Create an AI Anchor in 5 Minutes: A Beginner's Guide to Building Digital Humans
A step-by-step tutorial to build a digital human on WaveSpeedAI.
A step-by-step tutorial to build a digital human on WaveSpeedAI.
Foreword
Not everyone is born a natural speaker, and not everyone feels comfortable speaking in front of a crowd.
Standing up to speak can be nerve-wracking — but what if a “virtual you” could give the presentation, go live, or record your promo read for you? Would you still be afraid?
On WaveSpeedAI, that’s no longer just an idea! You can build your own digital human from scratch and have it speak your words with a realistic voice and expressions.
It doesn’t get stage fright, it never gets tired, and you can refine and reuse it as often as you want. It’s your reliable partner at work and in life.
In this tutorial, we’ll guide you from zero to one as you build a simple digital human step by step. The models we use here are just the beginning—feel free to explore more capabilities and styles to make your digital human truly one of a kind.
On WaveSpeedAI, our models produce clear, stable visuals with natural edges and are ready for display. They work well for formal talking-head segments, casual conversations, and product explainers alike.
Image Generation
A handsome, cute, and natural-looking digital human provides viewers a better experience. It will also attract more buzz and traffic to your channel.
You can also create one directly from a personal photo. If you already have a suitable photo ready, feel free to skip this part.
I’ll use bytedance/seedream-v4 as an example to help you create a virtual avatar that’s uniquely yours.
On WaveSpeedAI, search for bytedance/seedream-v4 — it’s a text-to-image model. Now, let’s enter a prompt to create your own digital human:
Half-length portrait of a young female digital human (22–28),
natural makeup, white shirt and light gray blazer,
looking at camera, soft studio light,
plain light-gray background, ultra realistic, 4k, 85mm, f/2.8
You can customize elements like gender, outfit, and background to suit your needs, creating various styles and moods so your digital human feels more appealing and on-brand.
Voice Generation
Now that your digital human is ready, the next step is to draft a clear voiceover script so they can “speak” naturally.
In WaveSpeedAI, go to Category > Text-to-Audio to explore various models. We offer models for natural voiceovers, voice cloning, and even song composition.
In this section, we’ll use minimax/speech-02-hd as our example. Feel free to try other models to explore different vocal styles and effects.
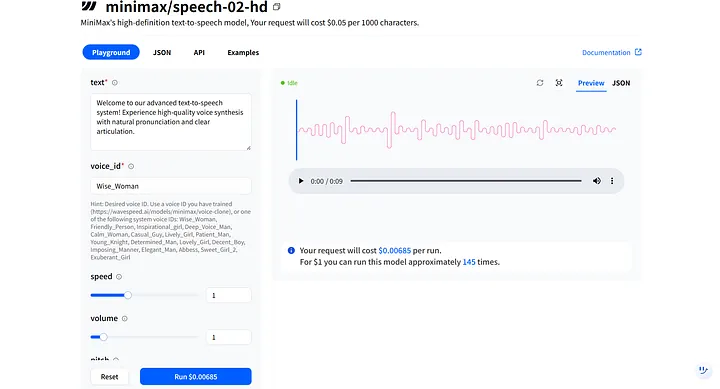
In the model Playground, you’ll see key parameters like text and voice_id. These work together to shape your digital human’s tone and timbre, and you can adjust them to fit different scenarios. For example, the digital human I created is female, so I can select the first voice option, Wise_Woman.
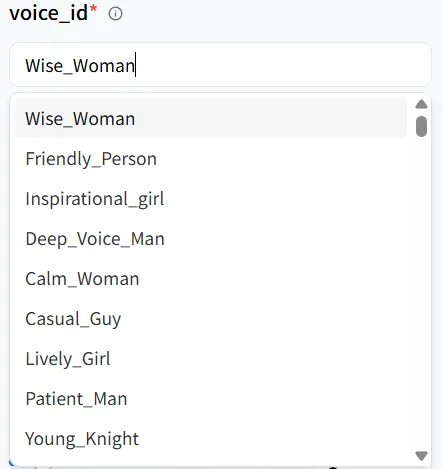
Key Parameters
Speed
speed controls how fast your digital human speaks. Choose a pace that suits the scene — for instance, slow down a bit for product introductions and speed up for casual conversations. A value of 1 indicates normal speed.

Volume
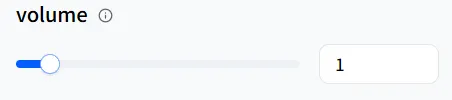
volume sets the loudness. If your digital human is narrating a bedtime story, you can lower speed to slow things down and decrease the volume for a softer delivery. A value of 1 is the default volume.
Pitch
pitch adjusts the voice’s tone. Tune this to make the voice sound brighter and sharper or deeper and fuller. A value of 0 is the default pitch.

