GPT-5 Model Versions Explained: From GPT-5 to GPT-5.4
GPT-5 isn’t a single model. This guide explains every GPT-5.x version and what developers should know about the evolving model family.

Use GPT-5.5 and GPT-5.4 on WaveSpeedAI — pay per token, no subscription, OpenAI-compatible endpoint. GPT-5.5 API → · GPT-5.4 API → · Open the Playground →
Hi, I’m Dora. I didn’t plan to write about GPT-5 models this week. I just got stuck picking a version in the model dropdown again. A tiny pause, then the familiar question: does 5.2 actually help here, or am I clicking the newer thing because it’s newer?
That small friction sent me down a rabbit hole. I spent a few evenings in late February and early March 2026 re-running the same tasks across the 5.x family: a compact research summary, a structured JSON extraction, and a simple multi-file code refactor. Nothing flashy. Just the kind of work that either feels easier, or doesn’t. These are my field notes, not a victory lap.

Why GPT-5 Is a System, Not a Single Model
I keep seeing people talk about “the” GPT-5 model, as if it’s a single brain you swap in. That hasn’t matched what I’ve observed, or what OpenAI hints at in their docs and public talks.
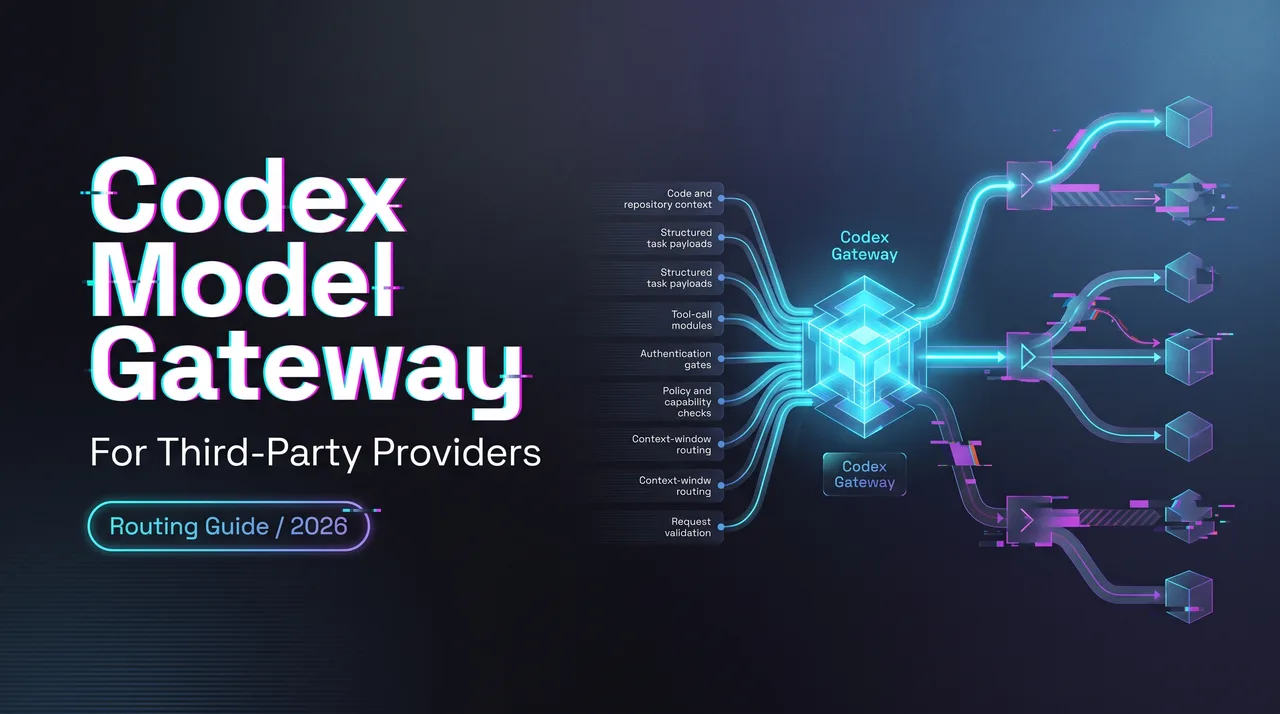
Router architecture overview
The behavior looks like a routed system: one “front door” that quietly decides which internal specialist handles which part of your request. You can think of it as a traffic controller with a few goals in mind: keep latency steady, hit a quality threshold, and avoid running expensive specialists unless the prompt really needs them. That’s why the same prompt can feel a bit different between “fast” and “default” settings, or across adjacent versions, there’s more than one model in play.
