DeepSeek V4 Contexto de 1M de Tokens: Como Fazer Prompts com Codebases Inteiras

Oi, amigos. Sou a Dora. Na primeira vez que coloquei um projeto completo na janela de 1 milhão de tokens do DeepSeek V4, não me senti poderosa. Me senti cautelosa. Um milhão de tokens parece um café interminável, mas qualquer um que tenha tentado pensar por horas com cafeína na veia sabe que a clareza desaparece. Queria ver se esse novo tamanho de contexto realmente mudaria minha forma de trabalhar, ou apenas me encorajaria a colar mais.
Passei alguns dias (27–30 de janeiro de 2026) usando DeepSeek V4 com 1 milhão de tokens em três tarefas que enfrento frequentemente:
- ler um monorepo de tamanho médio sem configurar localmente,
- rastrear um bug entre serviços que se comunicam demais,
- e pedir sugestões de refatoração que não quebrem os testes.
O que aprendi: você consegue encaixar muito, mas o modelo ainda precisa que você aponte no mapa. Os ganhos não vieram de encaixar mais arquivos: vieram de como estruturei o prompt e de como pedi ao modelo para se mover através dele.
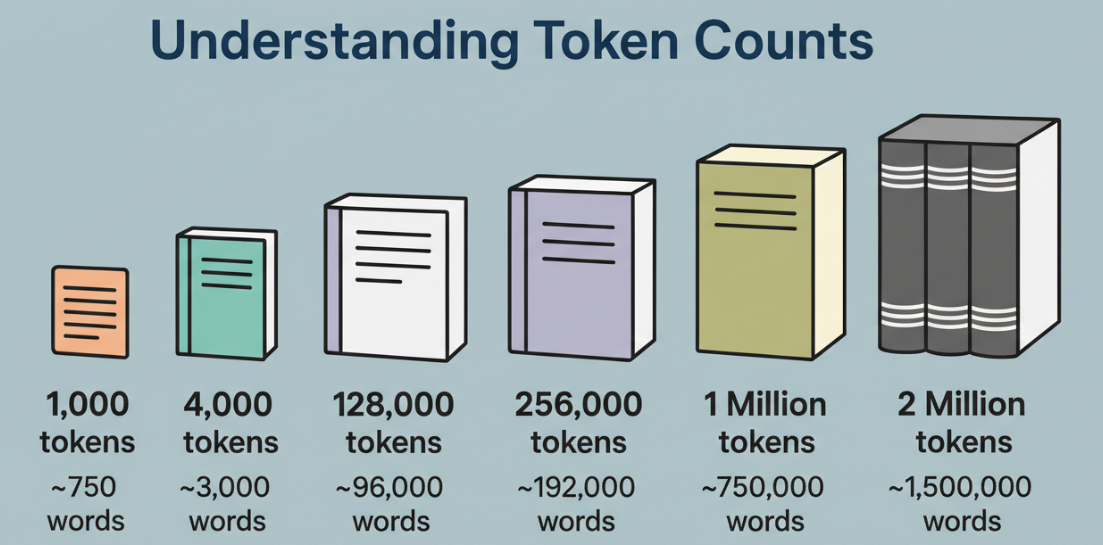
O Que 1 Milhão de Tokens Realmente Significa
 Não me importo com o número em si. Me importo com o que ele contém com uma mente clara.
Não me importo com o número em si. Me importo com o que ele contém com uma mente clara.
Um token não é uma palavra. É um pedaço, às vezes uma palavra completa, às vezes parte de uma, às vezes pontuação. Em textos em inglês, geralmente considero 1 token como ~0,75 palavras para planejamento aproximado. Para código, tokens chegam rápido: chaves, pontos, nomes de métodos, tudo fatiado. Um milhão de tokens é muito território, mas não é atenção infinita.
O que mudou para mim essa semana: parei de podar tão agressivamente. Com contextos de 128K, eu resumia agressivamente e mantinha apenas o caminho crítico. Com 1M, conseguia manter o caminho crítico mais os arquivos “frios” que tendem a me surpreender depois (config, migrações, scripts de construção, cola de fluxo de trabalho). Dito isso, se eu despejasse tudo de uma vez, as respostas ficavam vagas. Quando alimentava o modelo em estágios, com sinalizações claras, as saídas pareciam fundamentadas.
