GLM-4.7-Flash vs GLM-4.7: Which One Fits Your Project?

Hello my friends. I’m Dora. If this sounds familiar, you’re not alone. I’ve been there: staring at a queue of tiny, repetitive prompts that just need a fast, solid reply—while a couple of stubborn, multi-step reasoning tasks sit in the corner, quietly demanding way more horsepower.
So I finally asked the question out loud: where does the lightweight, lightning-fast GLM-4.7-Flash actually shine, and where do you need to bring in the heavier, more deliberate GLM-4.7? This is the straight-up, no-hype answer I landed on—grounded in real runs, benchmarks when they matter, and the quiet goal of making your daily stack feel noticeably lighter. If you’ve ever paused at “which model should I even use here?”, this is for you.
30-Second Answer
If speed and low cost are your top levers, GLM-4.7-Flash will likely feel right. If your work leans on reasoning depth, tooling, or higher-fidelity outputs, GLM-4.7 is the steadier choice. The rest is nuance around latency budgets, context size, and how your prompts behave under pressure.
Choose Flash If…
Flash isn’t “weaker”—it’s just very honest about what it’s good at.
- You’re dispatching many small jobs: summaries, tags, drafts, quick transforms.
- Latency matters more than squeezing out the last 10% of quality.
- You’re experimenting, prototyping, or building UI interactions that should feel instant.
- Occasional wobbles in long reasoning steps won’t derail you.
- You want a cheaper default model and can escalate to GLM-4.7 only when needed.
Choose GLM-4.7 If…
This is your “don’t mess this up” model.
- You care about code reliability, multi-step reasoning, or tool use precision.
- The prompts are long, the instructions strict, or the outputs need to be consistent.
- You’re running evaluators, tests, or workflows where one mistake is expensive.
- You need stronger results on coding and long-context tasks.
- You can tolerate higher cost and a bit more latency for better outcomes.
Architecture Differences
 I don’t chase parameter counts for sport, but the architecture explains a lot about behavior: why one model feels snappy and the other feels deliberate.
I don’t chase parameter counts for sport, but the architecture explains a lot about behavior: why one model feels snappy and the other feels deliberate.
Parameter Count & Active Experts
GLM-4.7 appears to run a larger backbone and (from public notes) uses expert routing that prioritizes reasoning. Flash is tuned for throughput, lighter routing, fewer active experts per token, and aggressive efficiency settings. In practice, that tends to show up as:
- Flash: lower per-token compute, fast first-token times, but it can drop reasoning chains under stress.
- GLM-4.7: more compute per token, steadier reasoning paths, better tool-call choices.
If you skim provider diagrams, you’ll see hints of mixture-of-experts (MoE) and activation sparsity. The exact numbers drift across versions, so I treat them as directional, not absolute. The big idea: Flash spends less “thinking” per token so it moves sooner; GLM-4.7 thinks longer and trips less on edge cases.
Context Window & Output Limit
Two practical questions matter more than the headline context number:
- How far into long prompts does quality hold?
- When outputs get long, does the model lose the thread?
Flash usually advertises a healthy context window, but quality tends to taper sooner with very long prompts or dense instructions. GLM-4.7 holds coherence deeper into long contexts and remains more obedient to structure in long outputs. If you’re packing in a knowledge base, GLM-4.7 is the safer default. If you’re chunking inputs or using retrieval to keep prompts slim, Flash is often good enough—and much faster.
Benchmark Comparison
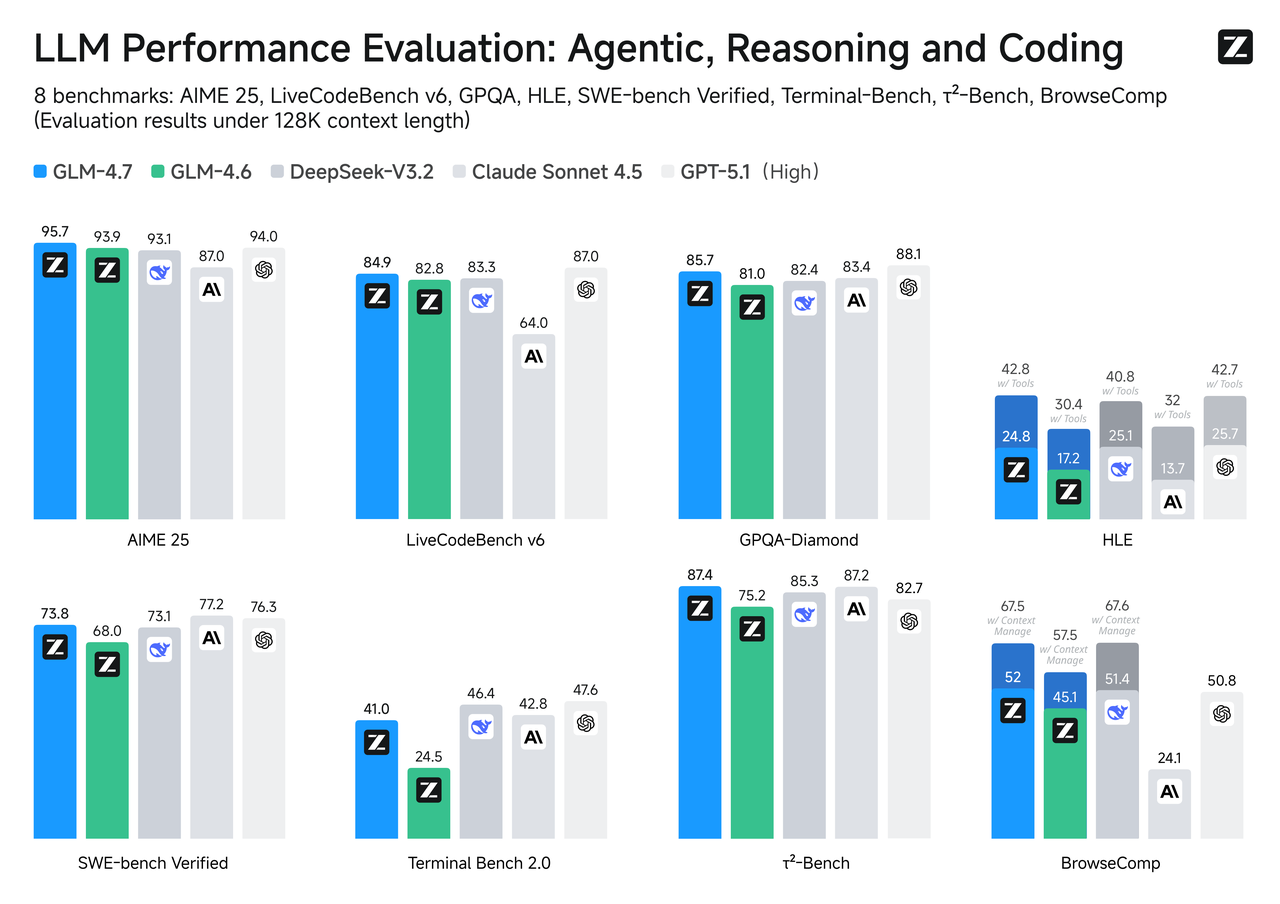 Benchmarks aren’t the whole story, but they’re a useful compass, especially when your use case lines up with the task.
Benchmarks aren’t the whole story, but they’re a useful compass, especially when your use case lines up with the task.