In practice, I’ve seen signals of this when:
- Tool-calling gets picked up faster on certain runs, as if a planner kicked in earlier.
- JSON mode reliability jumps after a system-side update, even if the API parameters didn’t change.
- Latency holds under load better than it should for a single monolith.
I can’t see behind the curtain, but the outputs suggest a router that weighs cost, speed, and task type, then picks a path. That framing helps me make sense of why two “GPT-5” labels can behave differently.
How OpenAI versioning works
OpenAI usually ships model families with named versions and occasional “preview” builds. Over time, a version may become the default, then later get deprecated. The labels can move faster than blog posts can keep up. When I’m unsure, I check the OpenAI model docs and the API changelog before I lock in a version. It’s also worth skimming the API reference for small but important flags (response schema, JSON modes, tool-calling nuances) that shift between versions.
So when I say “GPT-5,” I mean the routed system exposed under that family name. And when I say “5.1” or “5.3,” I mean a specific configuration of that system, often with different defaults, slightly different routers, and sometimes new safety or reliability guards.
GPT-5 (Base) — Initial Capabilities
I first treated the base GPT-5 as a generalist. Not because it was magic, but because it handled three common jobs fairly well with little setup.
Core features at launch
- Reasoning clarity: For planning tasks, “draft me a 3-step approach, then fill step 1”, the base model stuck to the structure without me over-explaining. It wasn’t showy. It was steady.
- Tool use without drama: Function calling worked out of the box. When I asked it to pull structured fields, it passed consistent, typed arguments most of the time.
- Longer context without melting: I pushed long briefs and multi-part references. It stayed coherent enough to be useful, especially when I anchored it with section headers.
- JSON mode and response schemas: With a simple schema, I could get parseable outputs 8–9 times out of 10 on the first try. When it failed, it failed obviously (truncated object), which is a weird kind of mercy.
Early limitations
- Determinism is still soft: Even with low temperature, repeated runs nudged phrasing and sometimes ordering. For production, I had to add lightweight post-processing (sorting keys, normalizing whitespace) to keep diffs quiet.
- Tool-call recall: If I chained tools, the model sometimes “forgot” a prior tool’s edge constraints unless I restated them. A small annoyance, but real.
- Latency spikes: Most calls were fine. Then one or two would take noticeably longer. Not minutes, just enough to throw off a tight loop.
- Cost awareness: The base was not the cheapest, so careless long prompts felt expensive. I trimmed system messages and moved boilerplate out to code templates. Simple step, meaningful savings.
GPT-5.1 to GPT-5.3 — Incremental Changes
These point releases didn’t change the character of GPT-5 models. They tightened screws.
Version-by-version improvements
- 5.1: Instruction following got crisper. When I asked for “bullets only, no intro,” it listened more often. JSON conformance ticked up a bit too.
- 5.2: Better grounding in citations. When I provided passages and asked for quote-backed summaries, it anchored more cleanly to the quoted text. Hallucinations dropped, not to zero, but enough that I noticed.
- 5.3: Tool-calling felt more dependable under load. Fewer odd argument shapes. I also saw slightly faster first tokens in my logs, though this might be the router doing smart triage rather than the model itself.
All of this showed up in quiet ways: fewer retries, less cleanup, less hand-holding in prompts.
Developer-facing differences
- Response schemas: The newer releases were pickier in a good way. When I declared a schema, they either followed it or failed fast. That saved me more time than any “intelligence” bump.
- Streaming deltas: The token stream came in more stable chunks. Easier to build UIs that don’t jitter.
- Tool signature tolerance: 5.2 and 5.3 handled strict types without improvising. If a field was an enum, it stopped inventing new values as often. That reduced guardrail code.
These are small, but they remove paper cuts. If you’re maintaining agents, small is big over many calls.
What stayed the same
- Context length realities: Feeding huge context still punishes latency and cost. Trimming and indexing still win.