Equivalente em Linhas de Código
Matemática aproximada que usei enquanto trabalhava:
- Muitos repositórios misturam código e documentação. Em pastas pesadas em código, vi ~2–3 tokens por caractere em linguagens densas, mas um atalho prático: pense em ~4 tokens por linha para linhas simples, ~8–12 para linhas do mundo real com indentação, nomes e comentários.
- Nesse ritmo, 1 milhão de tokens contém algo em torno de 80K–150K linhas de código, dependendo do estilo e da linguagem. Um serviço TypeScript com comentários e nomenclatura amigável ao lint fica no lado mais alto. Bundles minificados explodem a contagem e não vale a pena incluir.
Na prática, meu “ajuste seguro” era ~60K linhas de código-fonte significativo + documentação e testes direcionados. Poderia ir mais alto, mas a latência aumentava e as respostas ficavam mais vagas. Seus resultados variarão com as regras do tokenizador e a mistura de linguagens.
versus Modelos Atuais (128K)
Pular de 128K para 1M parece menos como uma mochila maior e mais como trazer um carrinho de rodas. Você consegue carregar mais, mas não vai correr.
O que notei:
- Latência: Prompts de contexto completo demoraram notavelmente mais. Quando dividi a sessão (estágio por estágio), a latência parecia gerenciável.
- Recall: Com 128K, o modelo frequentemente “esquecia” dos arquivos anteriores a menos que eu repetisse a parte-chave. Com 1M, ele não esquecia, mas às vezes generalizava em vez de citar especificidades. Tive mais sorte quando pedi para citar caminhos de arquivo e intervalos de linhas quando possível.
- Precisão: Quanto maior o contexto, mais você precisa de comportamentos de indexação no seu prompt. Caso contrário, você obtém resumos competentes que evitam os casos extremos desordenados com que realmente se importa.
Se você está esperando que 1 milhão de tokens signifique “sem mais engenharia de prompt”, eu não contaria com isso. Isso muda o tipo de direcionamento que você faz.
Estrutura de Prompt para Codebases Grandes
 Parei de pensar no prompt como uma mensagem e comecei a tratá-lo como um plano de leitura. O modelo consegue ler muito agora, mas ainda se beneficia de um sumário e de um rastro.
Parei de pensar no prompt como uma mensagem e comecei a tratá-lo como um plano de leitura. O modelo consegue ler muito agora, mas ainda se beneficia de um sumário e de um rastro.
O que funcionou melhor para mim parecia com isto: framing do sistema curto, índice de projeto conciso, uma ordem declarada de exploração, depois uma tarefa específica. E então mantive a conversa indo em rodadas, não em um mega-prompt.
Ordenação de Arquivos
Obtive respostas mais confiáveis quando disse ao modelo qual arquivo abrir primeiro, segundo, terceiro. Uma única lista no topo ajudou a construir uma pilha mental:
- Comece com os pontos de entrada (CLI, manipuladores HTTP, jobs). Isso ancora o fluxo.
- Depois a camada de composição (contêiner DI, main.ts, app.py) onde as dependências se conectam.
- Em seguida, os módulos de domínio principal e suas interfaces.
- Apenas depois: auxiliares, utilitários e peças transversais (logging, telemetria, config).
- Testes por último, a menos que eu esteja depurando uma falha específica; nesse caso, comece com a especificação que falhou para estabelecer expectativas.
Também incluí notas de “não leia” para pastas que parecem importantes mas não são: código gerado, ativos compilados, snapshots. Economizou tokens e manteve a atenção do modelo no código vivo.
Um pequeno truque: pedi ao modelo para manter uma lista contínua de “arquivos ativos” (caminhos e pequenos resumos) e atualizá-la conforme nos movíamos. Quando desviava, eu podia apontar de volta para essa lista e dizer: “Fique dentro desse conjunto por enquanto.” Isso mantinha as respostas concretas.
Mapeamento de Dependências
Um dos passes mais úteis foi pedir um mapa de dependências no início, não como um diagrama mas como uma tabela simples de arestas: o módulo A importa B, B usa C, C atinge variáveis de ambiente, e assim por diante. Mantive isso textual e conciso.
O que isso fez na prática:
- Expôs dependências isoladas (o tipo que vaza preocupações entre pastas).
- Deu-me uma lista curta de “pontos de pressão” para revisar antes de qualquer refatoração.
- Ajudou o modelo a referenciar o lugar certo quando pedi mudanças.