Emotion
emotion controls the speaking style of your digital human. Choose a tone that matches the scene — here, we’ll pick happy.
English Normalization
The english_normalization option, when enabled, makes numbers and symbols in English sound natural in speech. Without it, the system might read digits one by one (e.g., “one two three” for “123”) instead of “one hundred and twenty-three.”

Sample Rate
sample_rate determines audio quality (resolution). If you’re producing ASMR-style content, aim for a higher sample rate for richer detail. For this tutorial example, it isn’t critical—keeping the default is perfectly fine.
Bitrate
bitrate determines both the quality and size of your audio file. It represents the number of bits processed per second. A lower bitrate creates a smaller file but may lose detail; a higher bitrate results in a larger file with clearer sound.
Channel
The channel parameter determines the number of audio channels generated.
- channel = 1 (mono): All sound is mixed into a single channel—ideal for phone voice, call recordings, or dialogue-focused content where spatial width isn’t needed.
- channel = 2 (stereo): Sound is split into left and right channels, creating width and a sense of space for a more immersive, layered experience—perfect for music, film, games, and video voiceovers that require higher listening quality.
Format
format allows you to select the output audio file type (we’ll skip the specifics here).
Language Boost
language_boost improves the model’s understanding of your selected language. For this tutorial, choose English.
Generate Audio
Next, paste your script and click Run to generate the audio!
Welcome to WaveSpeedAI’s Digital Human Tutorial. We’ll spark fresh ideas in AIGC and show you practical steps. Let’s unleash your creativity together!
Download the audio file — this is the crucial piece that will let your digital human speak later!
Let the Digital Human Speak
Finally, the exciting moment: we’re going to make your digital human actually speak!
In WaveSpeedAI, search for wavespeed-ai/infinitetalk—our high-quality model designed specifically for digital-human voiceovers.
In the model’s Playground, you’ll see two required inputs: audio and image.
- audio: Upload the voiceover file you just downloaded.
- image: Upload the digital-human image you generated earlier.
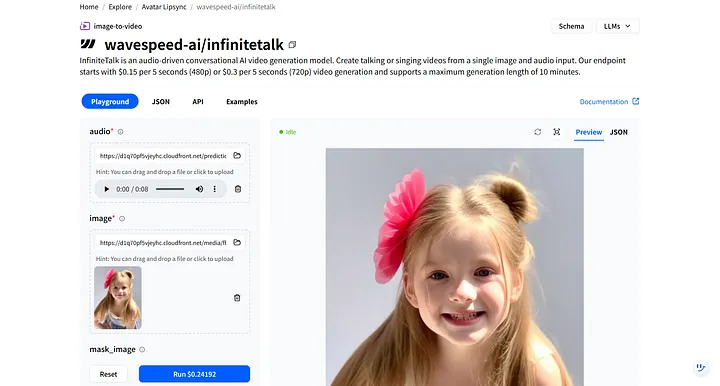
After clicking Run, the digital human responds to the audio and automatically synchronizes lip movements and facial expressions.
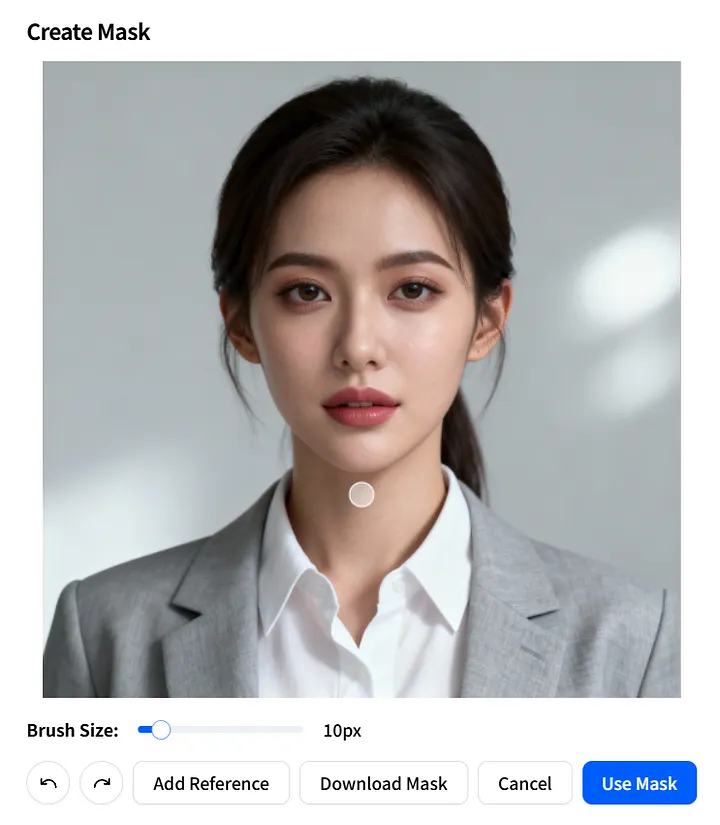
Mask Image Parameter
Next, let’s look at the mask_image parameter. It allows you to specify exactly which parts of the image should be animated.
On the Create Mask page, accurately define the movable area: adjust Brush Size, paint over the regions you want to animate, then click Use Mask to apply.
You can also click Download Mask to save the mask_image as a template for quick reuse in future projects.
Additional Customization
