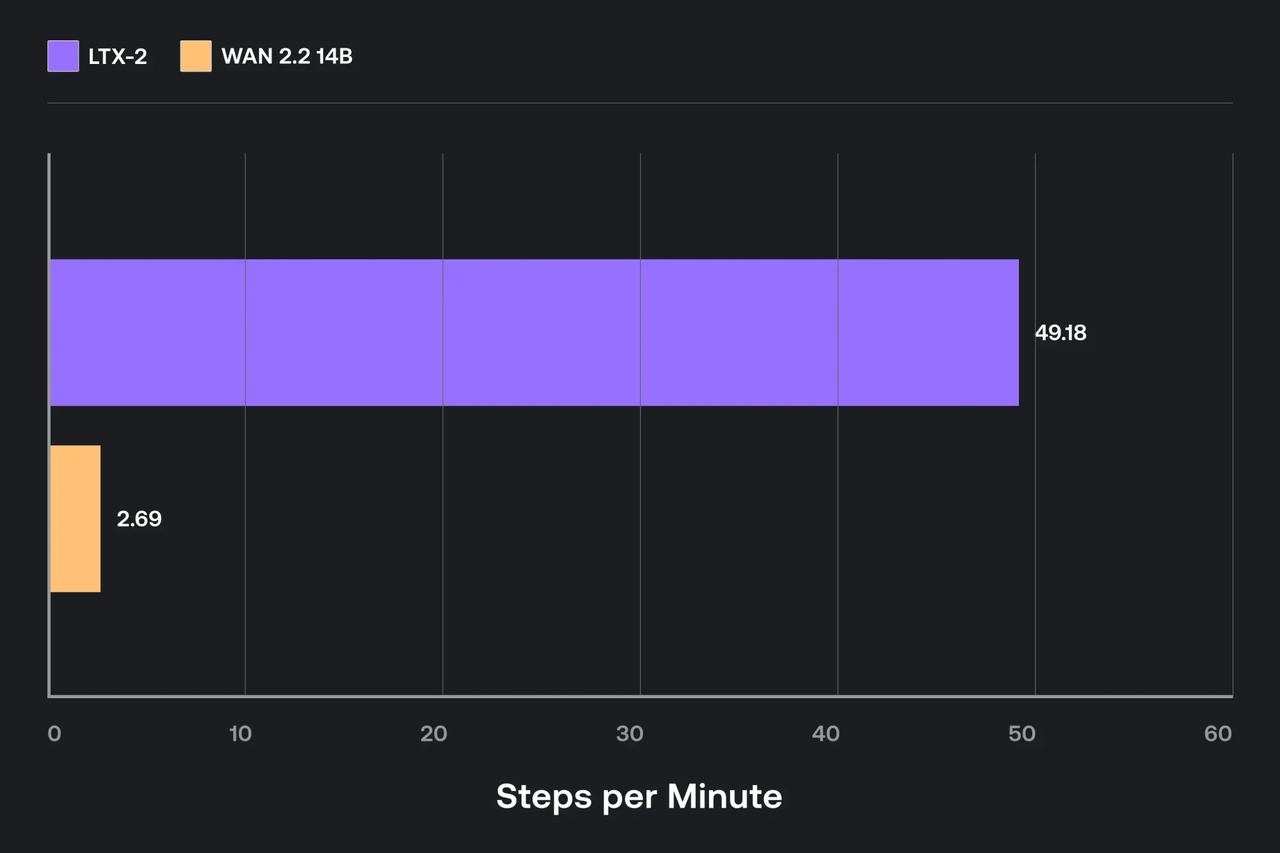
Não persegui glória de benchmark. Eu só queria configurações que me impedissem de ficar de babá da memória.
O que mexeu a agulha:
- Quadros antes de largura. Era mais fácil para VRAM manter 12–16 quadros e aumentar a largura para 640 do que pular para 24+ quadros. Clipes mais longos aumentam rapidamente em memória.
- Precisão: FP16 funcionou melhor no meu 4070. BF16 também funcionou mas usou um pouco mais de memória. Não ganhei qualidade visível com BF16 nestes tamanhos.
- Backend de atenção: Se seu pacote expuser um alternador para
scaled_dot_product_attention(PyTorch nativo) vs xFormers, tente nativo primeiro no PyTorch recente. Era mais estável para mim no Windows. - Tamanho do lote: Mantenha em 1 para vídeo. Mini-lotes principalmente puniram VRAM sem economizar tempo real no meu setup.
- Torch compile: Vale a pena testar, mas só vi pequenos ganhos para execuções mais longas. Para testes curtos de 8–16 quadros, o tempo de compilação poderia comer as economias.
- E/S Misto: Escrever em um SSD local rápido importava mais do que esperava. Pastas de rede lenta faziam a fase de codificação parecer um problema de modelo quando não era.
Uma escada simples que não explodiu VRAM para mim:
- 512×288, 12 quadros, steps=8
- 640×360, 16 quadros, steps=10
- 768×432, 16–24 quadros, steps=12–14
Se você atingir falta de memória:
- Diminua quadros em 4 antes de diminuir largura.
- Reduza passos primeiro se você só precisa de um rascunho.
- Feche outros aplicativos GPU (players de vídeo, navegador com aceleração de hardware). Tedioso, mas funciona.
Também tentei um pequeno modo de telha/patch que alguns pacotes oferecem. Ajudou em larguras maiores, mas às vezes introduzia costuras. Bom para experimentos: não é meu padrão.
Caminho WaveSpeed (sem CUDA local necessária)
Testei uma execução através de um caminho hospedado para evitar o embaralhamento da GPU. A ideia: deixe o ComfyUI conversar com um trabalhador remoto que executa LTX-2, então sua caixa local do Windows apenas lida com a interface do gráfico.
Como isso se pareceu na prática:
- Instale um conector/extensão no ComfyUI (o que usei se rotulava como “WaveSpeed” na lista do Manager). Após a instalação, um novo conjunto de nós apareceu para execução remota.
- Autentique ou aponte para um endpoint do trabalhador. O meu usava uma chave de painel. A configuração levou alguns minutos.
- Troque o carregador/amostrador LTX-2 local pelos equivalentes do WaveSpeed. Mesmos prompts, mesma forma de gráfico, apenas nós diferentes.
Pule as complexidades de configuração: Teste LTX-2 instantaneamente em WaveSpeed — sem GPU local, sem embaralhamento de driver, apenas digite seu prompt e comece a renderizar.
Se você estiver curioso, verifique a documentação oficial do conector para as etapas de configuração atuais. Eu não reconstruiria meu fluxo de trabalho inteiro em torno disso, mas como um caminho sem CUDA, era refrescantemente chato, de uma forma boa.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