Também pedi ao modelo que declarasse suposições, o que ele inferiu de nomenclatura, comentários ou testes. Quando uma suposição estava errada, eu a corrigia uma vez, e os passos posteriores ficavam mais limpos.
Um aviso: pedir um mapa de dependências completo em um grande repositório de uma só vez levou a timeouts e gráficos vagos. Tive melhores resultados ao escopá-lo por camada (ex: apenas acesso a dados, apenas manipuladores HTTP) e depois mesclar as notas eu mesmo. Levou 10 minutos a mais mas compensou em precisão.
Estratégias de Chunking Quando Necessário
 Mesmo com uma janela de 1M tokens, eu ainda dividia em chunks. Não porque não conseguisse encaixar, mas porque meu pensamento era melhor em estágios, e o modelo respondia mais precisamente quando eu estreitava seu campo de visão.
Mesmo com uma janela de 1M tokens, eu ainda dividia em chunks. Não porque não conseguisse encaixar, mas porque meu pensamento era melhor em estágios, e o modelo respondia mais precisamente quando eu estreitava seu campo de visão.
Alguns padrões que se mantiveram essa semana:
- Estruture o briefing: Comecei com um contexto pequeno, índice de projeto, tarefa, restrições conhecidas, depois pedi um plano de leitura e verificação. Apenas depois disso alimentei o código na ordem que acordamos.
- Limite o conjunto ativo: Para uma refatoração, mantive apenas os 5–12 arquivos em jogo e pedi mudanças com caminhos explícitos. Se uma edição tocasse um utilitário compartilhado, adicionava aquele arquivo na próxima vez. O modelo ficava mais apertado.
- Resuma nas bordas: Antes de passar para uma nova pasta, pedia um pequeno resumo do que aprendemos e quaisquer incertezas. Esses resumos atuavam como migalhas de pão entre turnos sem re-colar cada arquivo.
- Use recuperação propositalmente: Para repositórios que não se encaixavam confortavelmente, usei embeddings para chamar arquivos por consulta (“normalização de id de pagamento”, “backoff de retentativa”). Mantinha o conjunto recuperado pequeno por vez, geralmente menos de 40K tokens, para que as respostas não ficassem borradas.
- Verifique para frente, não para trás: Em vez de perguntar: “Você usou tudo o que colei?”, Perguntei: “Aponte as funções e linhas específicas em que sua sugestão depende.” Isso forçou referências concretas e tornou erros óbvios.
Atrito que encontrei:
- Latência aumenta quando você envia mensagens de contexto completo a cada vez. Estruturar reduziu meu tempo médio de resposta de 70–90s para 20–40s nas mesmas tarefas.
- Custo importa. Prompts grandes se acumulam. Economizei tokens aparando comentários que reiteravam o óbvio, removendo artefatos compilados e pulando bundles de fornecedores.
- Efeitos de posição são reais. Conteúdo no muito início ou fim de um prompt gigante tende a ser mais “disponível.” Contrei isso repetindo as restrições pequenas e críticas perto do final de cada vez.
Quem se beneficia da janela de 1M?

- Se você vive em monorepos, lida com auditorias ou faz refatorações transversais, economiza algumas etapas de configuração e overhead de indexação local. É um ponto de partida mais calmo.
- Se seu trabalho é principalmente correções de bugs focadas em pequenos serviços, a capacidade extra não ajudará muito. Um contexto menor mais um pipeline de recuperação apertado se sentirá mais rápido.
Uma nota sobre confiança: pedi ao modelo para citar linhas exatas de código para mudanças arriscadas (migrações, autenticação). Quando hesitava ou parafraseava, eu tratava isso como um sinal para estreitar o escopo ou colar o arquivo específico novamente. Esse pequeno hábito preveniu alguns quase-desastres.
Se você quer a descrição formal de limites de modelo ou comportamento de tokenizador, confira os documentos do provedor. Quando precisei de especificidades, voltei para o cartão de modelo oficial e as notas de janela de contexto. Isso me manteve honesta sobre o que eu estava pedindo ao modelo para fazer.
Não é mágica. É apenas uma mesa maior. Útil, se você arranjar as cadeiras.
Continuo pensando em uma coisa pequena de terça-feira: pedi uma correção, e o modelo sugeriu mudar uma função que parecia certa à primeira vista. Não era. O bug vivia em um auxiliar dois níveis abaixo. Um milhão de tokens não mudou isso. Minhas notas mudaram.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