If you have additional needs—such as specifying a pose, hand gestures, or gaze direction—add more specific instructions in the prompt.
For easy replication, set a fixed seed value. This ensures the randomness is consistent so you can reproduce the same results later.
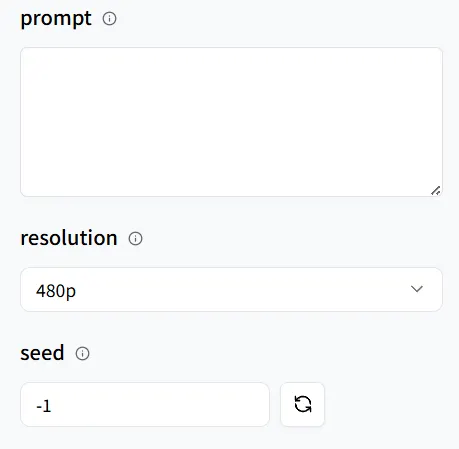
Finally, click Run, and let’s look forward to the final result!
Congratulations! You’ve got your own digital human!
Ready to advance to multi-person scenes? WaveSpeedAI also provides dedicated models for that. Let’s explore them together!
Multi-Speaker Generation
On WaveSpeedAI, search for wavespeed-ai/infinitetalk/multi. Its steps are basically the same as the single-person model.
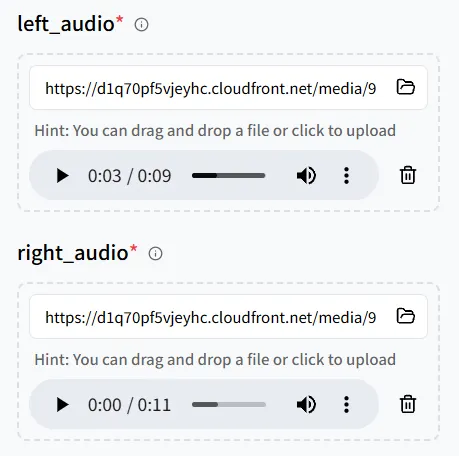
This time, add two audio files, then upload an image featuring two digital humans so both characters can deliver their lines.
Pay close attention to the pairing between audio and on-image positions:
- left_audio → the person on the left in the image
- right_audio → the person on the right in the image
Review the mapping carefully; otherwise, the voices could be linked to the wrong characters.
Speaking Modes
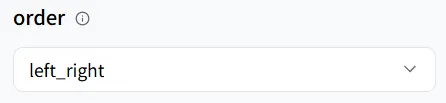
In the wavespeed-ai/infinitetalk/multi model, it supports three speaking modes:
- left_right (left to right)
- right_left (right to left)
- meanwhile (simultaneous speech)
Similarly, with this model, you can add the details you want through the prompt and set a seed for easy reproducibility.
And just like that, you’ve got a two-person voiceover show!
Other Models
On WaveSpeedAI, we also provide many additional models for you:
- wavespeed-ai/multitalk: Perfect for “song-style digital humans,” enabling multi-part vocals and more expressive performances.
- wavespeed-ai/infinitetalk/video-to-video: Add voiceover or narration to existing videos so the visuals and audio stay naturally in sync.
- wavespeed-ai/song-generation: Create music from scratch to design a custom soundtrack and atmosphere for your content.
These models also offer unique experiences that are difficult to replicate on other platforms. Be bold—try them out and share your work! You can post in the Inspiration section to connect and interact with other creators!

Final Thoughts
Our world is changing rapidly, and AI is increasingly influencing our daily lives. Sticking to old methods only increases costs, slows progress, and risks missing new opportunities.
Now is the perfect time to adopt new technology and enjoy the convenience and efficiency it offers. WaveSpeedAI provides long-term support for your content creation with reliable technology and an ever-growing ecosystem.
Wherever your creativity leads, WaveSpeedAI will be there as your reliable foundation and trusted partner.
Related Articles

HiDream-O1-Image-Dev: The 8B Pixel-Native Model That Beat 56B FLUX.2
Seedance 2.0 Complete Guide: Multimodal Video Creation

Introducing Nucleus Image on WaveSpeedAI
Introducing ByteDance Seedance 2.0 Text-to-Video on WaveSpeedAI

Introducing Ideogram V3 Generate Transparent on WaveSpeedAI