SWE-bench Verified
For code changes that must actually compile and pass tests, GLM-4.7 tends to rank above its Flash sibling. That matches what you’d expect from a model tuned for reasoning depth and tool use. Flash can draft fixes and explain code nicely, but when the patch needs several coordinated edits across files, GLM-4.7 is more likely to follow the chain without dropping steps.
If your pipeline includes auto-PRs or repair loops, it’s worth sanity-checking with a small sample first. The difference shows up more on multi-hop issues than on single-file tweaks.
LiveCodeBench / τ²-Bench
On live or time-rotating coding benchmarks, GLM-4.7 generally tracks closer to the top tier given its heavier reasoning budget. Flash, optimized for speed, sits a tier lower but responds quickly. If your product relies on code synthesis quality more than interaction speed, GLM-4.7 is the conservative choice. If the code is advisory (you’ll review it anyway) and responsiveness matters, Flash can be the right trade.
Speed & Latency
This is where the split feels clearest. Flash often returns the first token noticeably faster, and total time-to-last-token stays low for short and medium outputs. That adds up if you’re running many small calls or streaming to a UI.
GLM-4.7 starts slower and runs heavier, but it’s more stable on long generations and complex tool-call sequences. You’ll see fewer stalls, fewer odd detours, and better adherence to function schemas.
If you’re building a system:
- Use Flash for high-traffic UX moments: autocomplete, quick summaries, inline help.
- Use GLM-4.7 for the slow lane: evaluators, code actions, policy checks, final passes.
A simple routing rule often pays for itself: start with Flash, escalate to GLM-4.7 when confidence drops or thresholds are crossed. Let rules decide so you don’t have to.
Pricing Breakdown
Pricing shifts by region and provider, so I treat numbers as moving targets and keep the structure stable.
Flash Free Tier vs GLM-4.7 Pay-per-Token
-
Flash: Many platforms expose a free or low-cost tier for Flash-like models, with generous rate limits compared to flagship models. Great for prototyping, background chores, and UI polish.
-
GLM-4.7: Typically billed per token at a higher rate. Better cost-to-value on serious tasks, but it’s easy to overspend if you leave it as the default.
 Practical tips:
Practical tips: -
Cap output tokens by default. Raise the cap only in routes that need it.
-
Use retrieval to keep prompts short: don’t pour the whole corpus into the window.
-
Cache deterministic sub-results (regex maps, schema snippets, few-shot blocks) so you don’t pay for them again.
-
Log token costs per route. The report you actually read is the one that sits in your weekly workflow, not the one with the most charts.
When in doubt, start cheap, measure, then promote. Escalation beats optimism.
Pick by Use Case
Here’s how I’d slot them when the goal is fewer headaches:
- High-churn content ops (snippets, subject lines, metadata): Flash. The win is throughput and consistency at low cost.
- Support macros and quick triage: Flash first, then escalate to GLM-4.7 if the detection flags complexity or policy risk.
- Research notes, synthesis, structured summaries: Flash for skims; GLM-4.7 for the pass that must be source-faithful and well-scaffolded.
- Code assistance: Flash for explanations and “what does this do?”; GLM-4.7 for multi-file edits, migrations, and test-aware changes.
- Data cleanup and transformation: Flash is fine for simple mapping; GLM-4.7 for strict schemas, validation, and multi-step joins.
- Agents and tool use: GLM-4.7. You’ll get more reliable function arguments and fewer retries.
- Long-context reading or doc-grounded QA: GLM-4.7 if you’re pushing the window; Flash if you keep chunks lean.
A few field notes I keep close:
- Short prompts hide differences. The gap shows up when instructions are dense or outputs must follow a structure.