- Style drift: Even with examples, tone wandered a bit on longer outputs. I keep reference snippets and ask the model to emulate those, works better than adjectives.
- “One-shot genius” is rare: The best results still come from steady scaffolding, clear objectives, small steps, and feedback. The model got better, but my system design mattered more.
GPT-5.4 — What Leaks Currently Suggest
I don’t have access to 5.4 as I write this. I’m going by public breadcrumbs, developer chatter, a couple of SDK references people spotted, and the general pattern of how these families evolve. Treat this as directional, not definitive. If you’re close to a launch window, double-check the model docs and recent release notes.
Fast mode references
There’s steady talk of a “fast” or “turbo” routing path in 5.4. My guess: a latency-first profile that relaxes a few quality guards, similar in spirit to the speed tiers we’ve seen in past families. If that lands, I’d expect:
- Snappier first token time.
- Slightly higher variance on exact formatting unless you use strict schemas.
- Better concurrency behavior for chat UIs and live agents.
If you care about perceived speed more than perfect phrasing, this could be the default.
Vision handling signals
A few hints point to stronger image understanding and more robust OCR on messy inputs (glare, skewed receipts, screenshots of code). I’d also expect steadier answers on charts and tables, especially if you provide a target schema. The practical upshot: less manual pre-processing. Today I often crop or enhance images before sending them. If 5.4 can absorb more of that chaos, one whole step disappears.
Coding workflow improvements
The chatter here centers on planning and multi-file edits. If true, 5.4 might:
- Propose clearer step plans before touching code.
- Keep function signatures consistent across files.
- Reduce off-by-one and import-path hiccups.
Even a small bump in reliability matters. In my tests with earlier versions, 70–80% of the “time lost” wasn’t logic, it was cleaning up confident but slightly wrong edits. If 5.4 trims that by even 10–15%, it’ll feel like more than an incremental release.

How Developers Choose Between GPT-5.x Versions
I don’t pick a version because a blog told me to. I run tiny, boring tests. Here’s the frame that’s held up for me.
Use-case mapping
- Content drafting with tone control: I lean newer (5.2/5.3) because style adherence improved slightly. I keep a small library of tone examples and point to them.
- Structured extraction: Whichever version gives me the highest schema adherence wins. Lately that’s been 5.2 or 5.3 with explicit response schemas. I still add a validator and a retry.
- Agents and tool workflows: 5.3 has been the steadiest on function arguments. If 5.4’s fast mode is real, I’ll A/B it for live agents that need quick back-and-forth more than perfect prose.
- Code assistance: I start with a short context and ask for a plan first. If the model can’t write a believable plan, it won’t write clean diffs. Adjacent 5.x versions differ just enough here to matter, test on your repo, not a toy file.
I track three numbers for each use case: successful first-pass rate, average latency, and the percentage of calls that need human cleanup. If a newer version doesn’t move at least one of those in the right direction, I don’t switch.
Cost vs capability tradeoffs
OpenAI pricing shifts, and I won’t guess at numbers here. The pattern, though, is stable:
- Newer models aren’t always more expensive, but they can be. I budget by tokens, not vibes.
- Long prompts compound cost. I strip boilerplate, compress examples, and reference external IDs where I can.
- If you batch work (summaries, extractions), the cheapest reliable version usually wins. If you’re user-facing, perceived speed often matters more than raw cost.
Two practical tips that saved me money and time:
- Golden sets: Keep 20–50 real prompts with known-good outputs. Re-run them when you consider a switch. No memory, just clean comparisons. You’ll see the trade-offs fast.
- Guardrails in code, not in prose: Schemas, validators, and small post-processors beat paragraphs of instructions.
Page Update Policy (continuously maintained)
I update this page when I see meaningful changes in GPT-5 models, usually after re-running my test set or when OpenAI’s docs change. I add a short note with a date, what I tested, and what moved (if anything). I link to official sources where I can and flag uncertainty when I can’t verify something.
If you’re dealing with similar constraints, it’s worth a look now and then, but don’t wait on me. The model docs are the source of truth. I keep my notes steady, not exhaustive.
A small observation to end on: the more I treat “GPT-5” as a living system instead of a single switch, the calmer my decisions get. The dropdown stops feeling like a test. It’s just a knob I turn with a reason.