- Routing helps. Even a simple rule, “Flash unless prompt > N tokens, then GLM-4.7”, saves money without drama.
- Guardrails matter more than model choice for repetitive tasks. Validation, retries, and small checkers prevent downstream messes.
- Don’t fetishize speed. Under a second feels “instant” to most users. Past that, stable behavior beats shaving 100 ms.
Why this matters: tools age well when they reduce mental load. Flash keeps the small stuff light. GLM-4.7 carries the heavy boxes without dropping them. Most stacks need both.
If you’re unsure, start with Flash as your default and create a clear lane for GLM-4.7. Let routes, not moods, decide. Your mileage may vary, and that’s fine.
I still notice, on quiet days, how this split reduces decision fatigue. Nothing flashy—just fewer headaches.
How I actually run this split in practice
 When I need to route fast jobs to Flash and escalate heavier ones to GLM-4.7 without babysitting scripts, I use WaveSpeed — our own platform.
When I need to route fast jobs to Flash and escalate heavier ones to GLM-4.7 without babysitting scripts, I use WaveSpeed — our own platform.
We built it to handle model switching, concurrency, and batch calls cleanly, so the “Flash first, escalate when needed” pattern stays simple instead of brittle.
If you’re running lots of small calls and don’t want routing logic to become another thing to maintain, try Wavespeed!
FAQ: GLM-4.7-Flash vs GLM-4.7
1. What are the main differences between GLM-4.7-Flash and GLM-4.7?
GLM-4.7-Flash is a lightweight, optimized variant of GLM-4.7. It achieves faster inference and lower cost by reducing the number of active experts, simplifying routing, and applying efficiency tweaks. GLM-4.7 retains a larger backbone and stronger reasoning capabilities, excelling in complex multi-step reasoning, long-context coherence, and precise tool calling.
In short: Flash trades some intelligence for speed; GLM-4.7 prioritizes depth and reliability.
2. Which model is faster, and in which scenarios is the speed difference most noticeable?
GLM-4.7-Flash has significantly lower time-to-first-token (TTFT) and per-token latency. It shines in high-throughput, low-latency use cases such as real-time UI interactions, content summarization, metadata generation, and rapid prototyping.
GLM-4.7 has higher startup overhead and heavier computation but remains more stable for long outputs or complex tool-call sequences. In practice, Flash is noticeably faster for short-to-medium outputs (under 500 tokens).
3. Which model is stronger in intelligence and reasoning?
GLM-4.7 outperforms Flash in multi-step reasoning, code reliability, tool use, and long-context tasks. Examples:
- SWE-bench Verified: GLM-4.7 leads in multi-file code editing and coordinated patches.
- LiveCodeBench / τ²-Bench: GLM-4.7 delivers higher-quality code, especially for deep-reasoning scenarios.
Flash is suitable for single-file edits or assistive tasks that tolerate human review, but it degrades faster on long reasoning chains or dense prompts.
4. How do context length and output limits compare?
Both models share similar context windows, but GLM-4.7 maintains better coherence and instruction-following on very long contexts (>32k tokens) or dense prompts. Flash degrades more quickly under extreme prompt length or density—pair it with chunking or RAG for best results.
5. How should I choose based on pricing and cost control?
GLM-4.7-Flash typically offers higher free quotas and lower (or even zero) per-token pricing, making it ideal for prototyping, background tasks, and high-volume low-risk calls. GLM-4.7 has higher per-token costs but better value for critical tasks.
Recommendation: default to Flash, escalate to GLM-4.7 for complex work, and always set token caps and caching to prevent overspending.
Related Articles

GPT-5.4 for Developers: What the Leaked Signals Mean for AI Workflows

SkyReels V4 Use Cases: 6 Ways Creators Can Use It Right Now

GPT-5.4 Release Date: What the Signals Say

GPT-5.4 vs GPT-5.3: What Might Actually Change
